 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023


Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022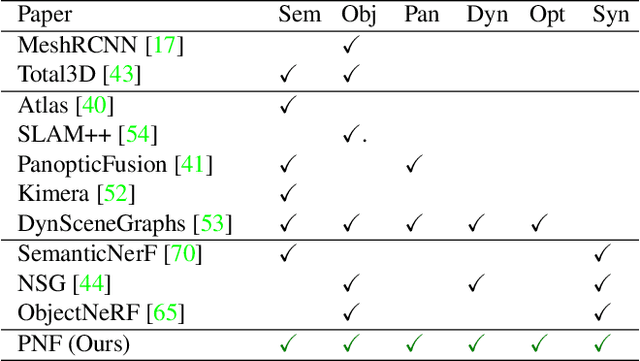
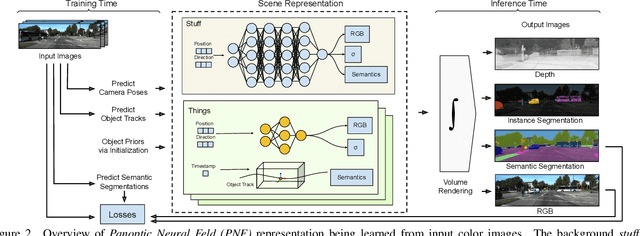
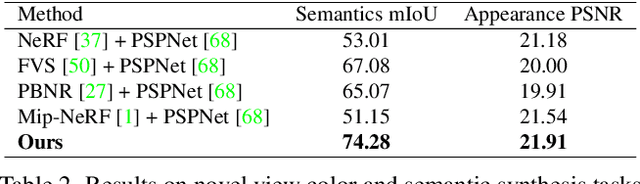
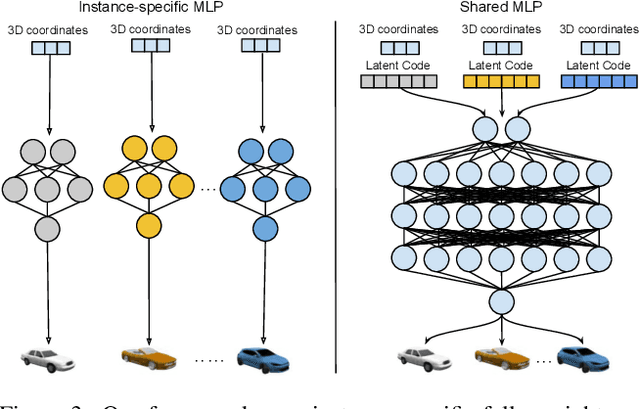
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021
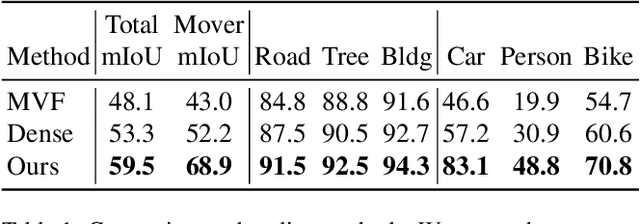
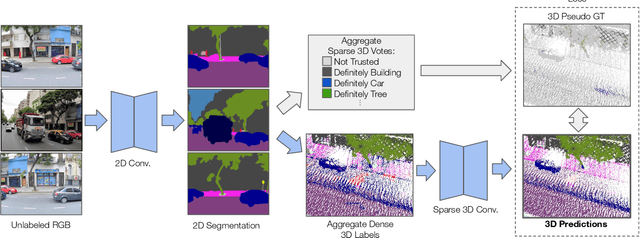
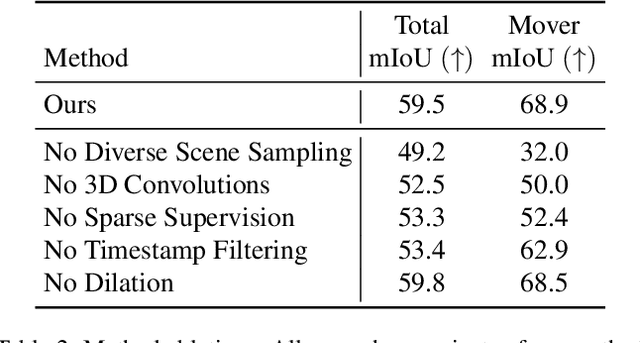
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
Dilated SpineNet for Semantic Segmentation
Mar 23, 2021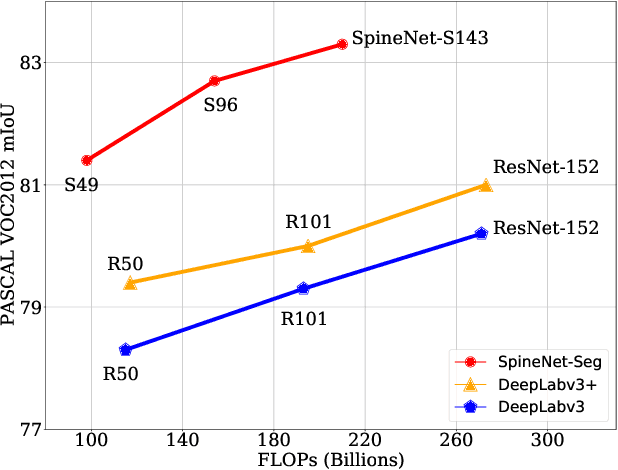
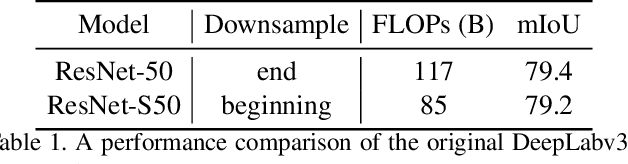

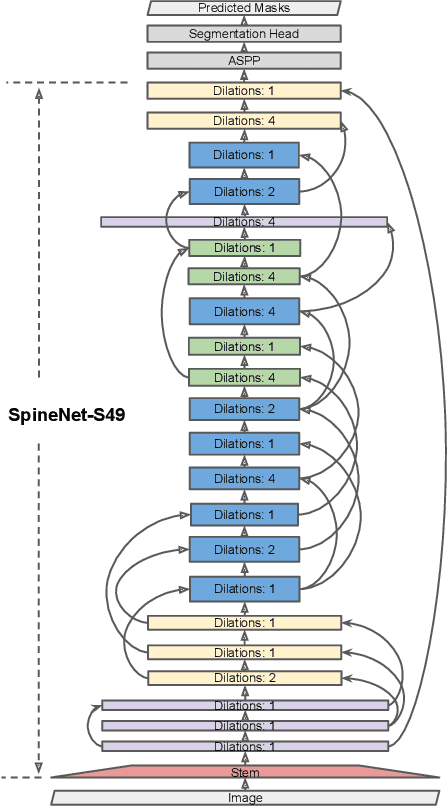
Scale-permuted networks have shown promising results on object bounding box detection and instance segmentation. Scale permutation and cross-scale fusion of features enable the network to capture multi-scale semantics while preserving spatial resolution. In this work, we evaluate this meta-architecture design on semantic segmentation - another vision task that benefits from high spatial resolution and multi-scale feature fusion at different network stages. By further leveraging dilated convolution operations, we propose SpineNet-Seg, a network discovered by NAS that is searched from the DeepLabv3 system. SpineNet-Seg is designed with a better scale-permuted network topology with customized dilation ratios per block on a semantic segmentation task. SpineNet-Seg models outperform the DeepLabv3/v3+ baselines at all model scales on multiple popular benchmarks in speed and accuracy. In particular, our SpineNet-S143+ model achieves the new state-of-the-art on the popular Cityscapes benchmark at 83.04% mIoU and attained strong performance on the PASCAL VOC2012 benchmark at 85.56% mIoU. SpineNet-Seg models also show promising results on a challenging Street View segmentation dataset. Code and checkpoints will be open-sourced.
Virtual Multi-view Fusion for 3D Semantic Segmentation
Jul 26, 2020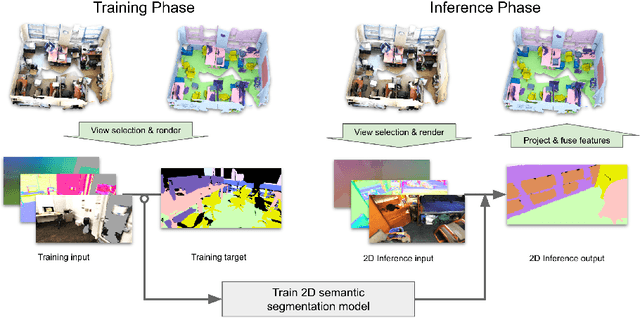
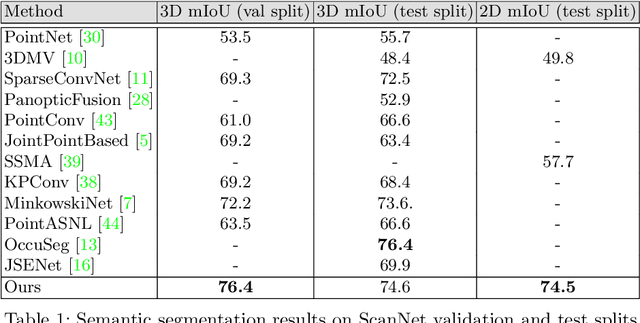
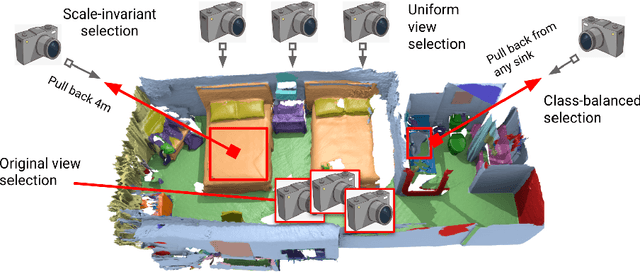
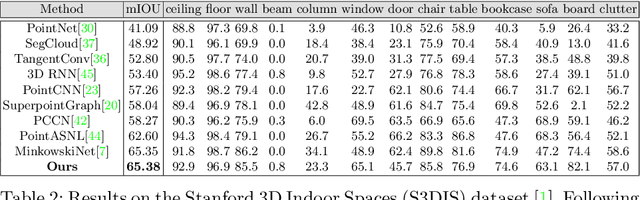
Semantic segmentation of 3D meshes is an important problem for 3D scene understanding. In this paper we revisit the classic multiview representation of 3D meshes and study several techniques that make them effective for 3D semantic segmentation of meshes. Given a 3D mesh reconstructed from RGBD sensors, our method effectively chooses different virtual views of the 3D mesh and renders multiple 2D channels for training an effective 2D semantic segmentation model. Features from multiple per view predictions are finally fused on 3D mesh vertices to predict mesh semantic segmentation labels. Using the large scale indoor 3D semantic segmentation benchmark of ScanNet, we show that our virtual views enable more effective training of 2D semantic segmentation networks than previous multiview approaches. When the 2D per pixel predictions are aggregated on 3D surfaces, our virtual multiview fusion method is able to achieve significantly better 3D semantic segmentation results compared to all prior multiview approaches and competitive with recent 3D convolution approaches.