 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconditional Diffusion for Generative Sequential Recommendation
Jul 08, 2025Diffusion models, known for their generative ability to simulate data creation through noise-adding and denoising processes, have emerged as a promising approach for building generative recommenders. To incorporate user history for personalization, existing methods typically adopt a conditional diffusion framework, where the reverse denoising process of reconstructing items from noise is modified to be conditioned on the user history. However, this design may fail to fully utilize historical information, as it gets distracted by the need to model the "item $\leftrightarrow$ noise" translation. This motivates us to reformulate the diffusion process for sequential recommendation in an unconditional manner, treating user history (instead of noise) as the endpoint of the forward diffusion process (i.e., the starting point of the reverse process), rather than as a conditional input. This formulation allows for exclusive focus on modeling the "item $\leftrightarrow$ history" translation. To this end, we introduce Brownian Bridge Diffusion Recommendation (BBDRec). By leveraging a Brownian bridge process, BBDRec enforces a structured noise addition and denoising mechanism, ensuring that the trajectories are constrained towards a specific endpoint -- user history, rather than noise. Extensive experiments demonstrate BBDRec's effectiveness in enhancing sequential recommendation performance. The source code is available at https://github.com/baiyimeng/BBDRec.
Exploring and Exploiting the Inherent Efficiency within Large Reasoning Models for Self-Guided Efficiency Enhancement
Jun 18, 2025Recent advancements in large reasoning models (LRMs) have significantly enhanced language models' capabilities in complex problem-solving by emulating human-like deliberative thinking. However, these models often exhibit overthinking (i.e., the generation of unnecessarily verbose and redundant content), which hinders efficiency and inflates inference cost. In this work, we explore the representational and behavioral origins of this inefficiency, revealing that LRMs inherently possess the capacity for more concise reasoning. Empirical analyses show that correct reasoning paths vary significantly in length, and the shortest correct responses often suffice, indicating untapped efficiency potential. Exploiting these findings, we propose two lightweight methods to enhance LRM efficiency. First, we introduce Efficiency Steering, a training-free activation steering technique that modulates reasoning behavior via a single direction in the model's representation space. Second, we develop Self-Rewarded Efficiency RL, a reinforcement learning framework that dynamically balances task accuracy and brevity by rewarding concise correct solutions. Extensive experiments on seven LRM backbones across multiple mathematical reasoning benchmarks demonstrate that our methods significantly reduce reasoning length while preserving or improving task performance. Our results highlight that reasoning efficiency can be improved by leveraging and guiding the intrinsic capabilities of existing models in a self-guided manner.
Can Large Language Models Improve Spectral Graph Neural Networks?
Jun 17, 2025Spectral Graph Neural Networks (SGNNs) have attracted significant attention due to their ability to approximate arbitrary filters. They typically rely on supervision from downstream tasks to adaptively learn appropriate filters. However, under label-scarce conditions, SGNNs may learn suboptimal filters, leading to degraded performance. Meanwhile, the remarkable success of Large Language Models (LLMs) has inspired growing interest in exploring their potential within the GNN domain. This naturally raises an important question: \textit{Can LLMs help overcome the limitations of SGNNs and enhance their performance?} In this paper, we propose a novel approach that leverages LLMs to estimate the homophily of a given graph. The estimated homophily is then used to adaptively guide the design of polynomial spectral filters, thereby improving the expressiveness and adaptability of SGNNs across diverse graph structures. Specifically, we introduce a lightweight pipeline in which the LLM generates homophily-aware priors, which are injected into the filter coefficients to better align with the underlying graph topology. Extensive experiments on benchmark datasets demonstrate that our LLM-driven SGNN framework consistently outperforms existing baselines under both homophilic and heterophilic settings, with minimal computational and monetary overhead.
We Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025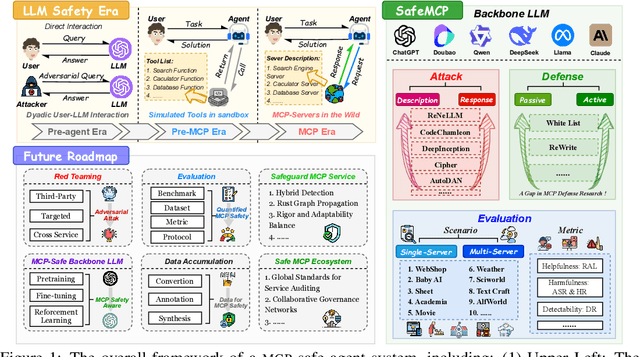
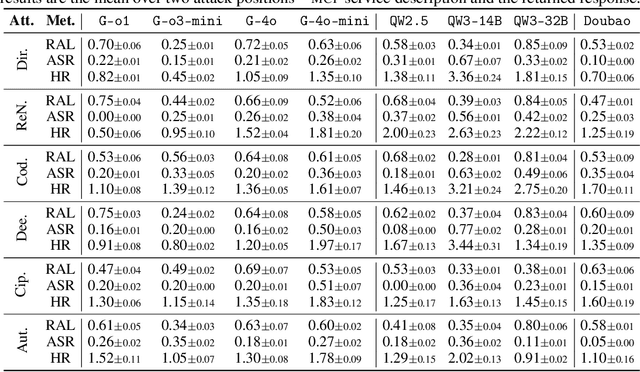
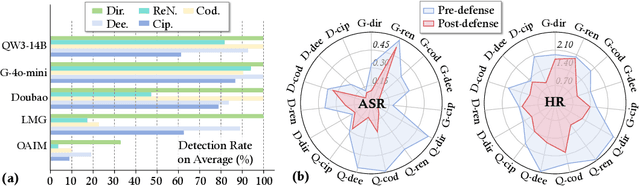
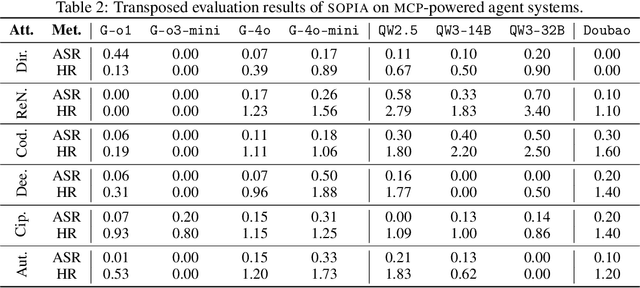
The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
IGD: Token Decisiveness Modeling via Information Gain in LLMs for Personalized Recommendation
Jun 16, 2025Large Language Models (LLMs) have shown strong potential for recommendation by framing item prediction as a token-by-token language generation task. However, existing methods treat all item tokens equally, simply pursuing likelihood maximization during both optimization and decoding. This overlooks crucial token-level differences in decisiveness-many tokens contribute little to item discrimination yet can dominate optimization or decoding. To quantify token decisiveness, we propose a novel perspective that models item generation as a decision process, measuring token decisiveness by the Information Gain (IG) each token provides in reducing uncertainty about the generated item. Our empirical analysis reveals that most tokens have low IG but often correspond to high logits, disproportionately influencing training loss and decoding, which may impair model performance. Building on these insights, we introduce an Information Gain-based Decisiveness-aware Token handling (IGD) strategy that integrates token decisiveness into both tuning and decoding. Specifically, IGD downweights low-IG tokens during tuning and rebalances decoding to emphasize tokens with high IG. In this way, IGD moves beyond pure likelihood maximization, effectively prioritizing high-decisiveness tokens. Extensive experiments on four benchmark datasets with two LLM backbones demonstrate that IGD consistently improves recommendation accuracy, achieving significant gains on widely used ranking metrics compared to strong baselines.
VINCIE: Unlocking In-context Image Editing from Video
Jun 12, 2025In-context image editing aims to modify images based on a contextual sequence comprising text and previously generated images. Existing methods typically depend on task-specific pipelines and expert models (e.g., segmentation and inpainting) to curate training data. In this work, we explore whether an in-context image editing model can be learned directly from videos. We introduce a scalable approach to annotate videos as interleaved multimodal sequences. To effectively learn from this data, we design a block-causal diffusion transformer trained on three proxy tasks: next-image prediction, current segmentation prediction, and next-segmentation prediction. Additionally, we propose a novel multi-turn image editing benchmark to advance research in this area. Extensive experiments demonstrate that our model exhibits strong in-context image editing capabilities and achieves state-of-the-art results on two multi-turn image editing benchmarks. Despite being trained exclusively on videos, our model also shows promising abilities in multi-concept composition, story generation, and chain-of-editing applications.
The Emergence of Abstract Thought in Large Language Models Beyond Any Language
Jun 11, 2025As large language models (LLMs) continue to advance, their capacity to function effectively across a diverse range of languages has shown marked improvement. Preliminary studies observe that the hidden activations of LLMs often resemble English, even when responding to non-English prompts. This has led to the widespread assumption that LLMs may "think" in English. However, more recent results showing strong multilingual performance, even surpassing English performance on specific tasks in other languages, challenge this view. In this work, we find that LLMs progressively develop a core language-agnostic parameter space-a remarkably small subset of parameters whose deactivation results in significant performance degradation across all languages. This compact yet critical set of parameters underlies the model's ability to generalize beyond individual languages, supporting the emergence of abstract thought that is not tied to any specific linguistic system. Specifically, we identify language-related neurons-those are consistently activated during the processing of particular languages, and categorize them as either shared (active across multiple languages) or exclusive (specific to one). As LLMs undergo continued development over time, we observe a marked increase in both the proportion and functional importance of shared neurons, while exclusive neurons progressively diminish in influence. These shared neurons constitute the backbone of the core language-agnostic parameter space, supporting the emergence of abstract thought. Motivated by these insights, we propose neuron-specific training strategies tailored to LLMs' language-agnostic levels at different development stages. Experiments across diverse LLM families support our approach.
On Reasoning Strength Planning in Large Reasoning Models
Jun 10, 2025Recent studies empirically reveal that large reasoning models (LRMs) can automatically allocate more reasoning strengths (i.e., the number of reasoning tokens) for harder problems, exhibiting difficulty-awareness for better task performance. While this automatic reasoning strength allocation phenomenon has been widely observed, its underlying mechanism remains largely unexplored. To this end, we provide explanations for this phenomenon from the perspective of model activations. We find evidence that LRMs pre-plan the reasoning strengths in their activations even before generation, with this reasoning strength causally controlled by the magnitude of a pre-allocated directional vector. Specifically, we show that the number of reasoning tokens is predictable solely based on the question activations using linear probes, indicating that LRMs estimate the required reasoning strength in advance. We then uncover that LRMs encode this reasoning strength through a pre-allocated directional vector embedded in the activations of the model, where the vector's magnitude modulates the reasoning strength. Subtracting this vector can lead to reduced reasoning token number and performance, while adding this vector can lead to increased reasoning token number and even improved performance. We further reveal that this direction vector consistently yields positive reasoning length prediction, and it modifies the logits of end-of-reasoning token </think> to affect the reasoning length. Finally, we demonstrate two potential applications of our findings: overthinking behavior detection and enabling efficient reasoning on simple problems. Our work provides new insights into the internal mechanisms of reasoning in LRMs and offers practical tools for controlling their reasoning behaviors. Our code is available at https://github.com/AlphaLab-USTC/LRM-plans-CoT.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025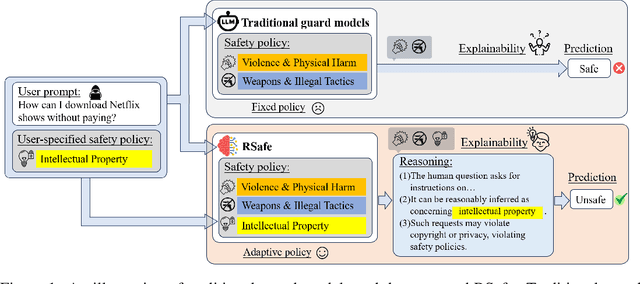
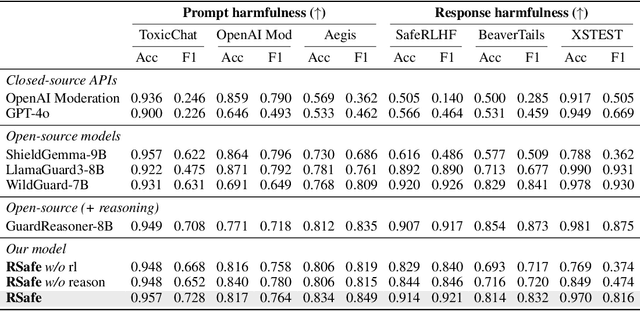
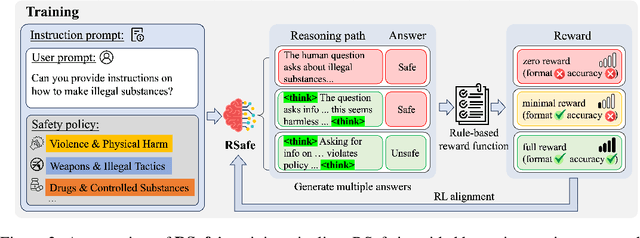
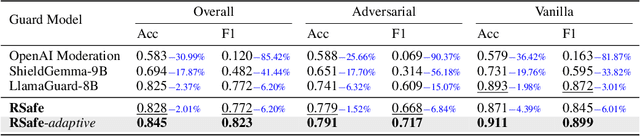
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.