 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Brains, Giant Impact: Uncovering the Keystone Neurons of LLM with Just a Few Prompts
May 27, 2026Large language models (LLMs) display strong comprehensive abilities, yet the internal mechanisms that support these behaviors remain insufficiently understood. In this work, we show that across a wide range of open-weight Transformers, a subset of neurons remains consistently highly activated during inference across tasks of multiple capability dimensions. By probing along the cross-task activation strength, an extremely sparse subset is isolated, whose removal causes a collapse in model behavior, which we term keystone neurons. Our analysis reveals that keystone neurons are a stable and intrinsic neuron subset of the model that is largely established during pretraining. The parameters associated with these neurons are tightly calibrated during the training process, and their precise values are critical for the capabilities of the model. Building on these insights, we propose a supervised fine-tuning approach that updates only keystone neurons, achieving task gains comparable to or even better than full-parameter fine-tuning while better preserving performance in other capability dimensions, despite modifying a much smaller number of parameters.
Understanding Multilingualism in Mixture-of-Experts LLMs: Routing Mechanism, Expert Specialization, and Layerwise Steering
Jan 20, 2026Mixture-of-Experts (MoE) architectures have shown strong multilingual capabilities, yet the internal mechanisms underlying performance gains and cross-language differences remain insufficiently understood. In this work, we conduct a systematic analysis of MoE models, examining routing behavior and expert specialization across languages and network depth. Our analysis reveals that multilingual processing in MoE models is highly structured: routing aligns with linguistic families, expert utilization follows a clear layerwise pattern, and high-resource languages rely on shared experts while low-resource languages depend more on language-exclusive experts despite weaker performance. Layerwise interventions further show that early and late MoE layers support language-specific processing, whereas middle layers serve as language-agnostic capacity hubs. Building on these insights, we propose a routing-guided steering method that adaptively guides routing behavior in middle layers toward shared experts associated with dominant languages at inference time, leading to consistent multilingual performance improvements, particularly for linguistically related language pairs. Our code is available at https://github.com/conctsai/Multilingualism-in-Mixture-of-Experts-LLMs.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025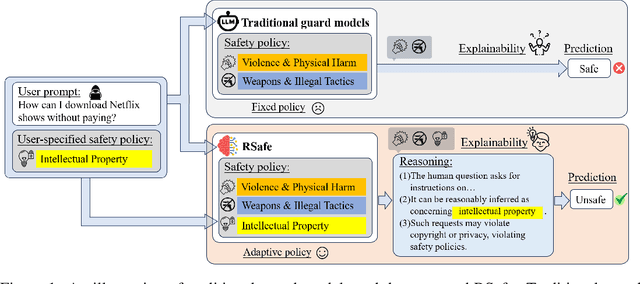
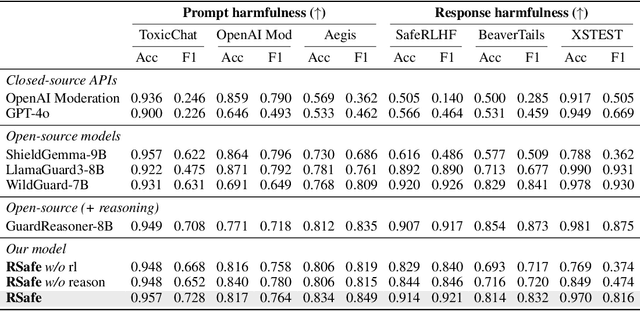
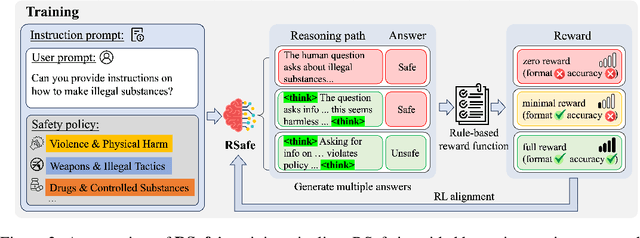
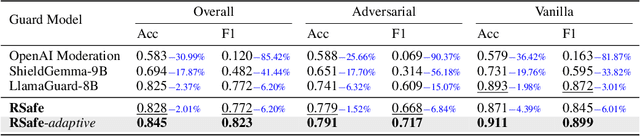
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.