 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust-In-Time Reinforcement Learning: Continual Learning in LLM Agents Without Gradient Updates
Jan 26, 2026While Large Language Model (LLM) agents excel at general tasks, they inherently struggle with continual adaptation due to the frozen weights after deployment. Conventional reinforcement learning (RL) offers a solution but incurs prohibitive computational costs and the risk of catastrophic forgetting. We introduce Just-In-Time Reinforcement Learning (JitRL), a training-free framework that enables test-time policy optimization without any gradient updates. JitRL maintains a dynamic, non-parametric memory of experiences and retrieves relevant trajectories to estimate action advantages on-the-fly. These estimates are then used to directly modulate the LLM's output logits. We theoretically prove that this additive update rule is the exact closed-form solution to the KL-constrained policy optimization objective. Extensive experiments on WebArena and Jericho demonstrate that JitRL establishes a new state-of-the-art among training-free methods. Crucially, JitRL outperforms the performance of computationally expensive fine-tuning methods (e.g., WebRL) while reducing monetary costs by over 30 times, offering a scalable path for continual learning agents. The code is available at https://github.com/liushiliushi/JitRL.
Enhancing Multi-Agent Debate System Performance via Confidence Expression
Sep 17, 2025Generative Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks. Recent research has introduced Multi-Agent Debate (MAD) systems, which leverage multiple LLMs to simulate human debate and thereby improve task performance. However, while some LLMs may possess superior knowledge or reasoning capabilities for specific tasks, they often struggle to clearly communicate this advantage during debates, in part due to a lack of confidence expression. Moreover, inappropriate confidence expression can cause agents in MAD systems to either stubbornly maintain incorrect beliefs or converge prematurely on suboptimal answers, ultimately reducing debate effectiveness and overall system performance. To address these challenges, we propose incorporating confidence expression into MAD systems to allow LLMs to explicitly communicate their confidence levels. To validate this approach, we develop ConfMAD, a MAD framework that integrates confidence expression throughout the debate process. Experimental results demonstrate the effectiveness of our method, and we further analyze how confidence influences debate dynamics, offering insights into the design of confidence-aware MAD systems.
IGD: Token Decisiveness Modeling via Information Gain in LLMs for Personalized Recommendation
Jun 16, 2025Large Language Models (LLMs) have shown strong potential for recommendation by framing item prediction as a token-by-token language generation task. However, existing methods treat all item tokens equally, simply pursuing likelihood maximization during both optimization and decoding. This overlooks crucial token-level differences in decisiveness-many tokens contribute little to item discrimination yet can dominate optimization or decoding. To quantify token decisiveness, we propose a novel perspective that models item generation as a decision process, measuring token decisiveness by the Information Gain (IG) each token provides in reducing uncertainty about the generated item. Our empirical analysis reveals that most tokens have low IG but often correspond to high logits, disproportionately influencing training loss and decoding, which may impair model performance. Building on these insights, we introduce an Information Gain-based Decisiveness-aware Token handling (IGD) strategy that integrates token decisiveness into both tuning and decoding. Specifically, IGD downweights low-IG tokens during tuning and rebalances decoding to emphasize tokens with high IG. In this way, IGD moves beyond pure likelihood maximization, effectively prioritizing high-decisiveness tokens. Extensive experiments on four benchmark datasets with two LLM backbones demonstrate that IGD consistently improves recommendation accuracy, achieving significant gains on widely used ranking metrics compared to strong baselines.
Improving Phishing Email Detection Performance of Small Large Language Models
Apr 29, 2025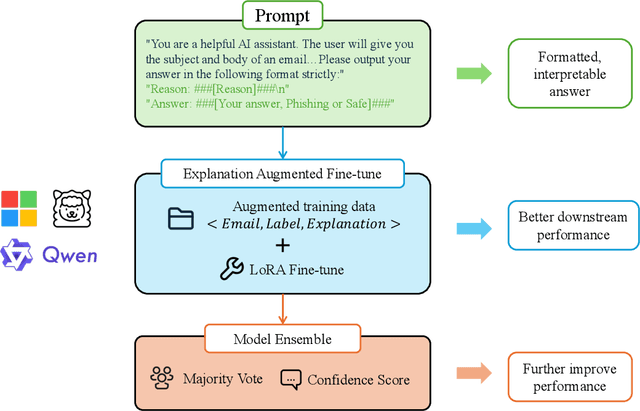
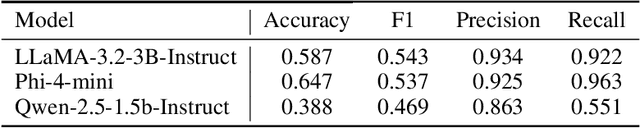
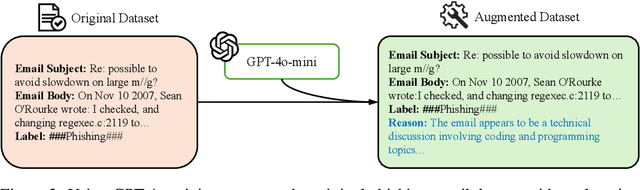
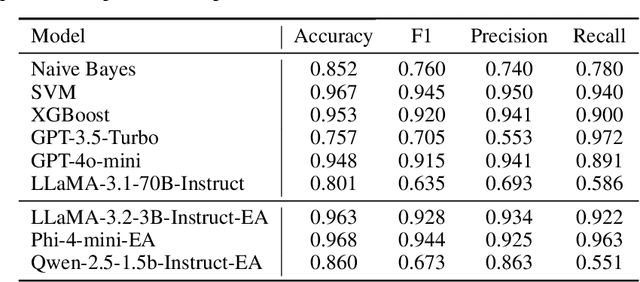
Large language models(LLMs) have demonstrated remarkable performance on many natural language processing(NLP) tasks and have been employed in phishing email detection research. However, in current studies, well-performing LLMs typically contain billions or even tens of billions of parameters, requiring enormous computational resources. To reduce computational costs, we investigated the effectiveness of small-parameter LLMs for phishing email detection. These LLMs have around 3 billion parameters and can run on consumer-grade GPUs. However, small LLMs often perform poorly in phishing email detection task. To address these issues, we designed a set of methods including Prompt Engineering, Explanation Augmented Fine-tuning, and Model Ensemble to improve phishing email detection capabilities of small LLMs. We validated the effectiveness of our approach through experiments, significantly improving accuracy on the SpamAssassin dataset from around 0.5 for baseline models like Qwen2.5-1.5B-Instruct to 0.976.
AutoP2C: An LLM-Based Agent Framework for Code Repository Generation from Multimodal Content in Academic Papers
Apr 28, 2025



Machine Learning (ML) research is spread through academic papers featuring rich multimodal content, including text, diagrams, and tabular results. However, translating these multimodal elements into executable code remains a challenging and time-consuming process that requires substantial ML expertise. We introduce ``Paper-to-Code'' (P2C), a novel task that transforms the multimodal content of scientific publications into fully executable code repositories, which extends beyond the existing formulation of code generation that merely converts textual descriptions into isolated code snippets. To automate the P2C process, we propose AutoP2C, a multi-agent framework based on large language models that processes both textual and visual content from research papers to generate complete code repositories. Specifically, AutoP2C contains four stages: (1) repository blueprint extraction from established codebases, (2) multimodal content parsing that integrates information from text, equations, and figures, (3) hierarchical task decomposition for structured code generation, and (4) iterative feedback-driven debugging to ensure functionality and performance. Evaluation on a benchmark of eight research papers demonstrates the effectiveness of AutoP2C, which can successfully generate executable code repositories for all eight papers, while OpenAI-o1 or DeepSeek-R1 can only produce runnable code for one paper. The code is available at https://github.com/shoushouyu/Automated-Paper-to-Code.