 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRig: Self-Supervised Pose-Invariant Rigging from Mesh Sequences
Feb 13, 2026State-of-the-art rigging methods assume a canonical rest pose--an assumption that fails for sequential data (e.g., animal motion capture or AIGC/video-derived mesh sequences) that lack the T-pose. Applied frame-by-frame, these methods are not pose-invariant and produce topological inconsistencies across frames. Thus We propose SPRig, a general fine-tuning framework that enforces cross-frame consistency losses to learn pose-invariant rigs on top of existing models. We validate our approach on rigging using a new permutation-invariant stability protocol. Experiments demonstrate SOTA temporal stability: our method produces coherent rigs from challenging sequences and dramatically reduces the artifacts that plague baseline methods. The code will be released publicly upon acceptance.
AgentNoiseBench: Benchmarking Robustness of Tool-Using LLM Agents Under Noisy Condition
Feb 11, 2026Recent advances in large language models have enabled LLM-based agents to achieve strong performance on a variety of benchmarks. However, their performance in real-world deployments often that observed on benchmark settings, especially in complex and imperfect environments. This discrepancy largely arises because prevailing training and evaluation paradigms are typically built on idealized assumptions, overlooking the inherent stochasticity and noise present in real-world interactions. To bridge this gap, we introduce AgentNoiseBench, a framework for systematically evaluating the robustness of agentic models under noisy environments. We first conduct an in-depth analysis of biases and uncertainties in real-world scenarios and categorize environmental noise into two primary types: user-noise and tool-noise. Building on this analysis, we develop an automated pipeline that injects controllable noise into existing agent-centric benchmarks while preserving task solvability. Leveraging this pipeline, we perform extensive evaluations across a wide range of models with diverse architectures and parameter scales. Our results reveal consistent performance variations under different noise conditions, highlighting the sensitivity of current agentic models to realistic environmental perturbations.
We Should Identify and Mitigate Third-Party Safety Risks in MCP-Powered Agent Systems
Jun 16, 2025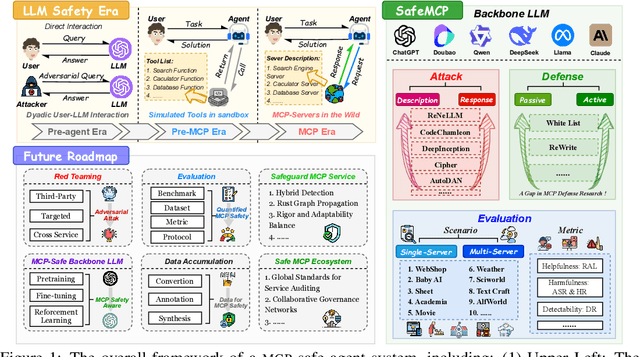
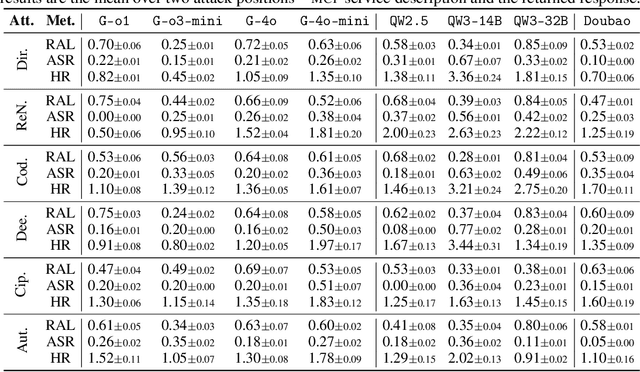
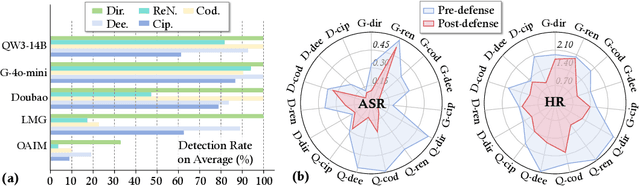
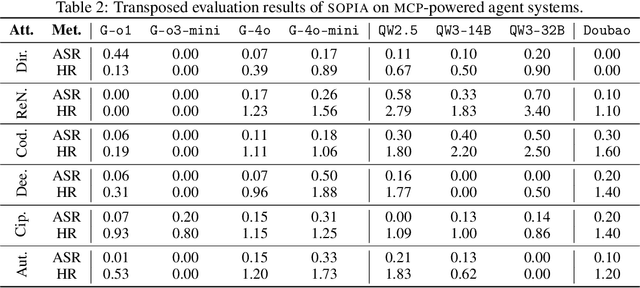
The development of large language models (LLMs) has entered in a experience-driven era, flagged by the emergence of environment feedback-driven learning via reinforcement learning and tool-using agents. This encourages the emergenece of model context protocol (MCP), which defines the standard on how should a LLM interact with external services, such as \api and data. However, as MCP becomes the de facto standard for LLM agent systems, it also introduces new safety risks. In particular, MCP introduces third-party services, which are not controlled by the LLM developers, into the agent systems. These third-party MCP services provider are potentially malicious and have the economic incentives to exploit vulnerabilities and sabotage user-agent interactions. In this position paper, we advocate the research community in LLM safety to pay close attention to the new safety risks issues introduced by MCP, and develop new techniques to build safe MCP-powered agent systems. To establish our position, we argue with three key parts. (1) We first construct \framework, a controlled framework to examine safety issues in MCP-powered agent systems. (2) We then conduct a series of pilot experiments to demonstrate the safety risks in MCP-powered agent systems is a real threat and its defense is not trivial. (3) Finally, we give our outlook by showing a roadmap to build safe MCP-powered agent systems. In particular, we would call for researchers to persue the following research directions: red teaming, MCP safe LLM development, MCP safety evaluation, MCP safety data accumulation, MCP service safeguard, and MCP safe ecosystem construction. We hope this position paper can raise the awareness of the research community in MCP safety and encourage more researchers to join this important research direction. Our code is available at https://github.com/littlelittlenine/SafeMCP.git.
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
SafeMLRM: Demystifying Safety in Multi-modal Large Reasoning Models
Apr 09, 2025The rapid advancement of multi-modal large reasoning models (MLRMs) -- enhanced versions of multimodal language models (MLLMs) equipped with reasoning capabilities -- has revolutionized diverse applications. However, their safety implications remain underexplored. While prior work has exposed critical vulnerabilities in unimodal reasoning models, MLRMs introduce distinct risks from cross-modal reasoning pathways. This work presents the first systematic safety analysis of MLRMs through large-scale empirical studies comparing MLRMs with their base MLLMs. Our experiments reveal three critical findings: (1) The Reasoning Tax: Acquiring reasoning capabilities catastrophically degrades inherited safety alignment. MLRMs exhibit 37.44% higher jailbreaking success rates than base MLLMs under adversarial attacks. (2) Safety Blind Spots: While safety degradation is pervasive, certain scenarios (e.g., Illegal Activity) suffer 25 times higher attack rates -- far exceeding the average 3.4 times increase, revealing scenario-specific vulnerabilities with alarming cross-model and datasets consistency. (3) Emergent Self-Correction: Despite tight reasoning-answer safety coupling, MLRMs demonstrate nascent self-correction -- 16.9% of jailbroken reasoning steps are overridden by safe answers, hinting at intrinsic safeguards. These findings underscore the urgency of scenario-aware safety auditing and mechanisms to amplify MLRMs' self-correction potential. To catalyze research, we open-source OpenSafeMLRM, the first toolkit for MLRM safety evaluation, providing unified interface for mainstream models, datasets, and jailbreaking methods. Our work calls for immediate efforts to harden reasoning-augmented AI, ensuring its transformative potential aligns with ethical safeguards.
ACE: Concept Editing in Diffusion Models without Performance Degradation
Mar 11, 2025



Diffusion-based text-to-image models have demonstrated remarkable capabilities in generating realistic images, but they raise societal and ethical concerns, such as the creation of unsafe content. While concept editing is proposed to address these issues, they often struggle to balance the removal of unsafe concept with maintaining the model's general genera-tive capabilities. In this work, we propose ACE, a new editing method that enhances concept editing in diffusion models. ACE introduces a novel cross null-space projection approach to precisely erase unsafe concept while maintaining the model's ability to generate high-quality, semantically consistent images. Extensive experiments demonstrate that ACE significantly outperforms the advancing baselines,improving semantic consistency by 24.56% and image generation quality by 34.82% on average with only 1% of the time cost. These results highlight the practical utility of concept editing by mitigating its potential risks, paving the way for broader applications in the field. Code is avaliable at https://github.com/littlelittlenine/ACE-zero.git
MixDec Sampling: A Soft Link-based Sampling Method of Graph Neural Network for Recommendation
Feb 12, 2025Graph neural networks have been widely used in recent recommender systems, where negative sampling plays an important role. Existing negative sampling methods restrict the relationship between nodes as either hard positive pairs or hard negative pairs. This leads to the loss of structural information, and lacks the mechanism to generate positive pairs for nodes with few neighbors. To overcome limitations, we propose a novel soft link-based sampling method, namely MixDec Sampling, which consists of Mixup Sampling module and Decay Sampling module. The Mixup Sampling augments node features by synthesizing new nodes and soft links, which provides sufficient number of samples for nodes with few neighbors. The Decay Sampling strengthens the digestion of graph structure information by generating soft links for node embedding learning. To the best of our knowledge, we are the first to model sampling relationships between nodes by soft links in GNN-based recommender systems. Extensive experiments demonstrate that the proposed MixDec Sampling can significantly and consistently improve the recommendation performance of several representative GNN-based models on various recommendation benchmarks.
Neuron-Level Sequential Editing for Large Language Models
Oct 05, 2024



This work explores sequential model editing in large language models (LLMs), a critical task that involves modifying internal knowledge within LLMs continuously through multi-round editing, each incorporating updates or corrections to adjust the model outputs without the need for costly retraining. Existing model editing methods, especially those that alter model parameters, typically focus on single-round editing and often face significant challenges in sequential model editing-most notably issues of model forgetting and failure. To address these challenges, we introduce a new model editing method, namely \textbf{N}euron-level \textbf{S}equential \textbf{E}diting (NSE), tailored for supporting sequential model editing. Specifically, we optimize the target layer's hidden states using the model's original weights to prevent model failure. Furthermore, we iteratively select neurons in multiple layers for editing based on their activation values to mitigate model forgetting. Our empirical experiments demonstrate that NSE significantly outperforms current modifying parameters model editing methods, marking a substantial advancement in the field of sequential model editing. Our code is released on \url{https://github.com/jianghoucheng/NSE}.