 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025



Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
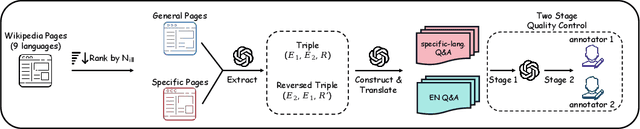


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
TACO: Rethinking Semantic Communications with Task Adaptation and Context Embedding
May 16, 2025



Recent advancements in generative artificial intelligence have introduced groundbreaking approaches to innovating next-generation semantic communication, which prioritizes conveying the meaning of a message rather than merely transmitting raw data. A fundamental challenge in semantic communication lies in accurately identifying and extracting the most critical semantic information while adapting to downstream tasks without degrading performance, particularly when the objective at the receiver may evolve over time. To enable flexible adaptation to multiple tasks at the receiver, this work introduces a novel semantic communication framework, which is capable of jointly capturing task-specific information to enhance downstream task performance and contextual information. Through rigorous experiments on popular image datasets and computer vision tasks, our framework shows promising improvement compared to existing work, including superior performance in downstream tasks, better generalizability, ultra-high bandwidth efficiency, and low reconstruction latency.
Task-Adaptive Semantic Communications with Controllable Diffusion-based Data Regeneration
May 12, 2025Semantic communications represent a new paradigm of next-generation networking that shifts bit-wise data delivery to conveying the semantic meanings for bandwidth efficiency. To effectively accommodate various potential downstream tasks at the receiver side, one should adaptively convey the most critical semantic information. This work presents a novel task-adaptive semantic communication framework based on diffusion models that is capable of dynamically adjusting the semantic message delivery according to various downstream tasks. Specifically, we initialize the transmission of a deep-compressed general semantic representation from the transmitter to enable diffusion-based coarse data reconstruction at the receiver. The receiver identifies the task-specific demands and generates textual prompts as feedback. Integrated with the attention mechanism, the transmitter updates the semantic transmission with more details to better align with the objectives of the intended receivers. Our test results demonstrate the efficacy of the proposed method in adaptively preserving critical task-relevant information for semantic communications while preserving high compression efficiency.
Mixture-of-Experts for Distributed Edge Computing with Channel-Aware Gating Function
Apr 01, 2025In a distributed mixture-of-experts (MoE) system, a server collaborates with multiple specialized expert clients to perform inference. The server extracts features from input data and dynamically selects experts based on their areas of specialization to produce the final output. Although MoE models are widely valued for their flexibility and performance benefits, adapting distributed MoEs to operate effectively in wireless networks has remained unexplored. In this work, we introduce a novel channel-aware gating function for wireless distributed MoE, which incorporates channel conditions into the MoE gating mechanism. To train the channel-aware gating, we simulate various signal-to-noise ratios (SNRs) for each expert's communication channel and add noise to the features distributed to the experts based on these SNRs. The gating function then utilizes both features and SNRs to optimize expert selection. Unlike conventional MoE models which solely consider the alignment of features with the specializations of experts, our approach additionally considers the impact of channel conditions on expert performance. Experimental results demonstrate that the proposed channel-aware gating scheme outperforms traditional MoE models.
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
Mar 27, 2025



We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .
Task-Driven Semantic Quantization and Imitation Learning for Goal-Oriented Communications
Feb 25, 2025



Semantic communication marks a new paradigm shift from bit-wise data transmission to semantic information delivery for the purpose of bandwidth reduction. To more effectively carry out specialized downstream tasks at the receiver end, it is crucial to define the most critical semantic message in the data based on the task or goal-oriented features. In this work, we propose a novel goal-oriented communication (GO-COM) framework, namely Goal-Oriented Semantic Variational Autoencoder (GOS-VAE), by focusing on the extraction of the semantics vital to the downstream tasks. Specifically, we adopt a Vector Quantized Variational Autoencoder (VQ-VAE) to compress media data at the transmitter side. Instead of targeting the pixel-wise image data reconstruction, we measure the quality-of-service at the receiver end based on a pre-defined task-incentivized model. Moreover, to capture the relevant semantic features in the data reconstruction, imitation learning is adopted to measure the data regeneration quality in terms of goal-oriented semantics. Our experimental results demonstrate the power of imitation learning in characterizing goal-oriented semantics and bandwidth efficiency of our proposed GOS-VAE.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.