 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose as a Modality: A Psychology-Inspired Network for Personality Recognition with a New Multimodal Dataset
Mar 17, 2025In recent years, predicting Big Five personality traits from multimodal data has received significant attention in artificial intelligence (AI). However, existing computational models often fail to achieve satisfactory performance. Psychological research has shown a strong correlation between pose and personality traits, yet previous research has largely ignored pose data in computational models. To address this gap, we develop a novel multimodal dataset that incorporates full-body pose data. The dataset includes video recordings of 287 participants completing a virtual interview with 36 questions, along with self-reported Big Five personality scores as labels. To effectively utilize this multimodal data, we introduce the Psychology-Inspired Network (PINet), which consists of three key modules: Multimodal Feature Awareness (MFA), Multimodal Feature Interaction (MFI), and Psychology-Informed Modality Correlation Loss (PIMC Loss). The MFA module leverages the Vision Mamba Block to capture comprehensive visual features related to personality, while the MFI module efficiently fuses the multimodal features. The PIMC Loss, grounded in psychological theory, guides the model to emphasize different modalities for different personality dimensions. Experimental results show that the PINet outperforms several state-of-the-art baseline models. Furthermore, the three modules of PINet contribute almost equally to the model's overall performance. Incorporating pose data significantly enhances the model's performance, with the pose modality ranking mid-level in importance among the five modalities. These findings address the existing gap in personality-related datasets that lack full-body pose data and provide a new approach for improving the accuracy of personality prediction models, highlighting the importance of integrating psychological insights into AI frameworks.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
FB-Bench: A Fine-Grained Multi-Task Benchmark for Evaluating LLMs' Responsiveness to Human Feedback
Oct 12, 2024



Human feedback is crucial in the interactions between humans and Large Language Models (LLMs). However, existing research primarily focuses on benchmarking LLMs in single-turn dialogues. Even in benchmarks designed for multi-turn dialogues, the user inputs are often independent, neglecting the nuanced and complex nature of human feedback within real-world usage scenarios. To fill this research gap, we introduce FB-Bench, a fine-grained, multi-task benchmark designed to evaluate LLMs' responsiveness to human feedback in real-world usage scenarios. Drawing from the two main interaction scenarios, FB-Bench comprises 734 meticulously curated samples, encompassing eight task types, five deficiency types of response, and nine feedback types. We extensively evaluate a broad array of popular LLMs, revealing significant variations in their performance across different interaction scenarios. Further analysis indicates that task, human feedback, and deficiencies of previous responses can also significantly impact LLMs' responsiveness. Our findings underscore both the strengths and limitations of current models, providing valuable insights and directions for future research. Both the toolkits and the dataset of FB-Bench are available at https://github.com/PKU-Baichuan-MLSystemLab/FB-Bench.
PAS: Data-Efficient Plug-and-Play Prompt Augmentation System
Jul 11, 2024



In recent years, the rise of Large Language Models (LLMs) has spurred a growing demand for plug-and-play AI systems. Among the various AI techniques, prompt engineering stands out as particularly significant. However, users often face challenges in writing prompts due to the steep learning curve and significant time investment, and existing automatic prompt engineering (APE) models can be difficult to use. To address this issue, we propose PAS, an LLM-based plug-and-play APE system. PAS utilizes LLMs trained on high-quality, automatically generated prompt complementary datasets, resulting in exceptional performance. In comprehensive benchmarks, PAS achieves state-of-the-art (SoTA) results compared to previous APE models, with an average improvement of 6.09 points. Moreover, PAS is highly efficient, achieving SoTA performance with only 9000 data points. Additionally, PAS can autonomously generate prompt augmentation data without requiring additional human labor. Its flexibility also allows it to be compatible with all existing LLMs and applicable to a wide range of tasks. PAS excels in human evaluations, underscoring its suitability as a plug-in for users. This combination of high performance, efficiency, and flexibility makes PAS a valuable system for enhancing the usability and effectiveness of LLMs through improved prompt engineering.
T-Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Jan 15, 2024



Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool-utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability. The benchmark will be available at https://github.com/open-compass/T-Eval.
MultiModal-GPT: A Vision and Language Model for Dialogue with Humans
May 09, 2023



We present a vision and language model named MultiModal-GPT to conduct multi-round dialogue with humans. MultiModal-GPT can follow various instructions from humans, such as generating a detailed caption, counting the number of interested objects, and answering general questions from users. MultiModal-GPT is parameter-efficiently fine-tuned from OpenFlamingo, with Low-rank Adapter (LoRA) added both in the cross-attention part and the self-attention part of the language model. We first construct instruction templates with vision and language data for multi-modality instruction tuning to make the model understand and follow human instructions. We find the quality of training data is vital for the dialogue performance, where few data containing short answers can lead the model to respond shortly to any instructions. To further enhance the ability to chat with humans of the MultiModal-GPT, we utilize language-only instruction-following data to train the MultiModal-GPT jointly. The joint training of language-only and visual-language instructions with the \emph{same} instruction template effectively improves dialogue performance. Various demos show the ability of continuous dialogue of MultiModal-GPT with humans. Code, dataset, and demo are at https://github.com/open-mmlab/Multimodal-GPT
Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
Sep 16, 2022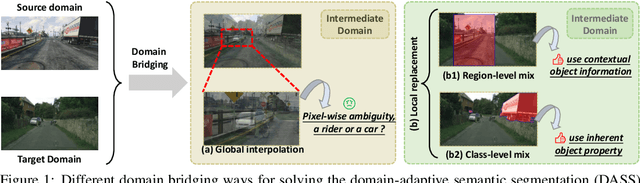

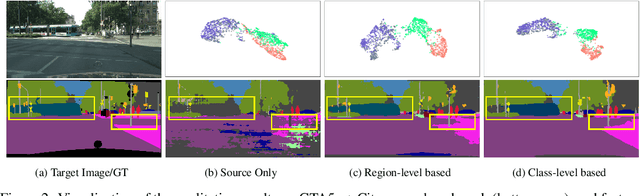
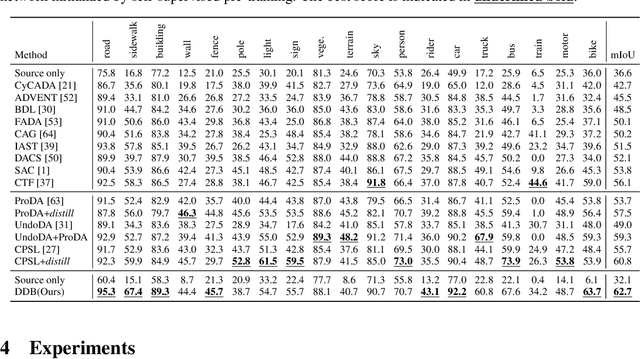
In unsupervised domain adaptation (UDA), directly adapting from the source to the target domain usually suffers significant discrepancies and leads to insufficient alignment. Thus, many UDA works attempt to vanish the domain gap gradually and softly via various intermediate spaces, dubbed domain bridging (DB). However, for dense prediction tasks such as domain adaptive semantic segmentation (DASS), existing solutions have mostly relied on rough style transfer and how to elegantly bridge domains is still under-explored. In this work, we resort to data mixing to establish a deliberated domain bridging (DDB) for DASS, through which the joint distributions of source and target domains are aligned and interacted with each in the intermediate space. At the heart of DDB lies a dual-path domain bridging step for generating two intermediate domains using the coarse-wise and the fine-wise data mixing techniques, alongside a cross-path knowledge distillation step for taking two complementary models trained on generated intermediate samples as 'teachers' to develop a superior 'student' in a multi-teacher distillation manner. These two optimization steps work in an alternating way and reinforce each other to give rise to DDB with strong adaptation power. Extensive experiments on adaptive segmentation tasks with different settings demonstrate that our DDB significantly outperforms state-of-the-art methods. Code is available at https://github.com/xiaoachen98/DDB.git.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022
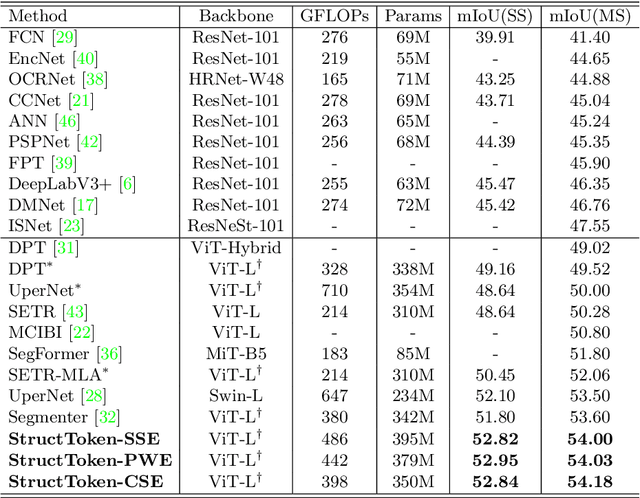
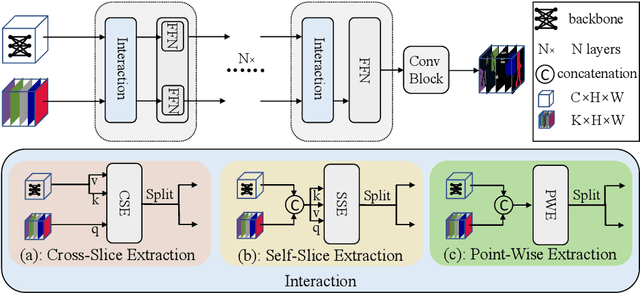
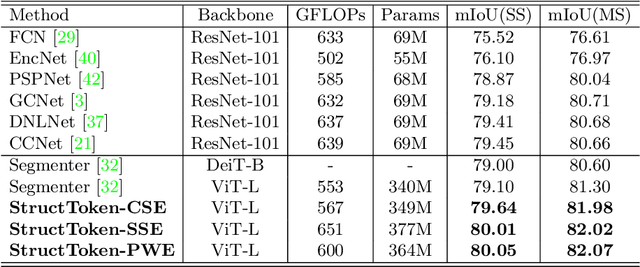
In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.