 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Text Block Detection towards Scene Text Understanding
Jul 26, 2022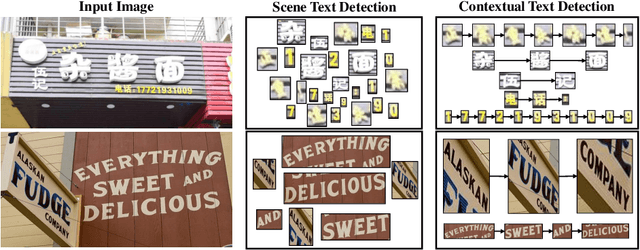

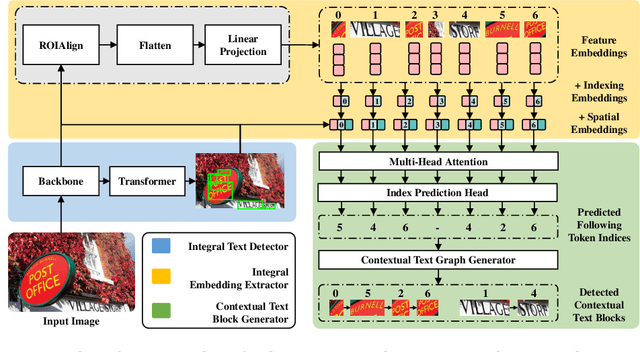
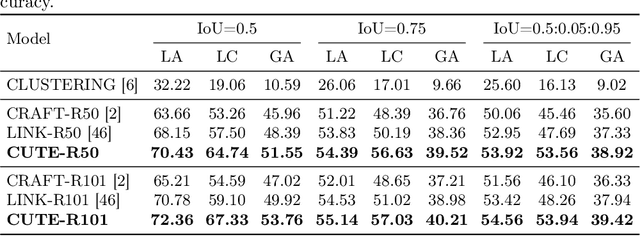
Most existing scene text detectors focus on detecting characters or words that only capture partial text messages due to missing contextual information. For a better understanding of text in scenes, it is more desired to detect contextual text blocks (CTBs) which consist of one or multiple integral text units (e.g., characters, words, or phrases) in natural reading order and transmit certain complete text messages. This paper presents contextual text detection, a new setup that detects CTBs for better understanding of texts in scenes. We formulate the new setup by a dual detection task which first detects integral text units and then groups them into a CTB. To this end, we design a novel scene text clustering technique that treats integral text units as tokens and groups them (belonging to the same CTB) into an ordered token sequence. In addition, we create two datasets SCUT-CTW-Context and ReCTS-Context to facilitate future research, where each CTB is well annotated by an ordered sequence of integral text units. Further, we introduce three metrics that measure contextual text detection in local accuracy, continuity, and global accuracy. Extensive experiments show that our method accurately detects CTBs which effectively facilitates downstream tasks such as text classification and translation. The project is available at https://sg-vilab.github.io/publication/xue2022contextual/.
In Defense of Online Models for Video Instance Segmentation
Jul 21, 2022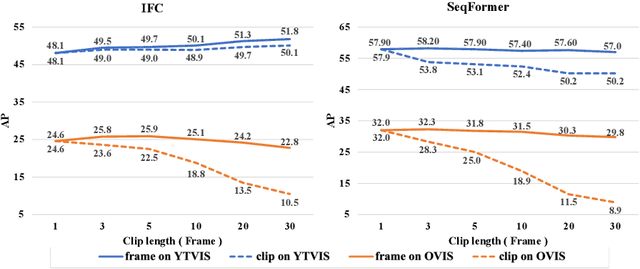

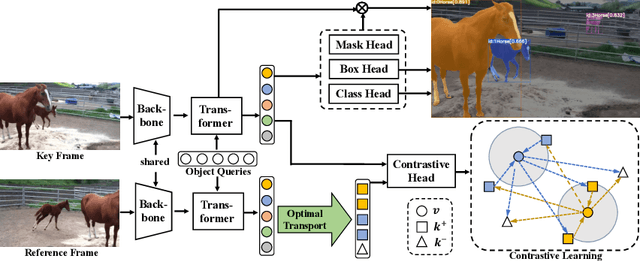
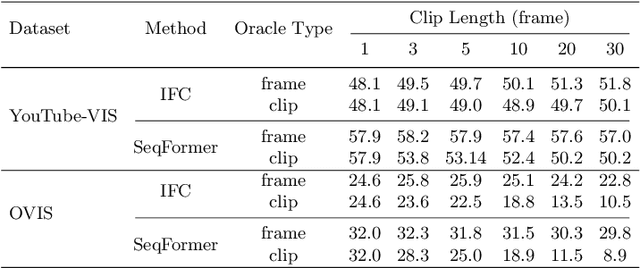
In recent years, video instance segmentation (VIS) has been largely advanced by offline models, while online models gradually attracted less attention possibly due to their inferior performance. However, online methods have their inherent advantage in handling long video sequences and ongoing videos while offline models fail due to the limit of computational resources. Therefore, it would be highly desirable if online models can achieve comparable or even better performance than offline models. By dissecting current online models and offline models, we demonstrate that the main cause of the performance gap is the error-prone association between frames caused by the similar appearance among different instances in the feature space. Observing this, we propose an online framework based on contrastive learning that is able to learn more discriminative instance embeddings for association and fully exploit history information for stability. Despite its simplicity, our method outperforms all online and offline methods on three benchmarks. Specifically, we achieve 49.5 AP on YouTube-VIS 2019, a significant improvement of 13.2 AP and 2.1 AP over the prior online and offline art, respectively. Moreover, we achieve 30.2 AP on OVIS, a more challenging dataset with significant crowding and occlusions, surpassing the prior art by 14.8 AP. The proposed method won first place in the video instance segmentation track of the 4th Large-scale Video Object Segmentation Challenge (CVPR2022). We hope the simplicity and effectiveness of our method, as well as our insight into current methods, could shed light on the exploration of VIS models.
CenterNet++ for Object Detection
Apr 18, 2022

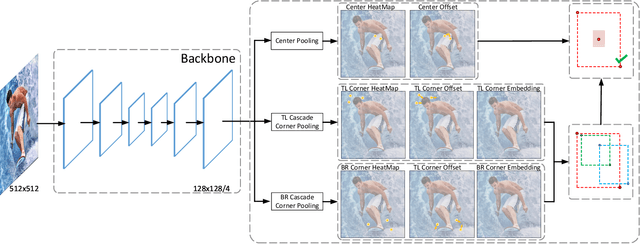
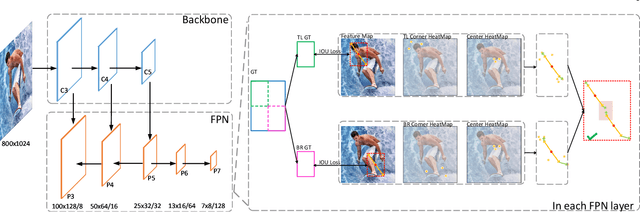
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
An Empirical Study of End-to-End Temporal Action Detection
Apr 06, 2022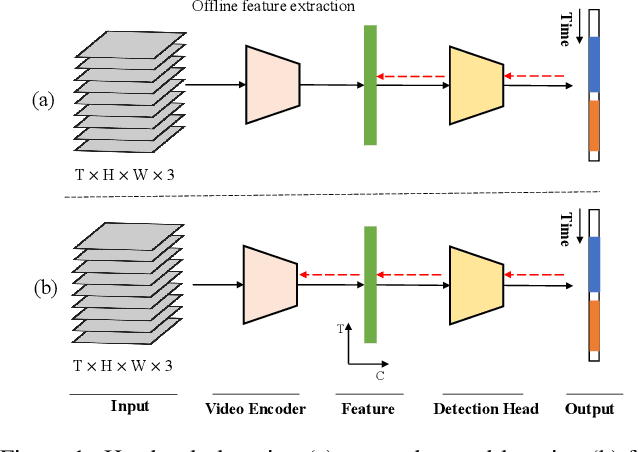
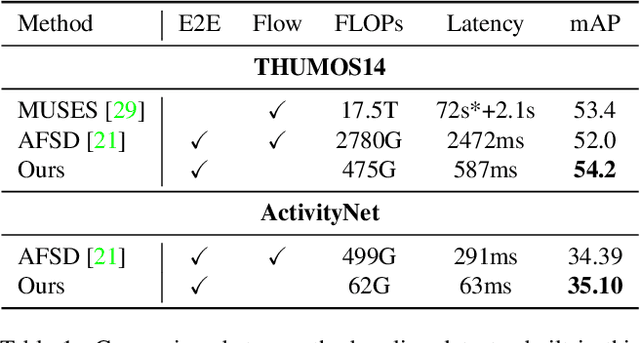
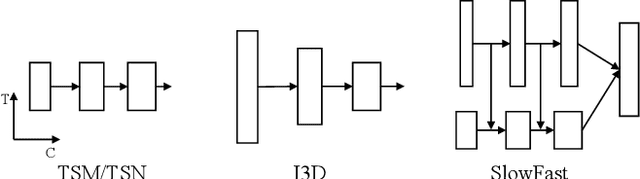
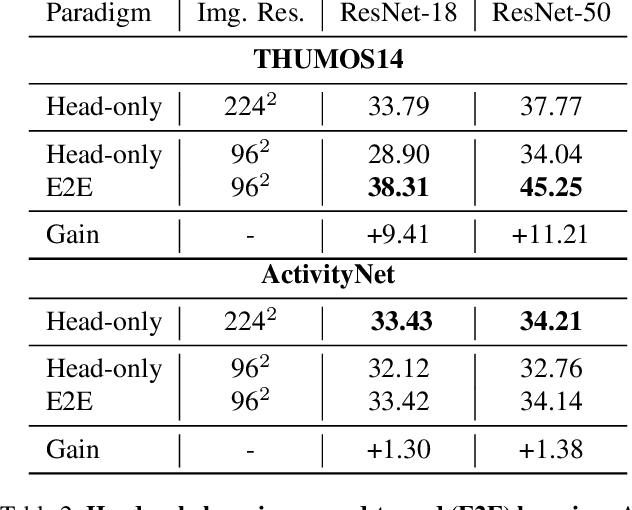
Temporal action detection (TAD) is an important yet challenging task in video understanding. It aims to simultaneously predict the semantic label and the temporal interval of every action instance in an untrimmed video. Rather than end-to-end learning, most existing methods adopt a head-only learning paradigm, where the video encoder is pre-trained for action classification, and only the detection head upon the encoder is optimized for TAD. The effect of end-to-end learning is not systematically evaluated. Besides, there lacks an in-depth study on the efficiency-accuracy trade-off in end-to-end TAD. In this paper, we present an empirical study of end-to-end temporal action detection. We validate the advantage of end-to-end learning over head-only learning and observe up to 11\% performance improvement. Besides, we study the effects of multiple design choices that affect the TAD performance and speed, including detection head, video encoder, and resolution of input videos. Based on the findings, we build a mid-resolution baseline detector, which achieves the state-of-the-art performance of end-to-end methods while running more than 4$\times$ faster. We hope that this paper can serve as a guide for end-to-end learning and inspire future research in this field. Code and models are available at \url{https://github.com/xlliu7/E2E-TAD}.
Knowledge Distillation as Efficient Pre-training: Faster Convergence, Higher Data-efficiency, and Better Transferability
Mar 26, 2022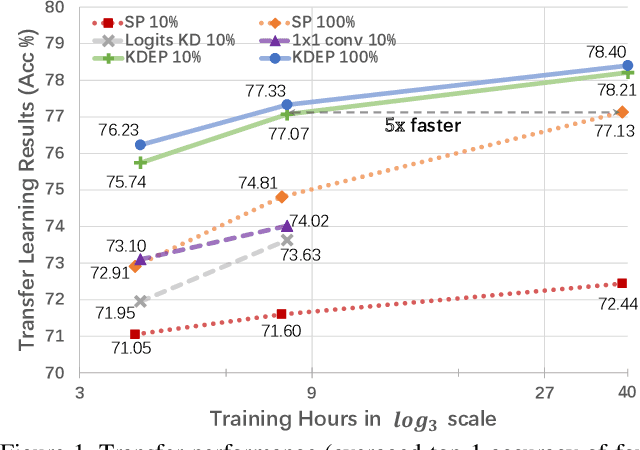
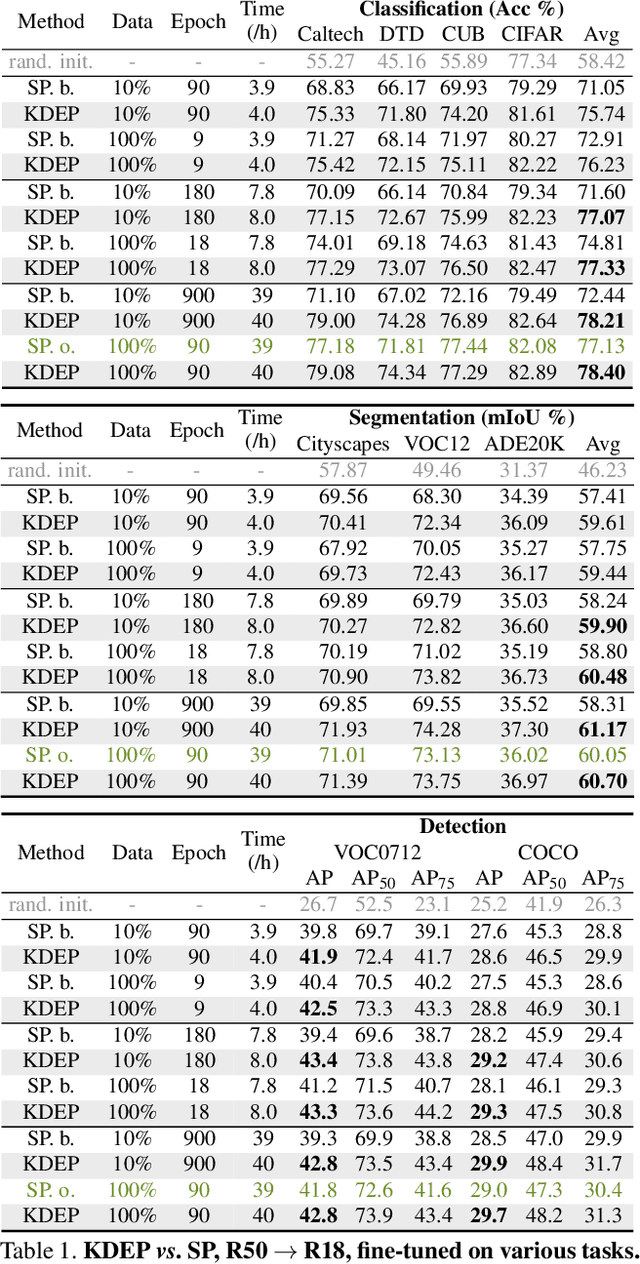
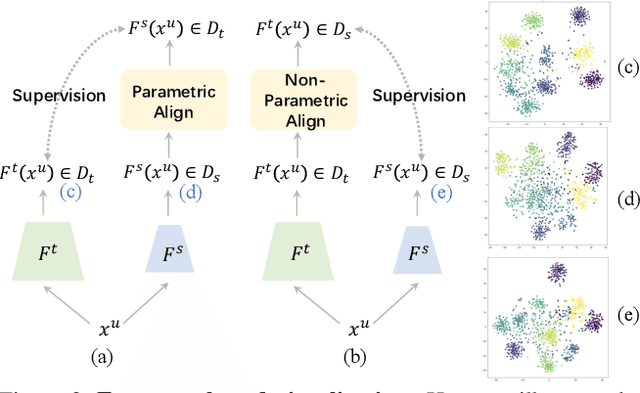
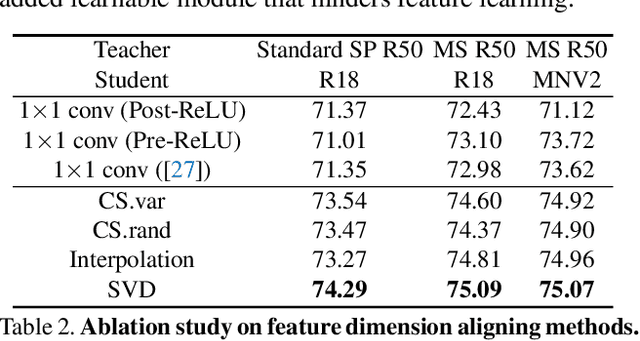
Large-scale pre-training has been proven to be crucial for various computer vision tasks. However, with the increase of pre-training data amount, model architecture amount, and the private/inaccessible data, it is not very efficient or possible to pre-train all the model architectures on large-scale datasets. In this work, we investigate an alternative strategy for pre-training, namely Knowledge Distillation as Efficient Pre-training (KDEP), aiming to efficiently transfer the learned feature representation from existing pre-trained models to new student models for future downstream tasks. We observe that existing Knowledge Distillation (KD) methods are unsuitable towards pre-training since they normally distill the logits that are going to be discarded when transferred to downstream tasks. To resolve this problem, we propose a feature-based KD method with non-parametric feature dimension aligning. Notably, our method performs comparably with supervised pre-training counterparts in 3 downstream tasks and 9 downstream datasets requiring 10x less data and 5x less pre-training time. Code is available at https://github.com/CVMI-Lab/KDEP.
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
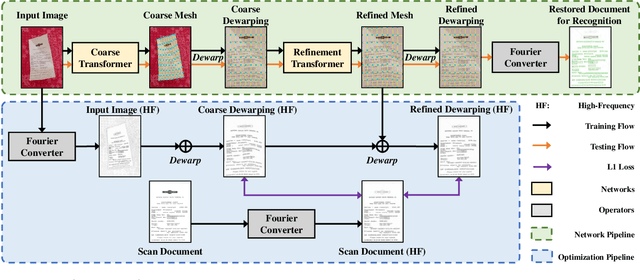
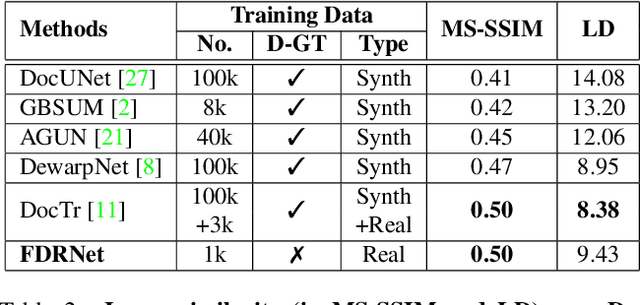
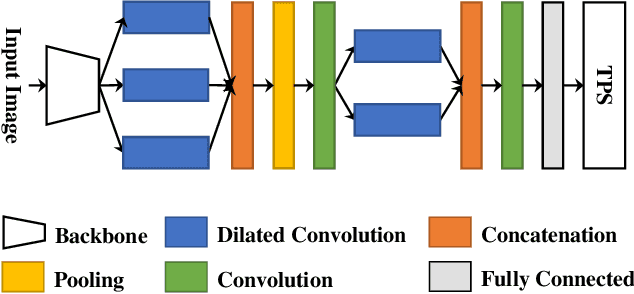
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022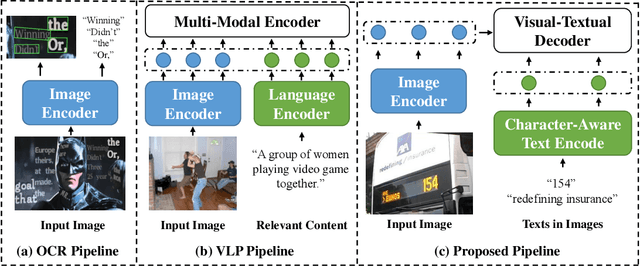
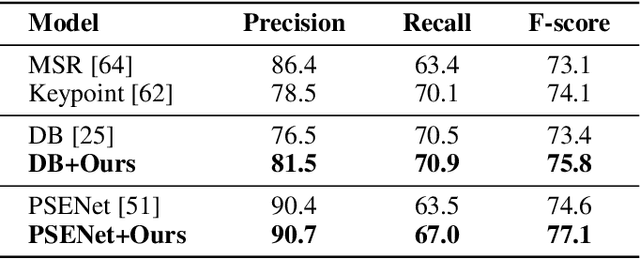
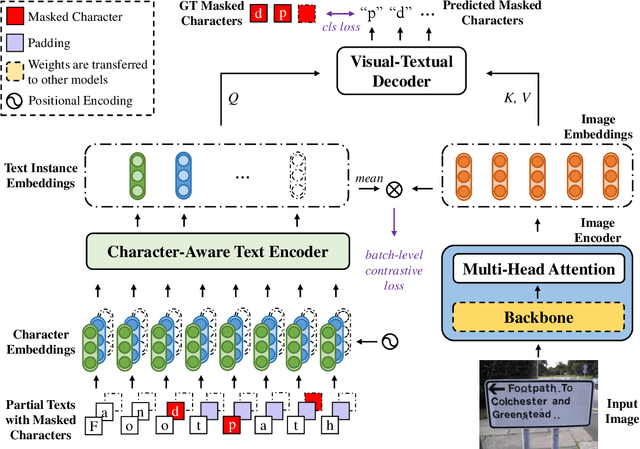

Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
Jan 03, 2022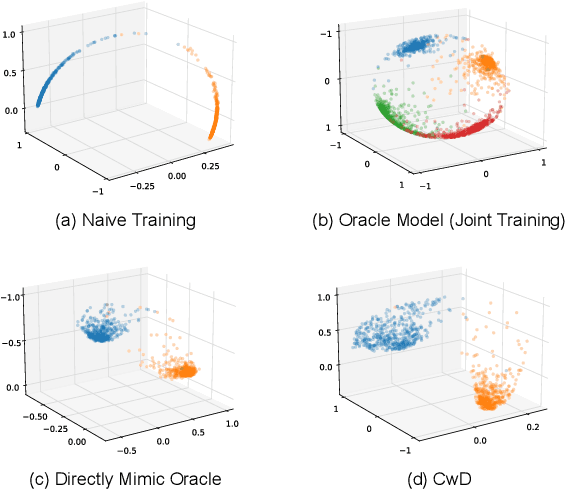
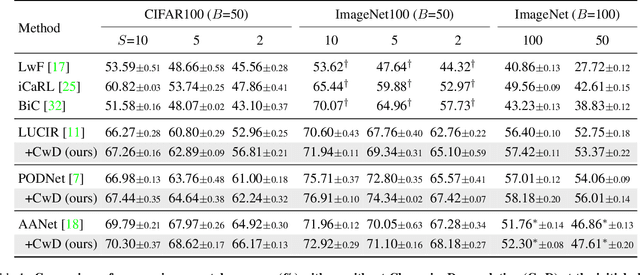
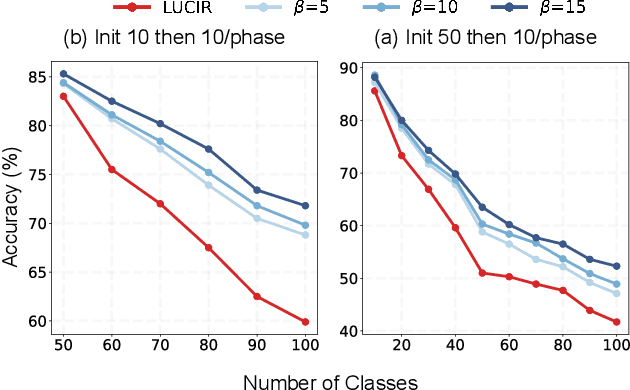
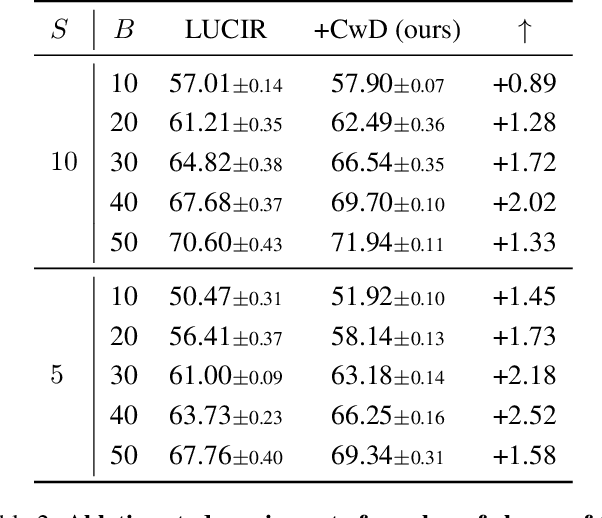
Class Incremental Learning (CIL) aims at learning a multi-class classifier in a phase-by-phase manner, in which only data of a subset of the classes are provided at each phase. Previous works mainly focus on mitigating forgetting in phases after the initial one. However, we find that improving CIL at its initial phase is also a promising direction. Specifically, we experimentally show that directly encouraging CIL Learner at the initial phase to output similar representations as the model jointly trained on all classes can greatly boost the CIL performance. Motivated by this, we study the difference between a na\"ively-trained initial-phase model and the oracle model. Specifically, since one major difference between these two models is the number of training classes, we investigate how such difference affects the model representations. We find that, with fewer training classes, the data representations of each class lie in a long and narrow region; with more training classes, the representations of each class scatter more uniformly. Inspired by this observation, we propose Class-wise Decorrelation (CwD) that effectively regularizes representations of each class to scatter more uniformly, thus mimicking the model jointly trained with all classes (i.e., the oracle model). Our CwD is simple to implement and easy to plug into existing methods. Extensive experiments on various benchmark datasets show that CwD consistently and significantly improves the performance of existing state-of-the-art methods by around 1\% to 3\%. Code will be released.
SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation
Dec 15, 2021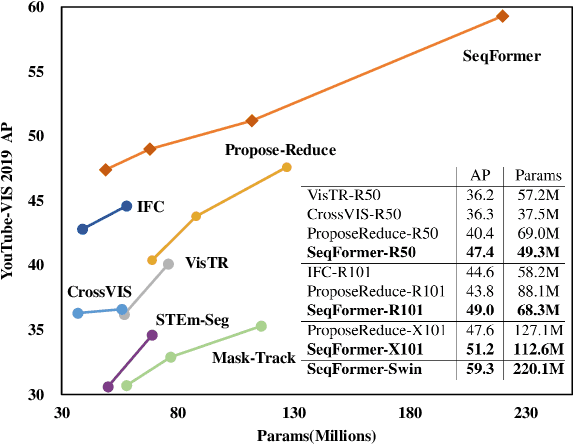
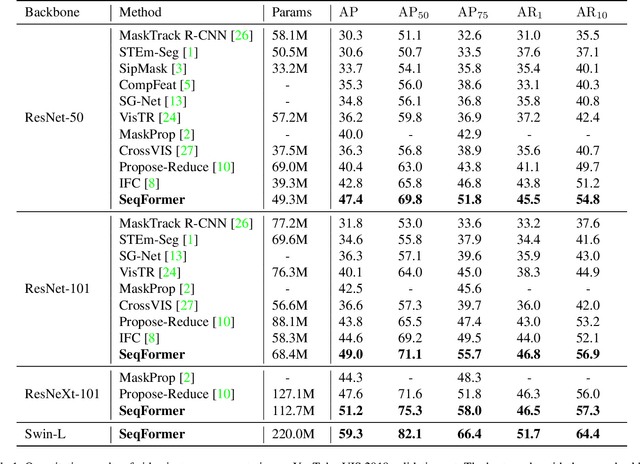
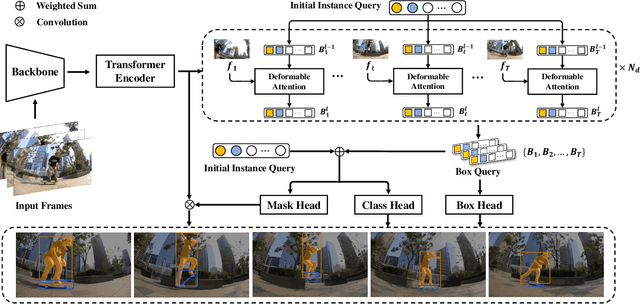
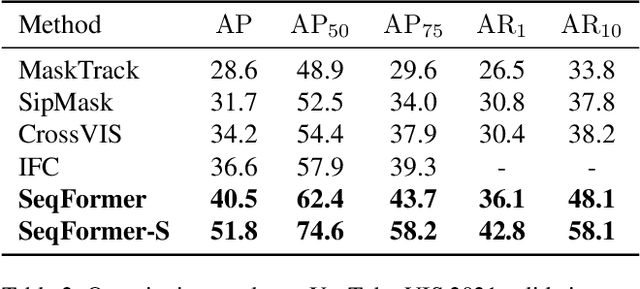
In this work, we present SeqFormer, a frustratingly simple model for video instance segmentation. SeqFormer follows the principle of vision transformer that models instance relationships among video frames. Nevertheless, we observe that a stand-alone instance query suffices for capturing a time sequence of instances in a video, but attention mechanisms should be done with each frame independently. To achieve this, SeqFormer locates an instance in each frame and aggregates temporal information to learn a powerful representation of a video-level instance, which is used to predict the mask sequences on each frame dynamically. Instance tracking is achieved naturally without tracking branches or post-processing. On the YouTube-VIS dataset, SeqFormer achieves 47.4 AP with a ResNet-50 backbone and 49.0 AP with a ResNet-101 backbone without bells and whistles. Such achievement significantly exceeds the previous state-of-the-art performance by 4.6 and 4.4, respectively. In addition, integrated with the recently-proposed Swin transformer, SeqFormer achieves a much higher AP of 59.3. We hope SeqFormer could be a strong baseline that fosters future research in video instance segmentation, and in the meantime, advances this field with a more robust, accurate, neat model. The code and the pre-trained models are publicly available at https://github.com/wjf5203/SeqFormer.
DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
Nov 29, 2021



A typical pipeline for multi-object tracking (MOT) is to use a detector for object localization, and following re-identification (re-ID) for object association. This pipeline is partially motivated by recent progress in both object detection and re-ID, and partially motivated by biases in existing tracking datasets, where most objects tend to have distinguishing appearance and re-ID models are sufficient for establishing associations. In response to such bias, we would like to re-emphasize that methods for multi-object tracking should also work when object appearance is not sufficiently discriminative. To this end, we propose a large-scale dataset for multi-human tracking, where humans have similar appearance, diverse motion and extreme articulation. As the dataset contains mostly group dancing videos, we name it "DanceTrack". We expect DanceTrack to provide a better platform to develop more MOT algorithms that rely less on visual discrimination and depend more on motion analysis. We benchmark several state-of-the-art trackers on our dataset and observe a significant performance drop on DanceTrack when compared against existing benchmarks. The dataset, project code and competition server are released at: \url{https://github.com/DanceTrack}.