 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
IQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023

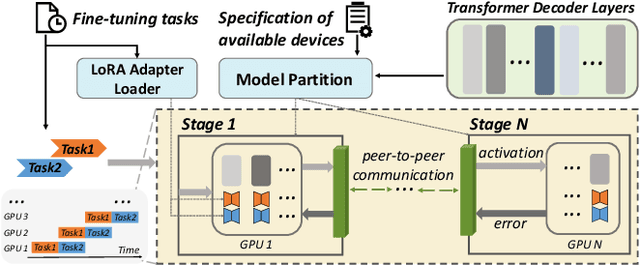
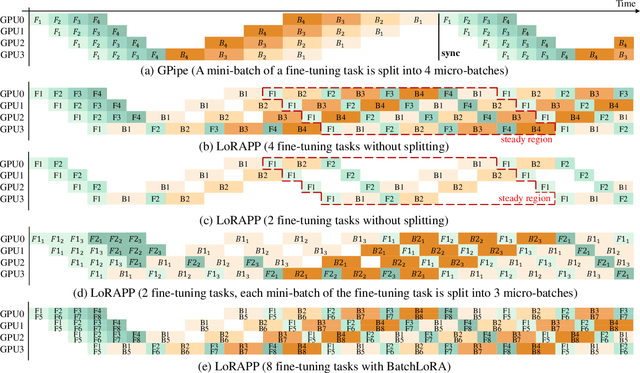
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.