 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Aug 06, 2021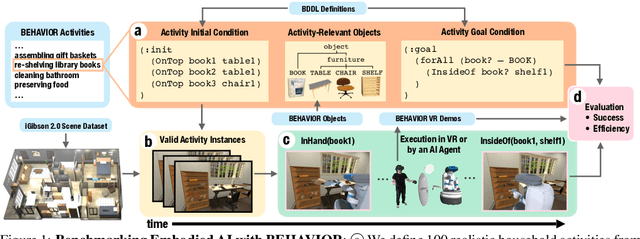
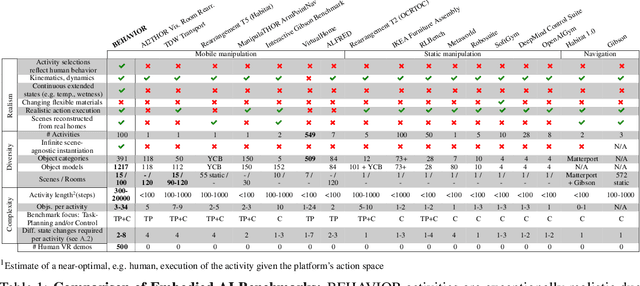

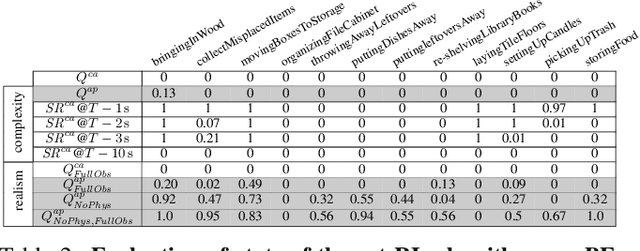
We introduce BEHAVIOR, a benchmark for embodied AI with 100 activities in simulation, spanning a range of everyday household chores such as cleaning, maintenance, and food preparation. These activities are designed to be realistic, diverse, and complex, aiming to reproduce the challenges that agents must face in the real world. Building such a benchmark poses three fundamental difficulties for each activity: definition (it can differ by time, place, or person), instantiation in a simulator, and evaluation. BEHAVIOR addresses these with three innovations. First, we propose an object-centric, predicate logic-based description language for expressing an activity's initial and goal conditions, enabling generation of diverse instances for any activity. Second, we identify the simulator-agnostic features required by an underlying environment to support BEHAVIOR, and demonstrate its realization in one such simulator. Third, we introduce a set of metrics to measure task progress and efficiency, absolute and relative to human demonstrators. We include 500 human demonstrations in virtual reality (VR) to serve as the human ground truth. Our experiments demonstrate that even state of the art embodied AI solutions struggle with the level of realism, diversity, and complexity imposed by the activities in our benchmark. We make BEHAVIOR publicly available at behavior.stanford.edu to facilitate and calibrate the development of new embodied AI solutions.
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Aug 06, 2021
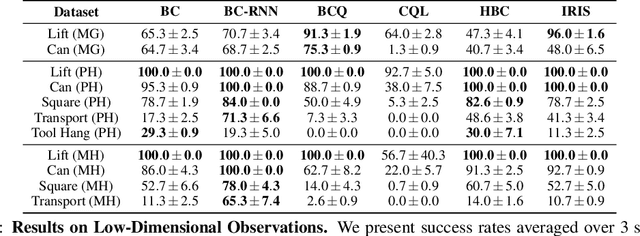
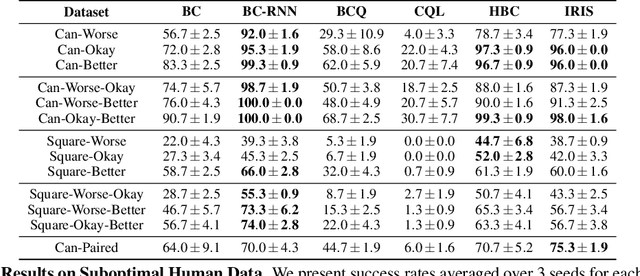
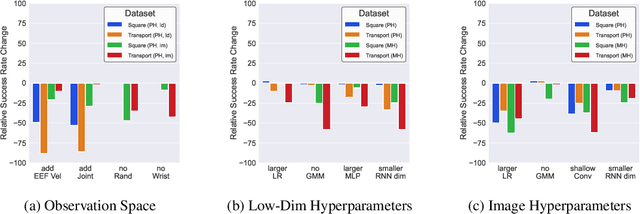
Imitating human demonstrations is a promising approach to endow robots with various manipulation capabilities. While recent advances have been made in imitation learning and batch (offline) reinforcement learning, a lack of open-source human datasets and reproducible learning methods make assessing the state of the field difficult. In this paper, we conduct an extensive study of six offline learning algorithms for robot manipulation on five simulated and three real-world multi-stage manipulation tasks of varying complexity, and with datasets of varying quality. Our study analyzes the most critical challenges when learning from offline human data for manipulation. Based on the study, we derive a series of lessons including the sensitivity to different algorithmic design choices, the dependence on the quality of the demonstrations, and the variability based on the stopping criteria due to the different objectives in training and evaluation. We also highlight opportunities for learning from human datasets, such as the ability to learn proficient policies on challenging, multi-stage tasks beyond the scope of current reinforcement learning methods, and the ability to easily scale to natural, real-world manipulation scenarios where only raw sensory signals are available. We have open-sourced our datasets and all algorithm implementations to facilitate future research and fair comparisons in learning from human demonstration data. Codebase, datasets, trained models, and more available at https://arise-initiative.github.io/robomimic-web/
Discovering Generalizable Skills via Automated Generation of Diverse Tasks
Jun 26, 2021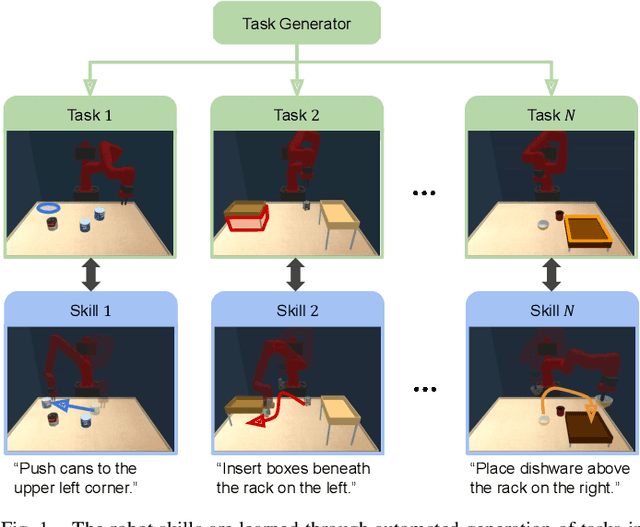
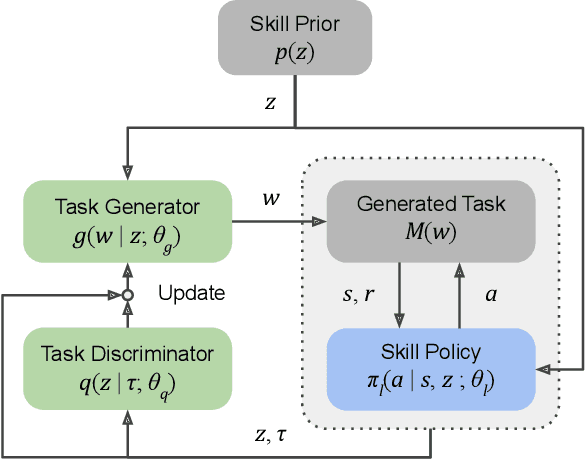
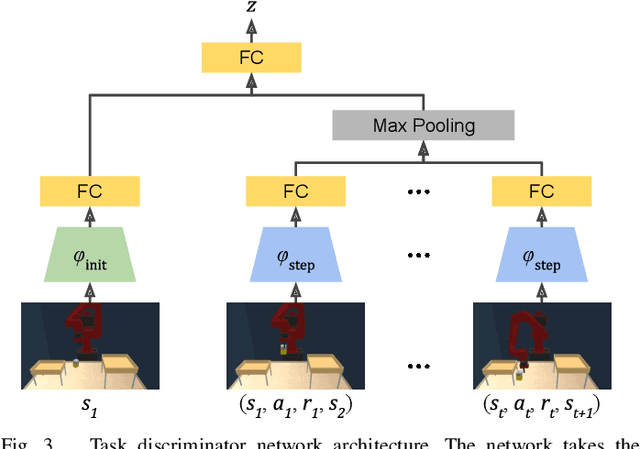
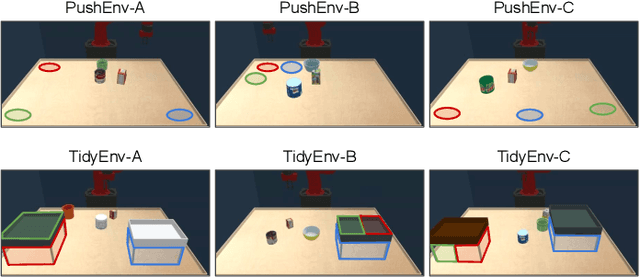
The learning efficiency and generalization ability of an intelligent agent can be greatly improved by utilizing a useful set of skills. However, the design of robot skills can often be intractable in real-world applications due to the prohibitive amount of effort and expertise that it requires. In this work, we introduce Skill Learning In Diversified Environments (SLIDE), a method to discover generalizable skills via automated generation of a diverse set of tasks. As opposed to prior work on unsupervised discovery of skills which incentivizes the skills to produce different outcomes in the same environment, our method pairs each skill with a unique task produced by a trainable task generator. To encourage generalizable skills to emerge, our method trains each skill to specialize in the paired task and maximizes the diversity of the generated tasks. A task discriminator defined on the robot behaviors in the generated tasks is jointly trained to estimate the evidence lower bound of the diversity objective. The learned skills can then be composed in a hierarchical reinforcement learning algorithm to solve unseen target tasks. We demonstrate that the proposed method can effectively learn a variety of robot skills in two tabletop manipulation domains. Our results suggest that the learned skills can effectively improve the robot's performance in various unseen target tasks compared to existing reinforcement learning and skill learning methods.
JRDB-Act: A Large-scale Multi-modal Dataset for Spatio-temporal Action, Social Group and Activity Detection
Jun 16, 2021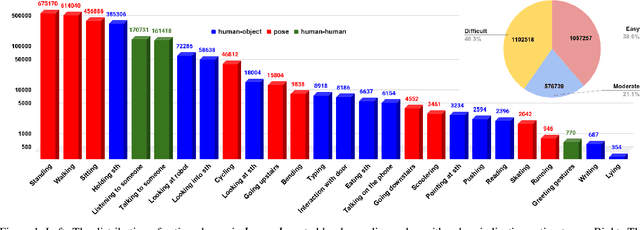
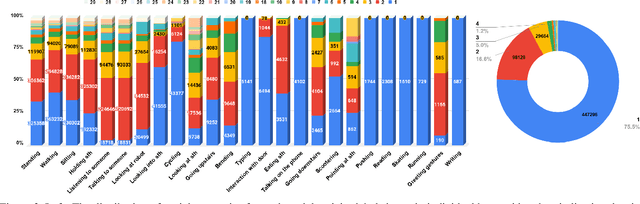
The availability of large-scale video action understanding datasets has facilitated advances in the interpretation of visual scenes containing people. However, learning to recognize human activities in an unconstrained real-world environment, with potentially highly unbalanced and long-tailed distributed data remains a significant challenge, not least owing to the lack of a reflective large-scale dataset. Most existing large-scale datasets are either collected from a specific or constrained environment, e.g. kitchens or rooms, or video sharing platforms such as YouTube. In this paper, we introduce JRDB-Act, a multi-modal dataset, as an extension of the existing JRDB, which is captured by asocial mobile manipulator and reflects a real distribution of human daily life actions in a university campus environment. JRDB-Act has been densely annotated with atomic actions, comprises over 2.8M action labels, constituting a large-scale spatio-temporal action detection dataset. Each human bounding box is labelled with one pose-based action label and multiple (optional) interaction-based action labels. Moreover JRDB-Act comes with social group identification annotations conducive to the task of grouping individuals based on their interactions in the scene to infer their social activities (common activities in each social group).
TRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild
Apr 08, 2021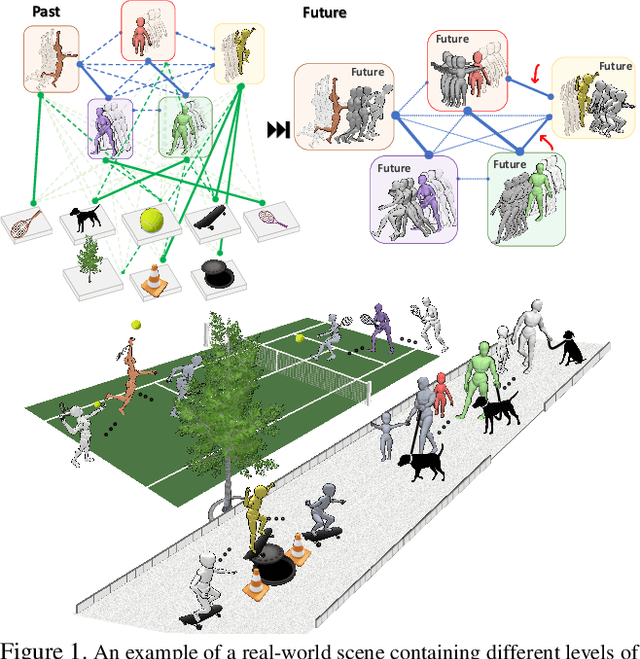
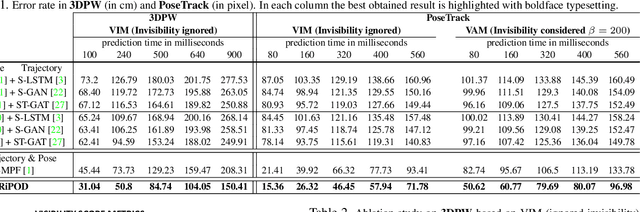
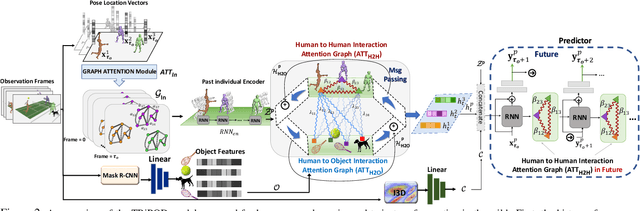
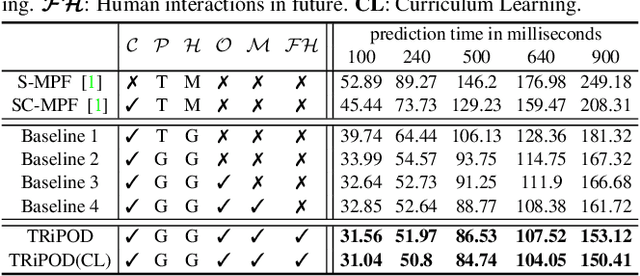
Joint forecasting of human trajectory and pose dynamics is a fundamental building block of various applications ranging from robotics and autonomous driving to surveillance systems. Predicting body dynamics requires capturing subtle information embedded in the humans' interactions with each other and with the objects present in the scene. In this paper, we propose a novel TRajectory and POse Dynamics (nicknamed TRiPOD) method based on graph attentional networks to model the human-human and human-object interactions both in the input space and the output space (decoded future output). The model is supplemented by a message passing interface over the graphs to fuse these different levels of interactions efficiently. Furthermore, to incorporate a real-world challenge, we propound to learn an indicator representing whether an estimated body joint is visible/invisible at each frame, e.g. due to occlusion or being outside the sensor field of view. Finally, we introduce a new benchmark for this joint task based on two challenging datasets (PoseTrack and 3DPW) and propose evaluation metrics to measure the effectiveness of predictions in the global space, even when there are invisible cases of joints. Our evaluation shows that TRiPOD outperforms all prior work and state-of-the-art specifically designed for each of the trajectory and pose forecasting tasks.
LASER: Learning a Latent Action Space for Efficient Reinforcement Learning
Mar 30, 2021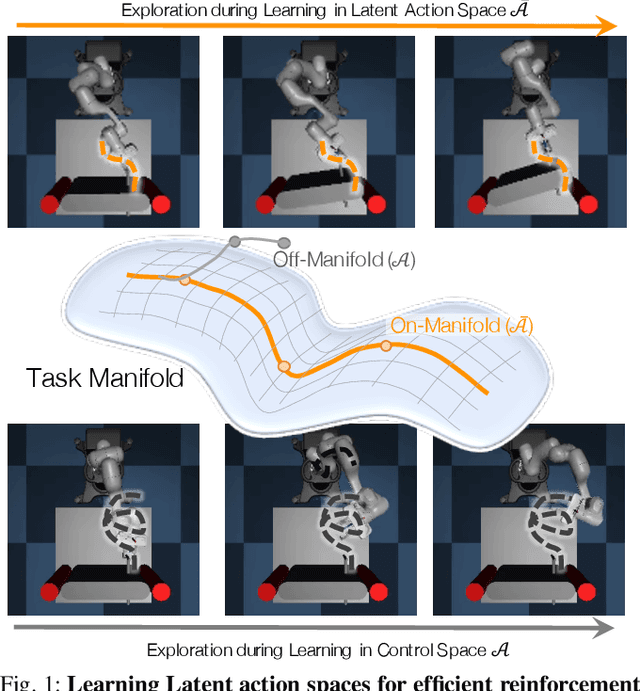
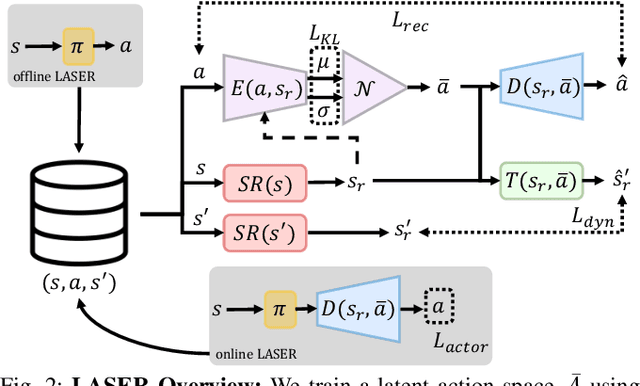

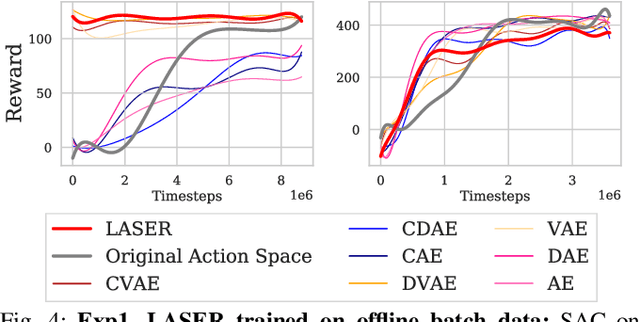
The process of learning a manipulation task depends strongly on the action space used for exploration: posed in the incorrect action space, solving a task with reinforcement learning can be drastically inefficient. Additionally, similar tasks or instances of the same task family impose latent manifold constraints on the most effective action space: the task family can be best solved with actions in a manifold of the entire action space of the robot. Combining these insights we present LASER, a method to learn latent action spaces for efficient reinforcement learning. LASER factorizes the learning problem into two sub-problems, namely action space learning and policy learning in the new action space. It leverages data from similar manipulation task instances, either from an offline expert or online during policy learning, and learns from these trajectories a mapping from the original to a latent action space. LASER is trained as a variational encoder-decoder model to map raw actions into a disentangled latent action space while maintaining action reconstruction and latent space dynamic consistency. We evaluate LASER on two contact-rich robotic tasks in simulation, and analyze the benefit of policy learning in the generated latent action space. We show improved sample efficiency compared to the original action space from better alignment of the action space to the task space, as we observe with visualizations of the learned action space manifold. Additional details: https://www.pair.toronto.edu/laser
Neural Architecture Search From Fréchet Task Distance
Mar 25, 2021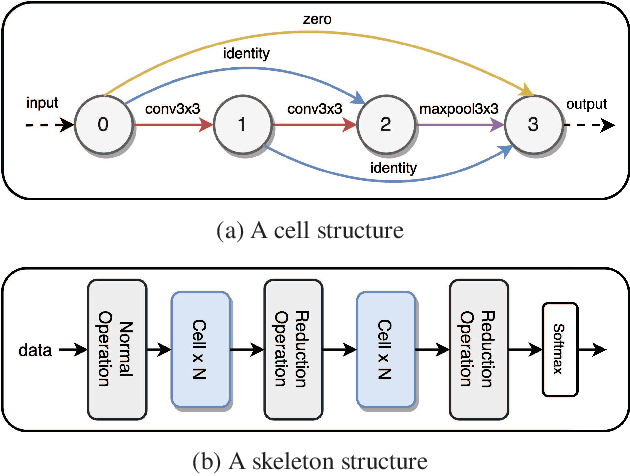
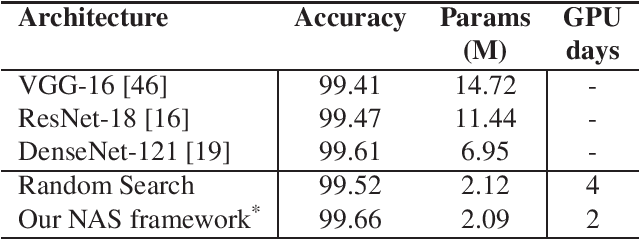
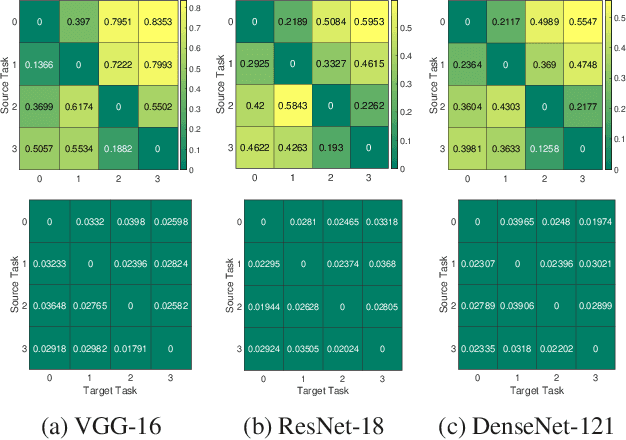
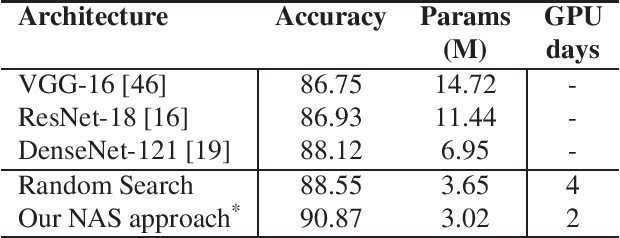
We formulate a Fr\'echet-type asymmetric distance between tasks based on Fisher Information Matrices. We show how the distance between a target task and each task in a given set of baseline tasks can be used to reduce the neural architecture search space for the target task. The complexity reduction in search space for task-specific architectures is achieved by building on the optimized architectures for similar tasks instead of doing a full search without using this side information. Experimental results demonstrate the efficacy of the proposed approach and its improvements over the state-of-the-art methods.
Generalization Through Hand-Eye Coordination: An Action Space for Learning Spatially-Invariant Visuomotor Control
Feb 28, 2021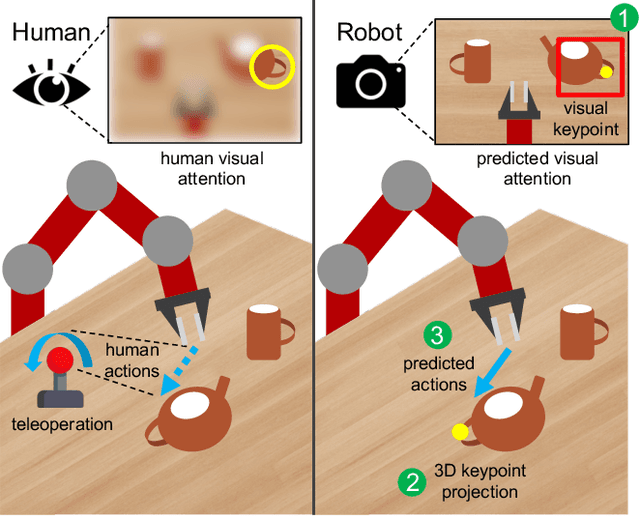
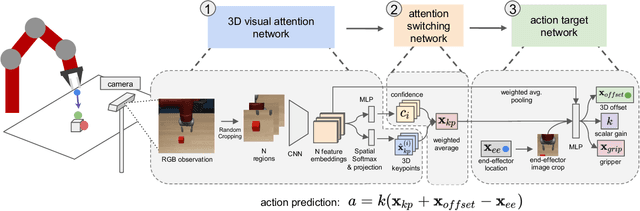
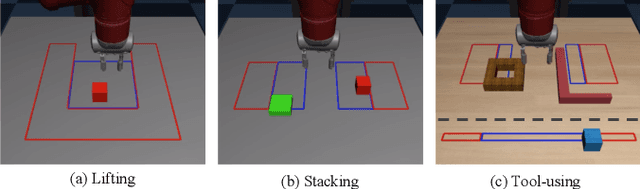
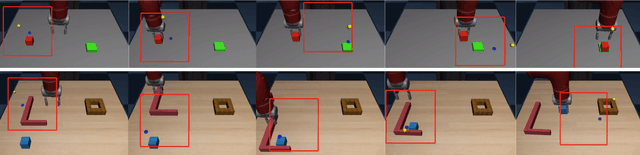
Imitation Learning (IL) is an effective framework to learn visuomotor skills from offline demonstration data. However, IL methods often fail to generalize to new scene configurations not covered by training data. On the other hand, humans can manipulate objects in varying conditions. Key to such capability is hand-eye coordination, a cognitive ability that enables humans to adaptively direct their movements at task-relevant objects and be invariant to the objects' absolute spatial location. In this work, we present a learnable action space, Hand-eye Action Networks (HAN), that can approximate human's hand-eye coordination behaviors by learning from human teleoperated demonstrations. Through a set of challenging multi-stage manipulation tasks, we show that a visuomotor policy equipped with HAN is able to inherit the key spatial invariance property of hand-eye coordination and achieve zero-shot generalization to new scene configurations. Additional materials available at https://sites.google.com/stanford.edu/han
Localized Calibration: Metrics and Recalibration
Feb 22, 2021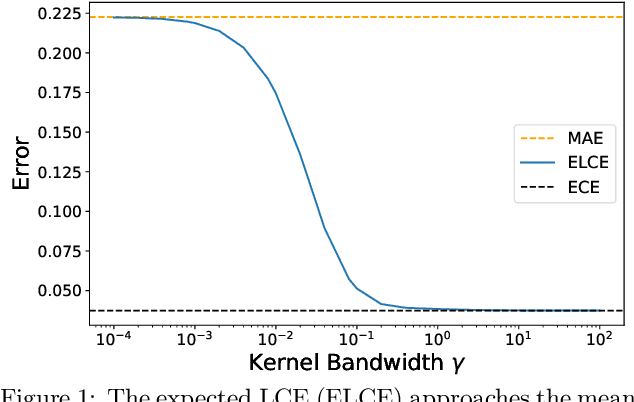
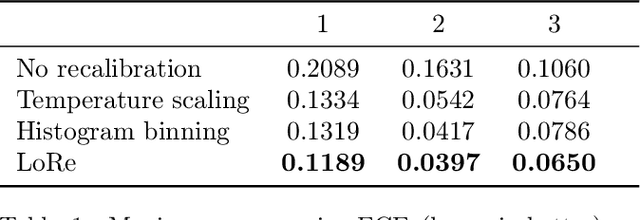
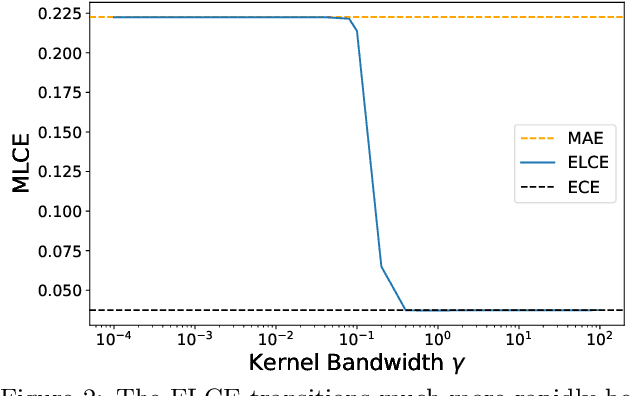
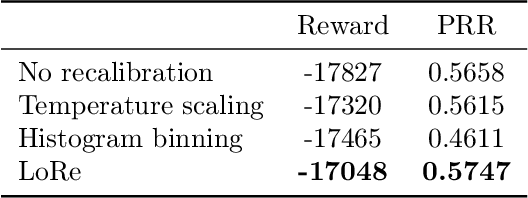
Probabilistic classifiers output confidence scores along with their predictions, and these confidence scores must be well-calibrated (i.e. reflect the true probability of an event) to be meaningful and useful for downstream tasks. However, existing metrics for measuring calibration are insufficient. Commonly used metrics such as the expected calibration error (ECE) only measure global trends, making them ineffective for measuring the calibration of a particular sample or subgroup. At the other end of the spectrum, a fully individualized calibration error is in general intractable to estimate from finite samples. In this work, we propose the local calibration error (LCE), a fine-grained calibration metric that spans the gap between fully global and fully individualized calibration. The LCE leverages learned features to automatically capture rich subgroups, and it measures the calibration error around each individual example via a similarity function. We then introduce a localized recalibration method, LoRe, that improves the LCE better than existing recalibration methods. Finally, we show that applying our recalibration method improves decision-making on downstream tasks.
Embodied Intelligence via Learning and Evolution
Feb 03, 2021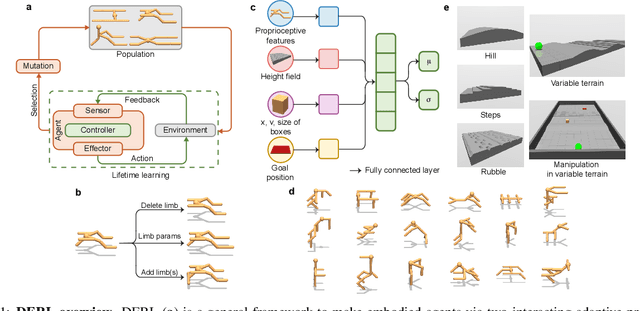

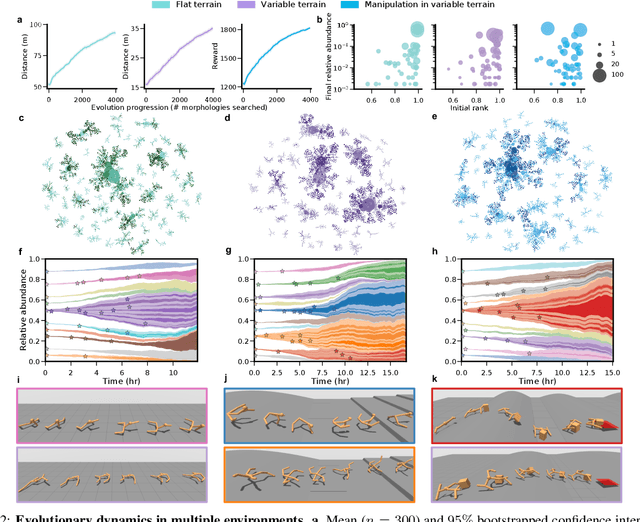
The intertwined processes of learning and evolution in complex environmental niches have resulted in a remarkable diversity of morphological forms. Moreover, many aspects of animal intelligence are deeply embodied in these evolved morphologies. However, the principles governing relations between environmental complexity, evolved morphology, and the learnability of intelligent control, remain elusive, partially due to the substantial challenge of performing large-scale in silico experiments on evolution and learning. We introduce Deep Evolutionary Reinforcement Learning (DERL): a novel computational framework which can evolve diverse agent morphologies to learn challenging locomotion and manipulation tasks in complex environments using only low level egocentric sensory information. Leveraging DERL we demonstrate several relations between environmental complexity, morphological intelligence and the learnability of control. First, environmental complexity fosters the evolution of morphological intelligence as quantified by the ability of a morphology to facilitate the learning of novel tasks. Second, evolution rapidly selects morphologies that learn faster, thereby enabling behaviors learned late in the lifetime of early ancestors to be expressed early in the lifetime of their descendants. In agents that learn and evolve in complex environments, this result constitutes the first demonstration of a long-conjectured morphological Baldwin effect. Third, our experiments suggest a mechanistic basis for both the Baldwin effect and the emergence of morphological intelligence through the evolution of morphologies that are more physically stable and energy efficient, and can therefore facilitate learning and control.