 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Optimal Offline Reinforcement Learning via Smooth Tchebysheff Scalarization
Apr 14, 2026Large language models can be aligned with human preferences through offline reinforcement learning (RL) on small labeled datasets. While single-objective alignment is well-studied, many real-world applications demand the simultaneous optimization of multiple conflicting rewards, e.g. optimizing both catalytic activity and specificity in protein engineering, or helpfulness and harmlessness for chatbots. Prior work has largely relied on linear reward scalarization, but this approach provably fails to recover non-convex regions of the Pareto front. In this paper, instead of scalarizing the rewards directly, we frame multi-objective RL itself as an optimization problem to be scalarized via smooth Tchebysheff scalarization, a recent technique that overcomes the shortcomings of linear scalarization. We use this formulation to derive Smooth Tchebysheff Optimization of Multi-Objective Preferences (STOMP), a novel offline RL algorithm that extends direct preference optimization to the multi-objective setting in a principled way by standardizing the individual rewards based on their observed distributions. We empirically validate STOMP on a range of protein engineering tasks by aligning three autoregressive protein language models on three laboratory datasets of protein fitness. Compared to state-of-the-art baselines, STOMP achieves the highest hypervolumes in eight of nine settings according to both offline off-policy and generative evaluations. We thus demonstrate that STOMP is a powerful, robust multi-objective alignment algorithm that can meaningfully improve post-trained models for multi-attribute protein optimization and beyond.
Conditional Enzyme Generation Using Protein Language Models with Adapters
Oct 04, 2024



The conditional generation of proteins with desired functions and/or properties is a key goal for generative models. Existing methods based on prompting of language models can generate proteins conditioned on a target functionality, such as a desired enzyme family. However, these methods are limited to simple, tokenized conditioning and have not been shown to generalize to unseen functions. In this study, we propose ProCALM (Protein Conditionally Adapted Language Model), an approach for the conditional generation of proteins using adapters to protein language models. Our specific implementation of ProCALM involves finetuning ProGen2 to incorporate conditioning representations of enzyme function and taxonomy. ProCALM matches existing methods at conditionally generating sequences from target enzyme families. Impressively, it can also generate within the joint distribution of enzymatic function and taxonomy, and it can generalize to rare and unseen enzyme families and taxonomies. Overall, ProCALM is a flexible and computationally efficient approach, and we expect that it can be extended to a wide range of generative language models.
Towards Joint Sequence-Structure Generation of Nucleic Acid and Protein Complexes with SE(3)-Discrete Diffusion
Dec 21, 2023Generative models of macromolecules carry abundant and impactful implications for industrial and biomedical efforts in protein engineering. However, existing methods are currently limited to modeling protein structures or sequences, independently or jointly, without regard to the interactions that commonly occur between proteins and other macromolecules. In this work, we introduce MMDiff, a generative model that jointly designs sequences and structures of nucleic acid and protein complexes, independently or in complex, using joint SE(3)-discrete diffusion noise. Such a model has important implications for emerging areas of macromolecular design including structure-based transcription factor design and design of noncoding RNA sequences. We demonstrate the utility of MMDiff through a rigorous new design benchmark for macromolecular complex generation that we introduce in this work. Our results demonstrate that MMDiff is able to successfully generate micro-RNA and single-stranded DNA molecules while being modestly capable of joint modeling DNA and RNA molecules in interaction with multi-chain protein complexes. Source code: https://github.com/Profluent-Internships/MMDiff.
Improved Online Conformal Prediction via Strongly Adaptive Online Learning
Feb 15, 2023We study the problem of uncertainty quantification via prediction sets, in an online setting where the data distribution may vary arbitrarily over time. Recent work develops online conformal prediction techniques that leverage regret minimization algorithms from the online learning literature to learn prediction sets with approximately valid coverage and small regret. However, standard regret minimization could be insufficient for handling changing environments, where performance guarantees may be desired not only over the full time horizon but also in all (sub-)intervals of time. We develop new online conformal prediction methods that minimize the strongly adaptive regret, which measures the worst-case regret over all intervals of a fixed length. We prove that our methods achieve near-optimal strongly adaptive regret for all interval lengths simultaneously, and approximately valid coverage. Experiments show that our methods consistently obtain better coverage and smaller prediction sets than existing methods on real-world tasks, such as time series forecasting and image classification under distribution shift.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
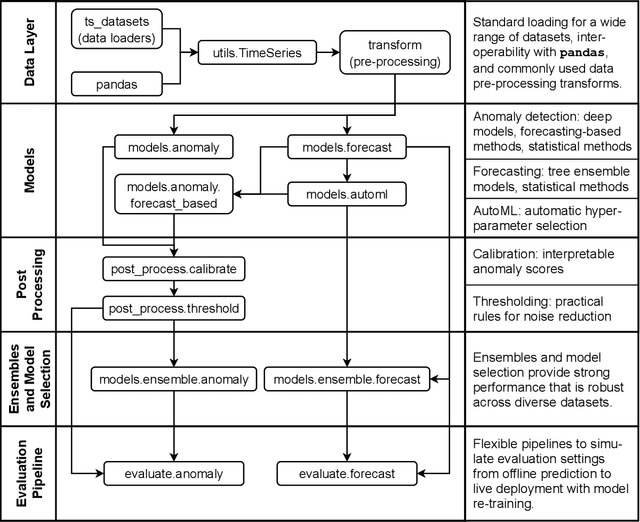
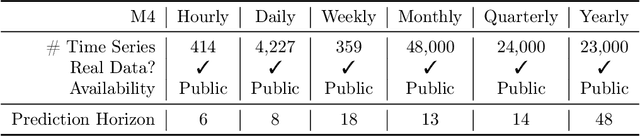

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.
Localized Calibration: Metrics and Recalibration
Feb 22, 2021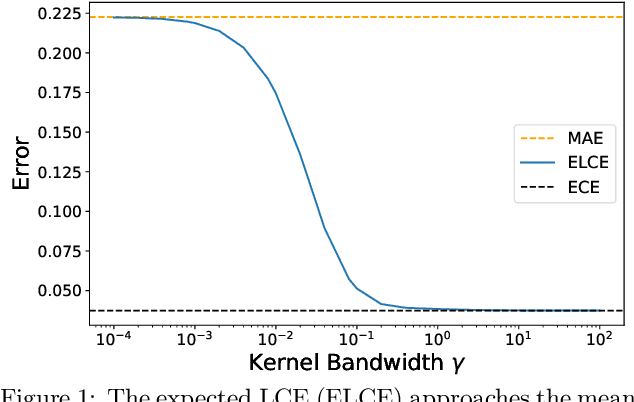
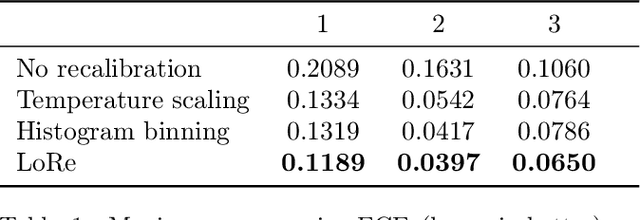
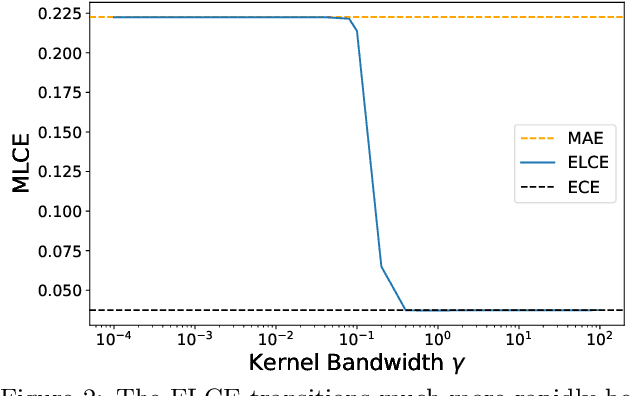
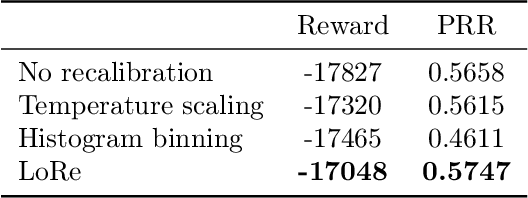
Probabilistic classifiers output confidence scores along with their predictions, and these confidence scores must be well-calibrated (i.e. reflect the true probability of an event) to be meaningful and useful for downstream tasks. However, existing metrics for measuring calibration are insufficient. Commonly used metrics such as the expected calibration error (ECE) only measure global trends, making them ineffective for measuring the calibration of a particular sample or subgroup. At the other end of the spectrum, a fully individualized calibration error is in general intractable to estimate from finite samples. In this work, we propose the local calibration error (LCE), a fine-grained calibration metric that spans the gap between fully global and fully individualized calibration. The LCE leverages learned features to automatically capture rich subgroups, and it measures the calibration error around each individual example via a similarity function. We then introduce a localized recalibration method, LoRe, that improves the LCE better than existing recalibration methods. Finally, we show that applying our recalibration method improves decision-making on downstream tasks.