 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
Leveraging Chain of Thought towards Empathetic Spoken Dialogue without Corresponding Question-Answering Data
Jan 19, 2025



Empathetic dialogue is crucial for natural human-computer interaction, allowing the dialogue system to respond in a more personalized and emotionally aware manner, improving user satisfaction and engagement. The emergence of large language models (LLMs) has revolutionized dialogue generation by harnessing their powerful capabilities and shown its potential in multimodal domains. Many studies have integrated speech with text-based LLMs to take speech question as input and output text response. However, the lack of spoken question-answering datasets that include speech style information to supervised fine-tuning (SFT) limits the performance of these systems. As a result, while these systems excel at understanding speech content, they often struggle to generate empathetic responses. In response, we propose a novel approach that circumvents the need for question-answering data, called Listen, Perceive, and Express (LPE). Our method employs a two-stage training process, initially guiding the LLM to listen the content and perceive the emotional aspects of speech. Subsequently, we utilize Chain-of-Thought (CoT) prompting to unlock the model's potential for expressing empathetic responses based on listened spoken content and perceived emotional cues. We employ experiments to prove the effectiveness of proposed method. To our knowledge, this is the first attempt to leverage CoT for speech-based dialogue.
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
The Codec Language Model-based Zero-Shot Spontaneous Style TTS System for CoVoC Challenge 2024
Dec 02, 2024



This paper describes the zero-shot spontaneous style TTS system for the ISCSLP 2024 Conversational Voice Clone Challenge (CoVoC). We propose a LLaMA-based codec language model with a delay pattern to achieve spontaneous style voice cloning. To improve speech intelligibility, we introduce the Classifier-Free Guidance (CFG) strategy in the language model to strengthen conditional guidance on token prediction. To generate high-quality utterances, we adopt effective data preprocessing operations and fine-tune our model with selected high-quality spontaneous speech data. The official evaluations in the CoVoC constrained track show that our system achieves the best speech naturalness MOS of 3.80 and obtains considerable speech quality and speaker similarity results.
An End-to-End Approach for Chord-Conditioned Song Generation
Sep 10, 2024


The Song Generation task aims to synthesize music composed of vocals and accompaniment from given lyrics. While the existing method, Jukebox, has explored this task, its constrained control over the generations often leads to deficiency in music performance. To mitigate the issue, we introduce an important concept from music composition, namely chords, to song generation networks. Chords form the foundation of accompaniment and provide vocal melody with associated harmony. Given the inaccuracy of automatic chord extractors, we devise a robust cross-attention mechanism augmented with dynamic weight sequence to integrate extracted chord information into song generations and reduce frame-level flaws, and propose a novel model termed Chord-Conditioned Song Generator (CSG) based on it. Experimental evidence demonstrates our proposed method outperforms other approaches in terms of musical performance and control precision of generated songs.
SongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024



Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
VoxInstruct: Expressive Human Instruction-to-Speech Generation with Unified Multilingual Codec Language Modelling
Aug 28, 2024



Recent AIGC systems possess the capability to generate digital multimedia content based on human language instructions, such as text, image and video. However, when it comes to speech, existing methods related to human instruction-to-speech generation exhibit two limitations. Firstly, they require the division of inputs into content prompt (transcript) and description prompt (style and speaker), instead of directly supporting human instruction. This division is less natural in form and does not align with other AIGC models. Secondly, the practice of utilizing an independent description prompt to model speech style, without considering the transcript content, restricts the ability to control speech at a fine-grained level. To address these limitations, we propose VoxInstruct, a novel unified multilingual codec language modeling framework that extends traditional text-to-speech tasks into a general human instruction-to-speech task. Our approach enhances the expressiveness of human instruction-guided speech generation and aligns the speech generation paradigm with other modalities. To enable the model to automatically extract the content of synthesized speech from raw text instructions, we introduce speech semantic tokens as an intermediate representation for instruction-to-content guidance. We also incorporate multiple Classifier-Free Guidance (CFG) strategies into our codec language model, which strengthens the generated speech following human instructions. Furthermore, our model architecture and training strategies allow for the simultaneous support of combining speech prompt and descriptive human instruction for expressive speech synthesis, which is a first-of-its-kind attempt. Codes, models and demos are at: https://github.com/thuhcsi/VoxInstruct.
Foundation Models for Music: A Survey
Aug 27, 2024



In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
The THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Apr 25, 2024
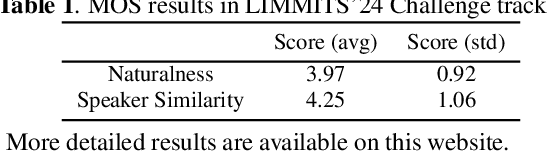
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.