 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Graph Structure in Seq2Seq Models for Knowledge Graph Link Prediction
May 18, 2026We introduce Graph-Augmented Sequence-to-Sequence (GA-S2S), a novel framework that integrates a T5-small encoder-decoder with a Relational Graph Attention Network (RGAT) to improve link prediction in knowledge graphs. While existing Seq2Seq models rely solely on surface-level textual descriptions of entities and relations and at best, flatten the neighborhoods of a query entity into a single linear sequence, thereby discarding the inherent graph structure, GA-S2S jointly encodes both textual features and the full $k$-hop subgraph topology surrounding the query entity. By integrating raw encoder outputs with RGAT's relation-aware embeddings, our model captures and leverages richer multi-hop relational patterns and textual information. Our preliminary experiments on the CoDEx dataset demonstrate that GA-S2S outperforms competitive Seq2Seq-based baseline models, achieving up to a 19\% relative gain in link prediction accuracy.
Analyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025



Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
SongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024



Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
DyGMamba: Efficiently Modeling Long-Term Temporal Dependency on Continuous-Time Dynamic Graphs with State Space Models
Aug 08, 2024



Learning useful representations for continuous-time dynamic graphs (CTDGs) is challenging, due to the concurrent need to span long node interaction histories and grasp nuanced temporal details. In particular, two problems emerge: (1) Encoding longer histories requires more computational resources, making it crucial for CTDG models to maintain low computational complexity to ensure efficiency; (2) Meanwhile, more powerful models are needed to identify and select the most critical temporal information within the extended context provided by longer histories. To address these problems, we propose a CTDG representation learning model named DyGMamba, originating from the popular Mamba state space model (SSM). DyGMamba first leverages a node-level SSM to encode the sequence of historical node interactions. Another time-level SSM is then employed to exploit the temporal patterns hidden in the historical graph, where its output is used to dynamically select the critical information from the interaction history. We validate DyGMamba experimentally on the dynamic link prediction task. The results show that our model achieves state-of-the-art in most cases. DyGMamba also maintains high efficiency in terms of computational resources, making it possible to capture long temporal dependencies with a limited computation budget.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024



While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
Exploring Link Prediction over Hyper-Relational Temporal Knowledge Graphs Enhanced with Time-Invariant Relational Knowledge
Jul 14, 2023Stemming from traditional knowledge graphs (KGs), hyper-relational KGs (HKGs) provide additional key-value pairs (i.e., qualifiers) for each KG fact that help to better restrict the fact validity. In recent years, there has been an increasing interest in studying graph reasoning over HKGs. In the meantime, due to the ever-evolving nature of world knowledge, extensive parallel works have been focusing on reasoning over temporal KGs (TKGs), where each TKG fact can be viewed as a KG fact coupled with a timestamp (or time period) specifying its time validity. The existing HKG reasoning approaches do not consider temporal information because it is not explicitly specified in previous benchmark datasets. Besides, all the previous TKG reasoning methods only lay emphasis on temporal reasoning and have no way to learn from qualifiers. To this end, we aim to fill the gap between TKG reasoning and HKG reasoning. We develop two new benchmark hyper-relational TKG (HTKG) datasets, i.e., Wiki-hy and YAGO-hy, and propose a HTKG reasoning model that efficiently models both temporal facts and qualifiers. We further exploit additional time-invariant relational knowledge from the Wikidata knowledge base and study its effectiveness in HTKG reasoning. Time-invariant relational knowledge serves as the knowledge that remains unchanged in time (e.g., Sasha Obama is the child of Barack Obama), and it has never been fully explored in previous TKG reasoning benchmarks and approaches. Experimental results show that our model substantially outperforms previous related methods on HTKG link prediction and can be enhanced by jointly leveraging both temporal and time-invariant relational knowledge.
Robustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022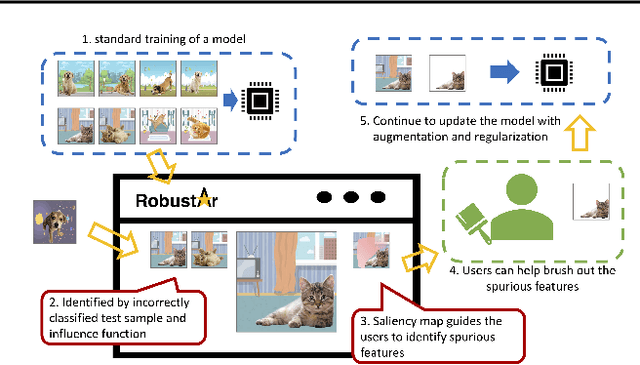
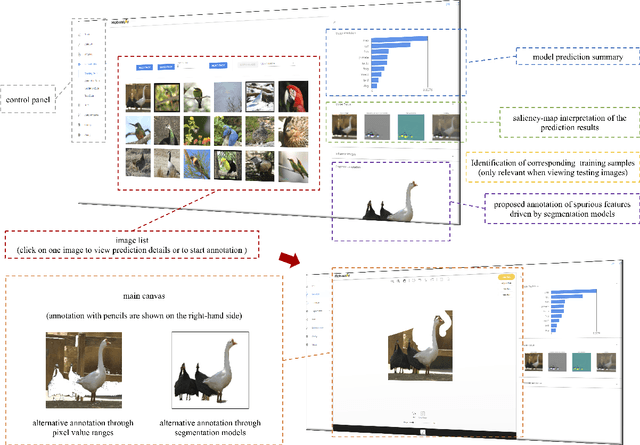
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.