 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Soccer Commentary Generation with Knowledge-Enhanced Visual Reasoning
Mar 31, 2026Soccer commentary plays a crucial role in enhancing the soccer game viewing experience for audiences. Previous studies in automatic soccer commentary generation typically adopt an end-to-end method to generate anonymous live text commentary. Such generated commentary is insufficient in the context of real-world live televised commentary, as it contains anonymous entities, context-dependent errors and lacks statistical insights of the game events. To bridge the gap, we propose GameSight, a two-stage model to address soccer commentary generation as a knowledge-enhanced visual reasoning task, enabling live-televised-like knowledgeable commentary with accurate reference to entities (players and teams). GameSight starts by performing visual reasoning to align anonymous entities with fine-grained visual and contextual analysis. Subsequently, the entity-aligned commentary is refined with knowledge by incorporating external historical statistics and iteratively updated internal game state information. Consequently, GameSight improves the player alignment accuracy by 18.5% on SN-Caption-test-align dataset compared to Gemini 2.5-pro. Combined with further knowledge enhancement, GameSight outperforms in segment-level accuracy and commentary quality, as well as game-level contextual relevance and structural composition. We believe that our work paves the way for a more informative and engaging human-centric experience with the AI sports application. Demo Page: https://gamesight2025.github.io/gamesight2025
VoxInstruct: Expressive Human Instruction-to-Speech Generation with Unified Multilingual Codec Language Modelling
Aug 28, 2024



Recent AIGC systems possess the capability to generate digital multimedia content based on human language instructions, such as text, image and video. However, when it comes to speech, existing methods related to human instruction-to-speech generation exhibit two limitations. Firstly, they require the division of inputs into content prompt (transcript) and description prompt (style and speaker), instead of directly supporting human instruction. This division is less natural in form and does not align with other AIGC models. Secondly, the practice of utilizing an independent description prompt to model speech style, without considering the transcript content, restricts the ability to control speech at a fine-grained level. To address these limitations, we propose VoxInstruct, a novel unified multilingual codec language modeling framework that extends traditional text-to-speech tasks into a general human instruction-to-speech task. Our approach enhances the expressiveness of human instruction-guided speech generation and aligns the speech generation paradigm with other modalities. To enable the model to automatically extract the content of synthesized speech from raw text instructions, we introduce speech semantic tokens as an intermediate representation for instruction-to-content guidance. We also incorporate multiple Classifier-Free Guidance (CFG) strategies into our codec language model, which strengthens the generated speech following human instructions. Furthermore, our model architecture and training strategies allow for the simultaneous support of combining speech prompt and descriptive human instruction for expressive speech synthesis, which is a first-of-its-kind attempt. Codes, models and demos are at: https://github.com/thuhcsi/VoxInstruct.
PlacidDreamer: Advancing Harmony in Text-to-3D Generation
Jul 19, 2024Recently, text-to-3D generation has attracted significant attention, resulting in notable performance enhancements. Previous methods utilize end-to-end 3D generation models to initialize 3D Gaussians, multi-view diffusion models to enforce multi-view consistency, and text-to-image diffusion models to refine details with score distillation algorithms. However, these methods exhibit two limitations. Firstly, they encounter conflicts in generation directions since different models aim to produce diverse 3D assets. Secondly, the issue of over-saturation in score distillation has not been thoroughly investigated and solved. To address these limitations, we propose PlacidDreamer, a text-to-3D framework that harmonizes initialization, multi-view generation, and text-conditioned generation with a single multi-view diffusion model, while simultaneously employing a novel score distillation algorithm to achieve balanced saturation. To unify the generation direction, we introduce the Latent-Plane module, a training-friendly plug-in extension that enables multi-view diffusion models to provide fast geometry reconstruction for initialization and enhanced multi-view images to personalize the text-to-image diffusion model. To address the over-saturation problem, we propose to view score distillation as a multi-objective optimization problem and introduce the Balanced Score Distillation algorithm, which offers a Pareto Optimal solution that achieves both rich details and balanced saturation. Extensive experiments validate the outstanding capabilities of our PlacidDreamer. The code is available at \url{https://github.com/HansenHuang0823/PlacidDreamer}.
Optimizing Chance-Constrained Submodular Problems with Variable Uncertainties
Sep 23, 2023Chance constraints are frequently used to limit the probability of constraint violations in real-world optimization problems where the constraints involve stochastic components. We study chance-constrained submodular optimization problems, which capture a wide range of optimization problems with stochastic constraints. Previous studies considered submodular problems with stochastic knapsack constraints in the case where uncertainties are the same for each item that can be selected. However, uncertainty levels are usually variable with respect to the different stochastic components in real-world scenarios, and rigorous analysis for this setting is missing in the context of submodular optimization. This paper provides the first such analysis for this case, where the weights of items have the same expectation but different dispersion. We present greedy algorithms that can obtain a high-quality solution, i.e., a constant approximation ratio to the given optimal solution from the deterministic setting. In the experiments, we demonstrate that the algorithms perform effectively on several chance-constrained instances of the maximum coverage problem and the influence maximization problem.
Nearest-Neighbour-Induced Isolation Similarity and its Impact on Density-Based Clustering
Jun 30, 2019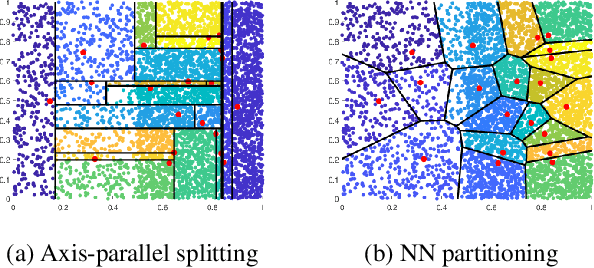
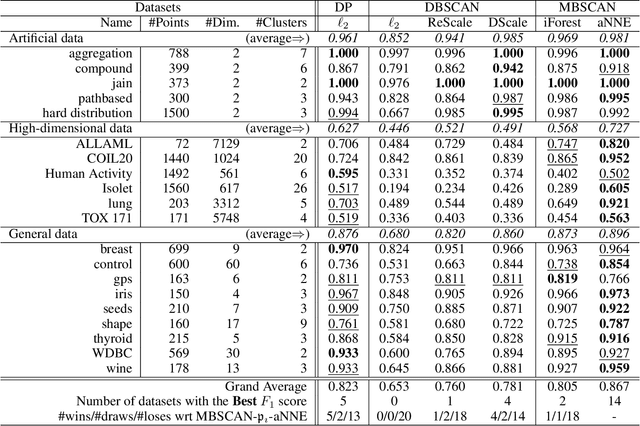
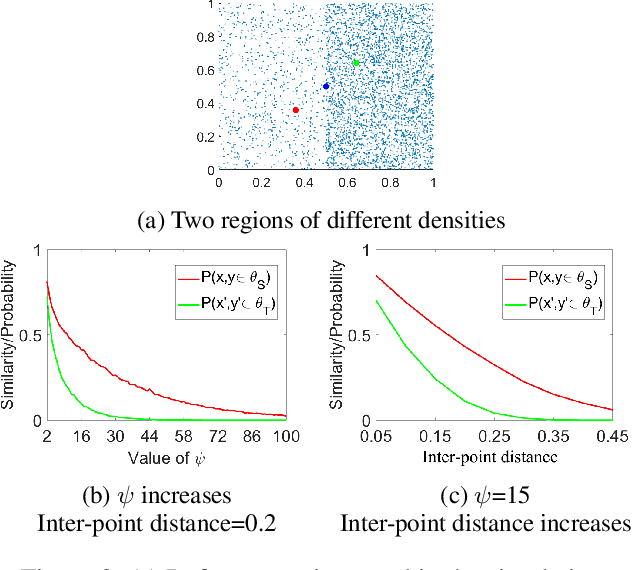

A recent proposal of data dependent similarity called Isolation Kernel/Similarity has enabled SVM to produce better classification accuracy. We identify shortcomings of using a tree method to implement Isolation Similarity; and propose a nearest neighbour method instead. We formally prove the characteristic of Isolation Similarity with the use of the proposed method. The impact of Isolation Similarity on density-based clustering is studied here. We show for the first time that the clustering performance of the classic density-based clustering algorithm DBSCAN can be significantly uplifted to surpass that of the recent density-peak clustering algorithm DP. This is achieved by simply replacing the distance measure with the proposed nearest-neighbour-induced Isolation Similarity in DBSCAN, leaving the rest of the procedure unchanged. A new type of clusters called mass-connected clusters is formally defined. We show that DBSCAN, which detects density-connected clusters, becomes one which detects mass-connected clusters, when the distance measure is replaced with the proposed similarity. We also provide the condition under which mass-connected clusters can be detected, while density-connected clusters cannot.