 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-free and Training-free Compression for Speech Foundation Models Using Parameter Clustering
Jun 11, 2026This paper presents a novel data-free and training-free compression approach for speech foundation models using channelwise clustering via k-means. More fine-grained, mixed sparsity pruning by layer-level varying number of parameter clusters is also explored. Experiments conducted on the LibriSpeech dataset suggest that when operating with pruning sparsity of 50% on HuBERT-large, consistent WER reductions of 27.73%/18.61% absolute (34.37%/21.91% relative) over the magnitude-based pruning were obtained on the test-clean and test-other subsets before fine-tuning and 0.19%/0.79% absolute (3.36%/4.62% relative) after fine-tuning with only 3 epochs. Similar WER reductions of 2.86%/5.02% absolute (59.21%/55.29% relative) were observed against magnitudebased pruning on Whisper-large-v3 at 10% sparsity, all with no significant WER increase relative to the uncompressed baseline.
UNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
May 29, 2026We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
Beyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
May 12, 2026Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation
Dec 29, 2025Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
ZipVoice: Fast and High-Quality Zero-Shot Text-to-Speech with Flow Matching
Jun 16, 2025Existing large-scale zero-shot text-to-speech (TTS) models deliver high speech quality but suffer from slow inference speeds due to massive parameters. To address this issue, this paper introduces ZipVoice, a high-quality flow-matching-based zero-shot TTS model with a compact model size and fast inference speed. Key designs include: 1) a Zipformer-based flow-matching decoder to maintain adequate modeling capabilities under constrained size; 2) Average upsampling-based initial speech-text alignment and Zipformer-based text encoder to improve speech intelligibility; 3) A flow distillation method to reduce sampling steps and eliminate the inference overhead associated with classifier-free guidance. Experiments on 100k hours multilingual datasets show that ZipVoice matches state-of-the-art models in speech quality, while being 3 times smaller and up to 30 times faster than a DiT-based flow-matching baseline. Codes, model checkpoints and demo samples are publicly available.
Effective and Efficient One-pass Compression of Speech Foundation Models Using Sparsity-aware Self-pinching Gates
May 28, 2025



This paper presents a novel approach for speech foundation models compression that tightly integrates model pruning and parameter update into a single stage. Highly compact layer-level tied self-pinching gates each containing only a single learnable threshold are jointly trained with uncompressed models and used in fine-grained neuron level pruning. Experiments conducted on the LibriSpeech-100hr corpus suggest that our approach reduces the number of parameters of wav2vec2.0-base and HuBERT-large models by 65% and 60% respectively, while incurring no statistically significant word error rate (WER) increase on the test-clean dataset. Compared to previously published methods on the same task, our approach not only achieves the lowest WER of 7.05% on the test-clean dataset under a comparable model compression ratio of 4.26x, but also operates with at least 25% less model compression time.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models
May 27, 2025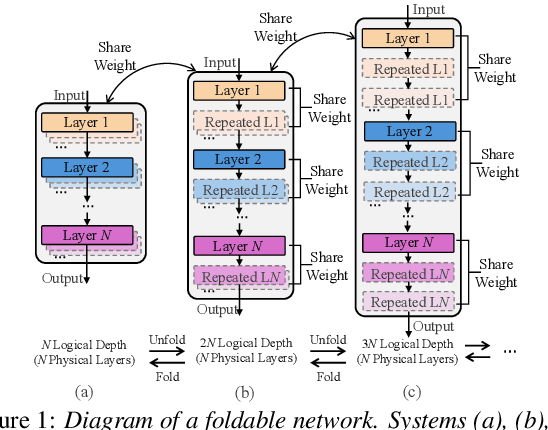
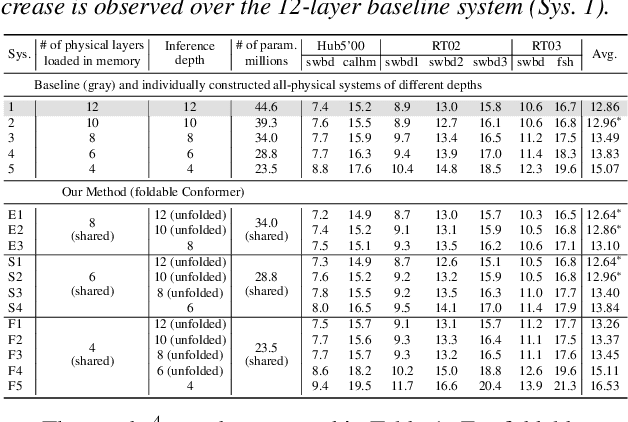
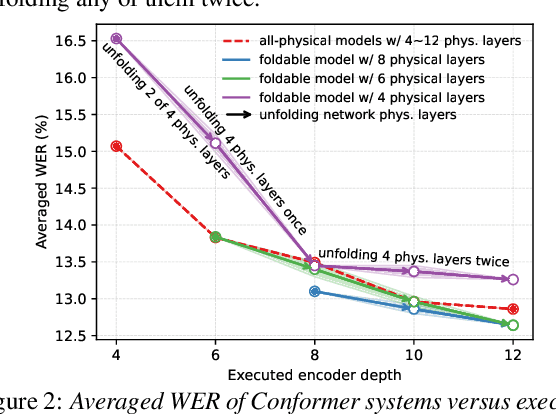
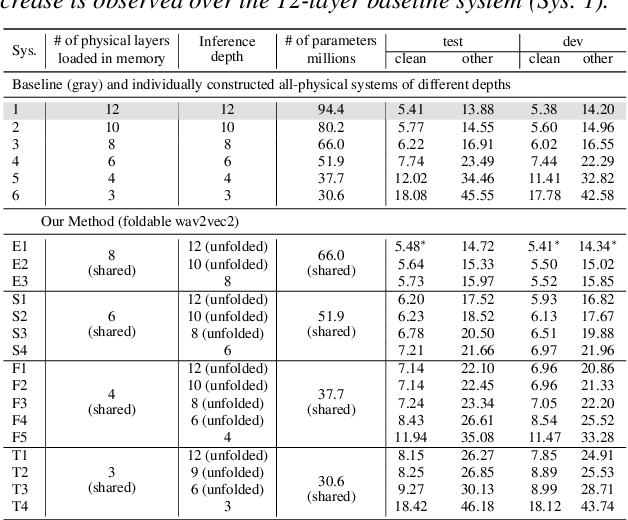
This paper presents a novel memory-efficient model compression approach for Conformer ASR and speech foundation systems. Our approach features a unique "small-to-large" design. A compact "seed" model containing a few Conformer or Transformer blocks is trained and unfolded many times to emulate the performance of larger uncompressed models with different logical depths. The seed model and many unfolded paths are jointly trained within a single unfolding cycle. The KL-divergence between the largest unfolded and smallest seed models is used in a self-distillation process to minimize their performance disparity. Experimental results show that our foldable model produces ASR performance comparable to individually constructed Conformer and wav2vec2/HuBERT speech foundation models under various depth configurations, while requiring only minimal memory and storage. Conformer and wav2vec2 models with a reduction of 35% and 30% parameters are obtained without loss of performance, respectively.
Automated Heterogeneous Network learning with Non-Recursive Message Passing
Jan 10, 2025Heterogeneous information networks (HINs) can be used to model various real-world systems. As HINs consist of multiple types of nodes, edges, and node features, it is nontrivial to directly apply graph neural network (GNN) techniques in heterogeneous cases. There are two remaining major challenges. First, homogeneous message passing in a recursive manner neglects the distinct types of nodes and edges in different hops, leading to unnecessary information mixing. This often results in the incorporation of ``noise'' from uncorrelated intermediate neighbors, thereby degrading performance. Second, feature learning should be handled differently for different types, which is challenging especially when the type sizes are large. To bridge this gap, we develop a novel framework - AutoGNR, to directly utilize and automatically extract effective heterogeneous information. Instead of recursive homogeneous message passing, we introduce a non-recursive message passing mechanism for GNN to mitigate noise from uncorrelated node types in HINs. Furthermore, under the non-recursive framework, we manage to efficiently perform neural architecture search for an optimal GNN structure in a differentiable way, which can automatically define the heterogeneous paths for aggregation. Our tailored search space encompasses more effective candidates while maintaining a tractable size. Experiments show that AutoGNR consistently outperforms state-of-the-art methods on both normal and large scale real-world HIN datasets.
Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition
Jan 08, 2025



Discrete tokens extracted provide efficient and domain adaptable speech features. Their application to disordered speech that exhibits articulation imprecision and large mismatch against normal voice remains unexplored. To improve their phonetic discrimination that is weakened during unsupervised K-means or vector quantization of continuous features, this paper proposes novel phone-purity guided (PPG) discrete tokens for dysarthric speech recognition. Phonetic label supervision is used to regularize maximum likelihood and reconstruction error costs used in standard K-means and VAE-VQ based discrete token extraction. Experiments conducted on the UASpeech corpus suggest that the proposed PPG discrete token features extracted from HuBERT consistently outperform hybrid TDNN and End-to-End (E2E) Conformer systems using non-PPG based K-means or VAE-VQ tokens across varying codebook sizes by statistically significant word error rate (WER) reductions up to 0.99\% and 1.77\% absolute (3.21\% and 4.82\% relative) respectively on the UASpeech test set of 16 dysarthric speakers. The lowest WER of 23.25\% was obtained by combining systems using different token features. Consistent improvements on the phone purity metric were also achieved. T-SNE visualization further demonstrates sharper decision boundaries were produced between K-means/VAE-VQ clusters after introducing phone-purity guidance.