 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
Paper and Code
May 30, 2025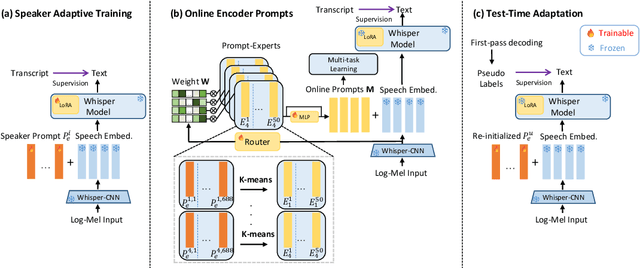
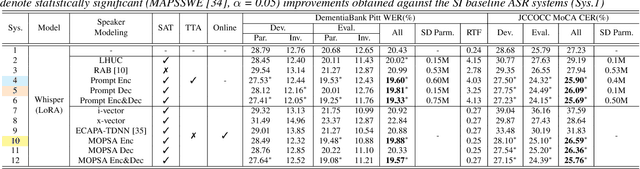
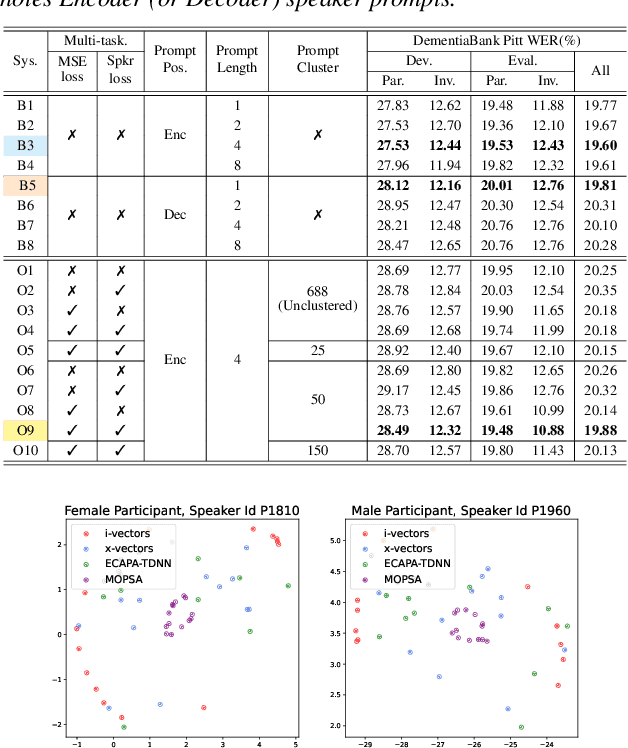
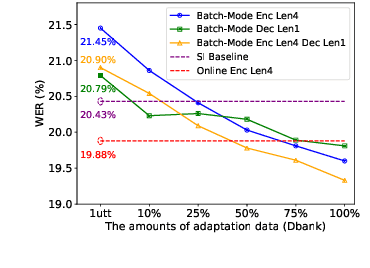
This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.