 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-Empowered Fine-Grained Speech Descriptors for Explainable Emotion Recognition
Paper and Code
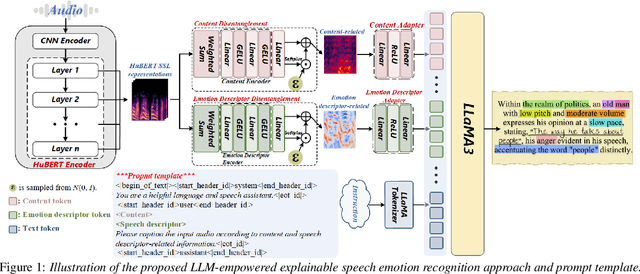
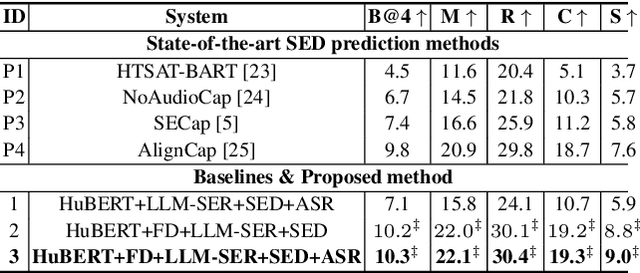
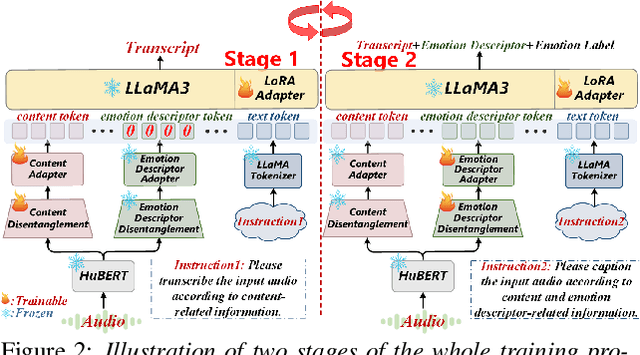
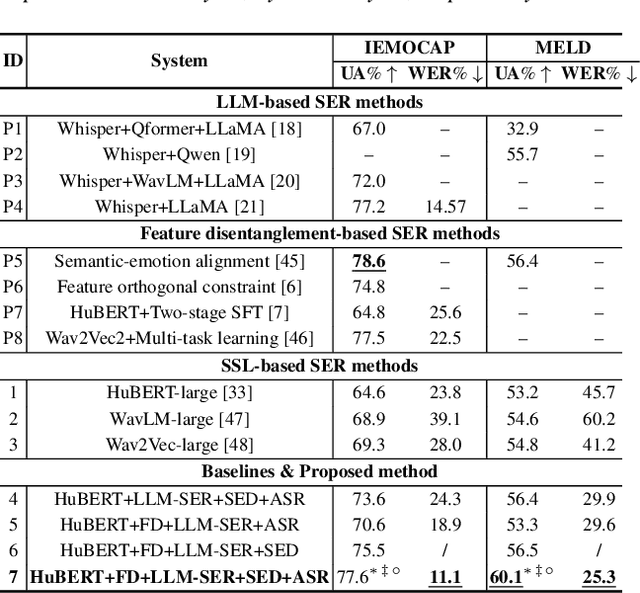
This paper presents a novel end-to-end LLM-empowered explainable speech emotion recognition (SER) approach. Fine-grained speech emotion descriptor (SED) features, e.g., pitch, tone and emphasis, are disentangled from HuBERT SSL representations via alternating LLM fine-tuning to joint SER-SED prediction and ASR tasks. VAE compressed HuBERT features derived via Information Bottleneck (IB) are used to adjust feature granularity. Experiments on the IEMOCAP and MELD benchmarks demonstrate that our approach consistently outperforms comparable LLaMA-based SER baselines, including those using either (a) alternating multi-task fine-tuning alone or (b) feature disentanglement only. Statistically significant increase of SER unweighted accuracy by up to 4.0% and 3.7% absolute (5.4% and 6.6% relative) are obtained. More importantly, emotion descriptors offer further explainability for SER.