 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Induced Label Propagation by Mapping for Semi-Supervised Classification
May 31, 2019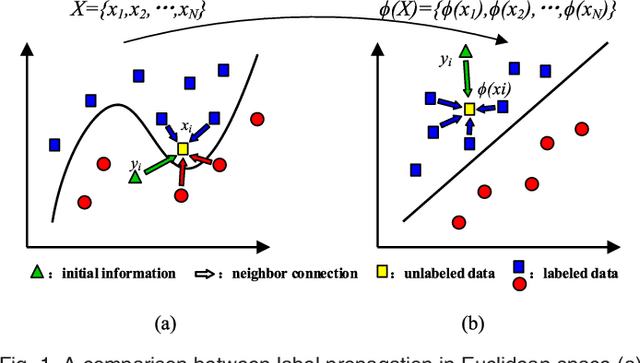
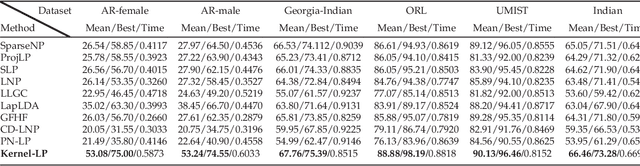
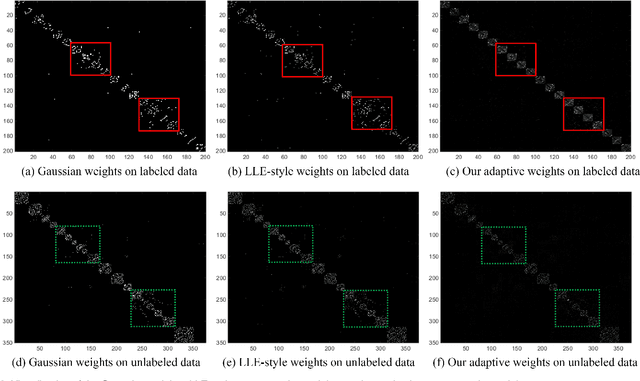
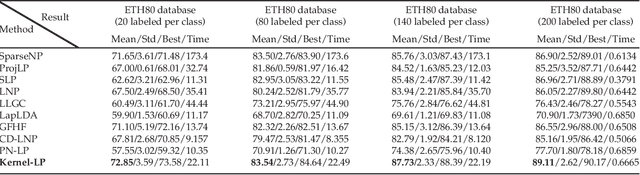
Kernel methods have been successfully applied to the areas of pattern recognition and data mining. In this paper, we mainly discuss the issue of propagating labels in kernel space. A Kernel-Induced Label Propagation (Kernel-LP) framework by mapping is proposed for high-dimensional data classification using the most informative patterns of data in kernel space. The essence of Kernel-LP is to perform joint label propagation and adaptive weight learning in a transformed kernel space. That is, our Kernel-LP changes the task of label propagation from the commonly-used Euclidean space in most existing work to kernel space. The motivation of our Kernel-LP to propagate labels and learn the adaptive weights jointly by the assumption of an inner product space of inputs, i.e., the original linearly inseparable inputs may be mapped to be separable in kernel space. Kernel-LP is based on existing positive and negative LP model, i.e., the effects of negative label information are integrated to improve the label prediction power. Also, Kernel-LP performs adaptive weight construction over the same kernel space, so it can avoid the tricky process of choosing the optimal neighborhood size suffered in traditional criteria. Two novel and efficient out-of-sample approaches for our Kernel-LP to involve new test data are also presented, i.e., (1) direct kernel mapping and (2) kernel mapping-induced label reconstruction, both of which purely depend on the kernel matrix between training set and testing set. Owing to the kernel trick, our algorithms will be applicable to handle the high-dimensional real data. Extensive results on real datasets demonstrate the effectiveness of our approach.
Jointly Learning Structured Analysis Discriminative Dictionary and Analysis Multiclass Classifier
May 27, 2019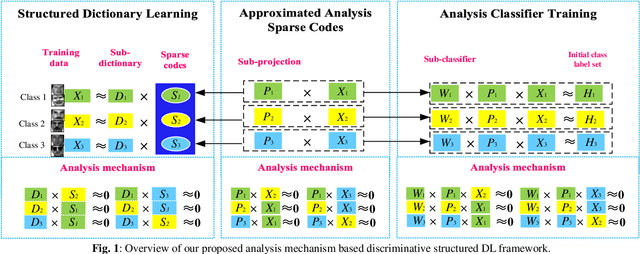
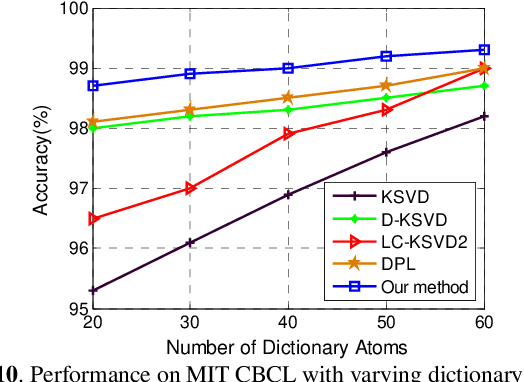
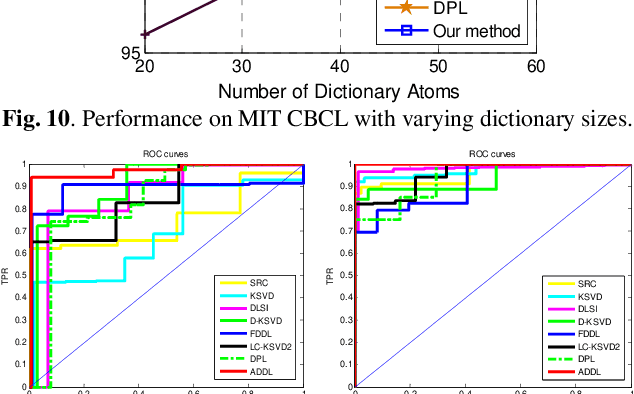

In this paper, we propose an analysis mechanism based structured Analysis Discriminative Dictionary Learning (ADDL) framework. ADDL seamlessly integrates the analysis discriminative dictionary learning, analysis representation and analysis classifier training into a unified model. The applied analysis mechanism can make sure that the learnt dictionaries, representations and linear classifiers over different classes are independent and discriminating as much as possible. The dictionary is obtained by minimizing a reconstruction error and an analytical incoherence promoting term that encourages the sub-dictionaries associated with different classes to be independent. To obtain the representation coefficients, ADDL imposes a sparse l2,1-norm constraint on the coding coefficients instead of using l0 or l1-norm, since the l0 or l1-norm constraint applied in most existing DL criteria makes the training phase time consuming. The codes-extraction projection that bridges data with the sparse codes by extracting special features from the given samples is calculated via minimizing a sparse codes approximation term. Then we compute a linear classifier based on the approximated sparse codes by an analysis mechanism to simultaneously consider the classification and representation powers. Thus, the classification approach of our model is very efficient, because it can avoid the extra time-consuming sparse reconstruction process with trained dictionary for each new test data as most existing DL algorithms. Simulations on real image databases demonstrate that our ADDL model can obtain superior performance over other state-of-the-arts.
Joint Label Prediction based Semi-Supervised Adaptive Concept Factorization for Robust Data Representation
May 25, 2019
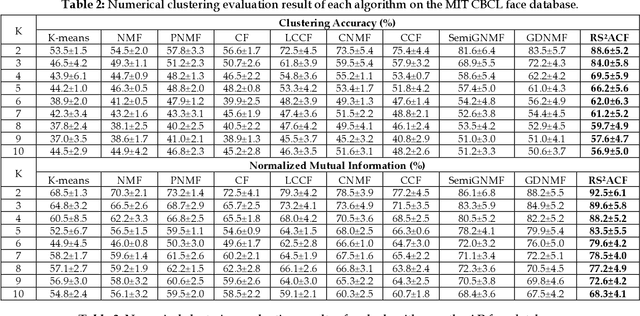
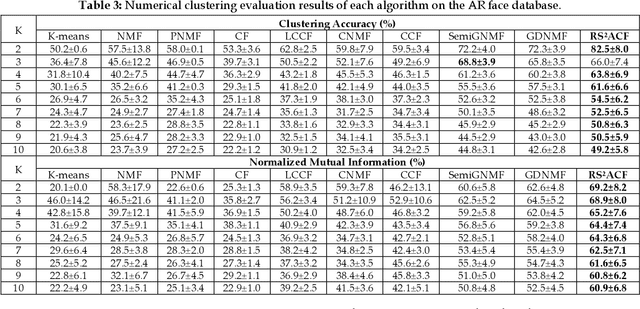
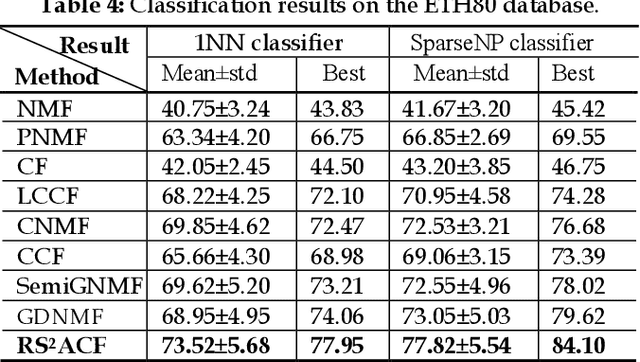
Constrained Concept Factorization (CCF) yields the enhanced representation ability over CF by incorporating label information as additional constraints, but it cannot classify and group unlabeled data appropriately. Minimizing the difference between the original data and its reconstruction directly can enable CCF to model a small noisy perturbation, but is not robust to gross sparse errors. Besides, CCF cannot preserve the manifold structures in new representation space explicitly, especially in an adaptive manner. In this paper, we propose a joint label prediction based Robust Semi-Supervised Adaptive Concept Factorization (RS2ACF) framework. To obtain robust representation, RS2ACF relaxes the factorization to make it simultaneously stable to small entrywise noise and robust to sparse errors. To enrich prior knowledge to enhance the discrimination, RS2ACF clearly uses class information of labeled data and more importantly propagates it to unlabeled data by jointly learning an explicit label indicator for unlabeled data. By the label indicator, RS2ACF can ensure the unlabeled data of the same predicted label to be mapped into the same class in feature space. Besides, RS2ACF incorporates the joint neighborhood reconstruction error over the new representations and predicted labels of both labeled and unlabeled data, so the manifold structures can be preserved explicitly and adaptively in the representation space and label space at the same time. Owing to the adaptive manner, the tricky process of determining the neighborhood size or kernel width can be avoided. Extensive results on public databases verify that our RS2ACF can deliver state-of-the-art data representation, compared with other related methods.
* Accepted at IEEE TKDE
Robust Unsupervised Flexible Auto-weighted Local-Coordinate Concept Factorization for Image Clustering
May 25, 2019
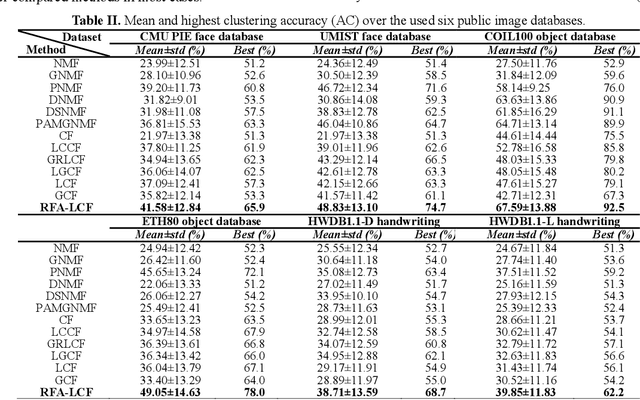
We investigate the high-dimensional data clustering problem by proposing a novel and unsupervised representation learning model called Robust Flexible Auto-weighted Local-coordinate Concept Factorization (RFA-LCF). RFA-LCF integrates the robust flexible CF, robust sparse local-coordinate coding and the adaptive reconstruction weighting learning into a unified model. The adaptive weighting is driven by including the joint manifold preserving constraints on the recovered clean data, basis concepts and new representation. Specifically, our RFA-LCF uses a L2,1-norm based flexible residue to encode the mismatch between clean data and its reconstruction, and also applies the robust adaptive sparse local-coordinate coding to represent the data using a few nearby basis concepts, which can make the factorization more accurate and robust to noise. The robust flexible factorization is also performed in the recovered clean data space for enhancing representations. RFA-LCF also considers preserving the local manifold structures of clean data space, basis concept space and the new coordinate space jointly in an adaptive manner way. Extensive comparisons show that RFA-LCF can deliver enhanced clustering results.
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Apr 30, 2019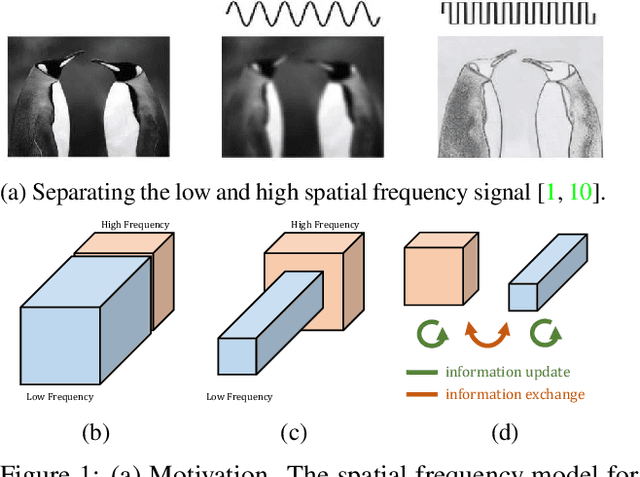

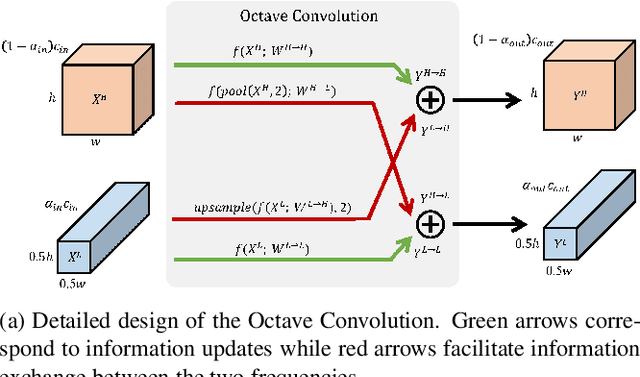
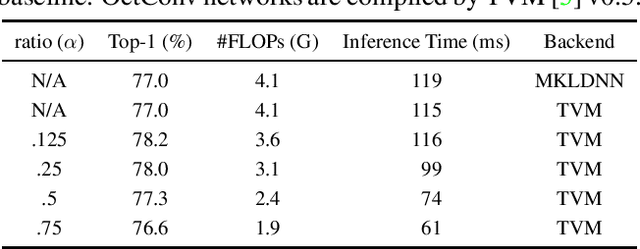
In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
Multi-Prototype Networks for Unconstrained Set-based Face Recognition
Mar 23, 2019
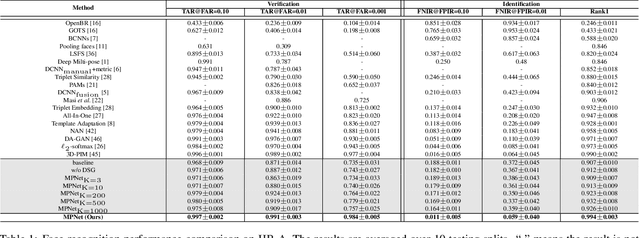
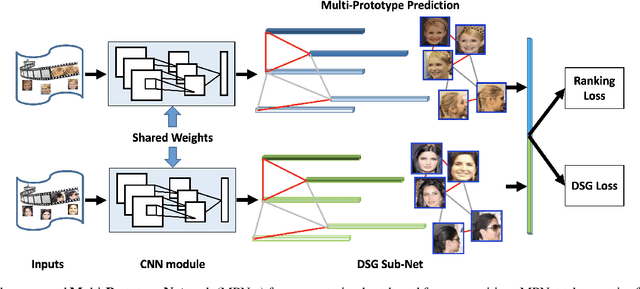
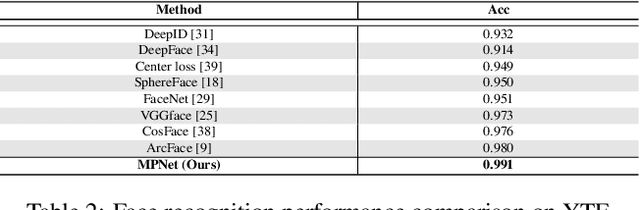
In this paper, we study the challenging unconstrained set-based face recognition problem where each subject face is instantiated by a set of media (images and videos) instead of a single image. Naively aggregating information from all the media within a set would suffer from the large intra-set variance caused by heterogeneous factors (e.g., varying media modalities, poses and illuminations) and fail to learn discriminative face representations. A novel Multi-Prototype Network (MPNet) model is thus proposed to learn multiple prototype face representations adaptively from the media sets. Each learned prototype is representative for the subject face under certain condition in terms of pose, illumination and media modality. Instead of handcrafting the set partition for prototype learning, MPNet introduces a Dense SubGraph (DSG) learning sub-net that implicitly untangles inconsistent media and learns a number of representative prototypes. Qualitative and quantitative experiments clearly demonstrate superiority of the proposed model over state-of-the-arts.
Graph-Based Global Reasoning Networks
Nov 30, 2018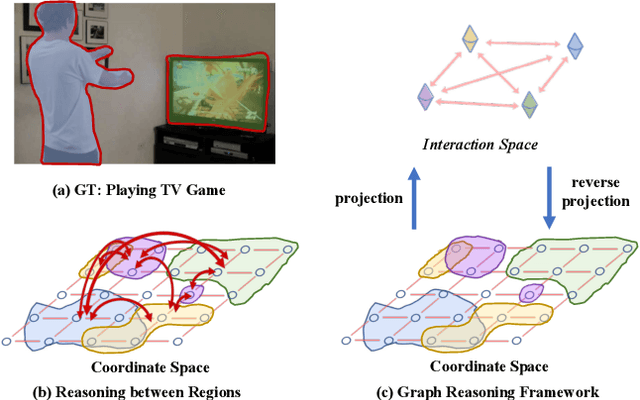
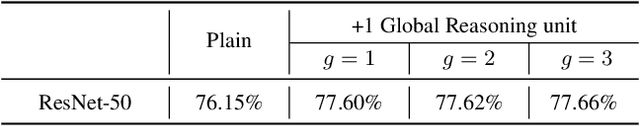
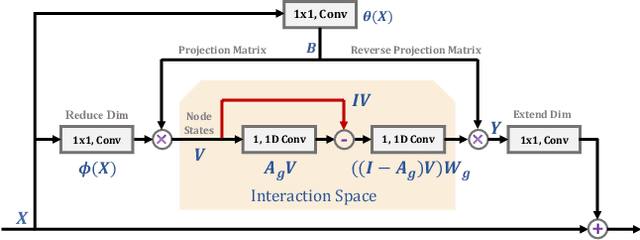
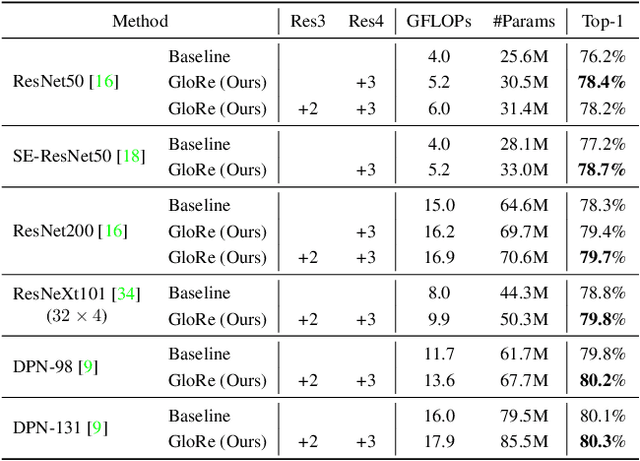
Globally modeling and reasoning over relations between regions can be beneficial for many computer vision tasks on both images and videos. Convolutional Neural Networks (CNNs) excel at modeling local relations by convolution operations, but they are typically inefficient at capturing global relations between distant regions and require stacking multiple convolution layers. In this work, we propose a new approach for reasoning globally in which a set of features are globally aggregated over the coordinate space and then projected to an interaction space where relational reasoning can be efficiently computed. After reasoning, relation-aware features are distributed back to the original coordinate space for down-stream tasks. We further present a highly efficient instantiation of the proposed approach and introduce the Global Reasoning unit (GloRe unit) that implements the coordinate-interaction space mapping by weighted global pooling and weighted broadcasting, and the relation reasoning via graph convolution on a small graph in interaction space. The proposed GloRe unit is lightweight, end-to-end trainable and can be easily plugged into existing CNNs for a wide range of tasks. Extensive experiments show our GloRe unit can consistently boost the performance of state-of-the-art backbone architectures, including ResNet, ResNeXt, SE-Net and DPN, for both 2D and 3D CNNs, on image classification, semantic segmentation and video action recognition task.
Style Separation and Synthesis via Generative Adversarial Networks
Nov 07, 2018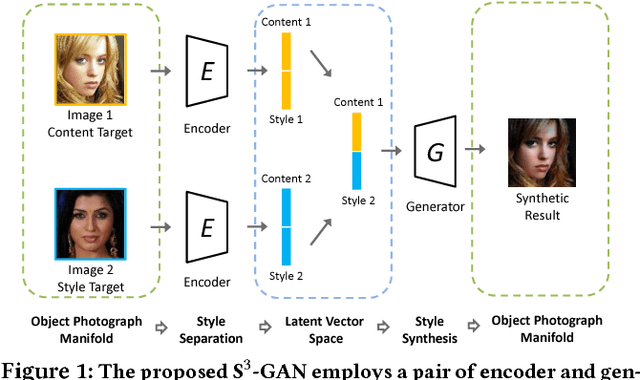
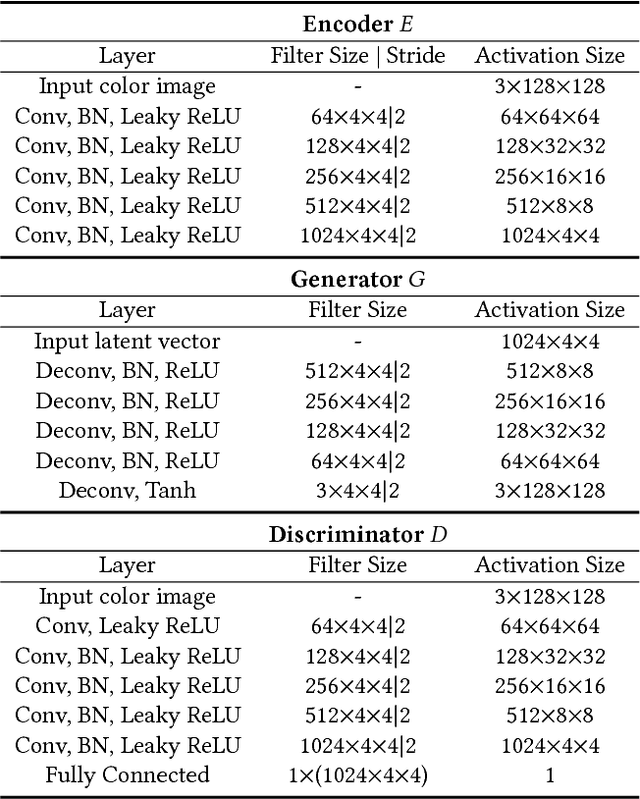
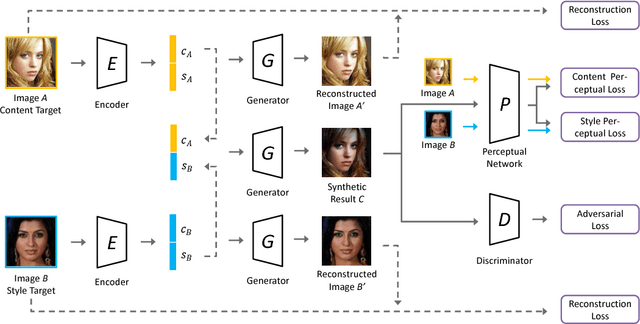
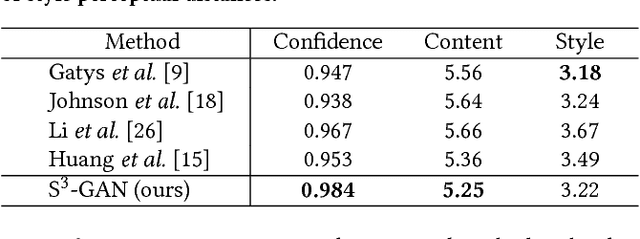
Style synthesis attracts great interests recently, while few works focus on its dual problem "style separation". In this paper, we propose the Style Separation and Synthesis Generative Adversarial Network (S3-GAN) to simultaneously implement style separation and style synthesis on object photographs of specific categories. Based on the assumption that the object photographs lie on a manifold, and the contents and styles are independent, we employ S3-GAN to build mappings between the manifold and a latent vector space for separating and synthesizing the contents and styles. The S3-GAN consists of an encoder network, a generator network, and an adversarial network. The encoder network performs style separation by mapping an object photograph to a latent vector. Two halves of the latent vector represent the content and style, respectively. The generator network performs style synthesis by taking a concatenated vector as input. The concatenated vector contains the style half vector of the style target image and the content half vector of the content target image. Once obtaining the images from the generator network, an adversarial network is imposed to generate more photo-realistic images. Experiments on CelebA and UT Zappos 50K datasets demonstrate that the S3-GAN has the capacity of style separation and synthesis simultaneously, and could capture various styles in a single model.
$A^2$-Nets: Double Attention Networks
Oct 27, 2018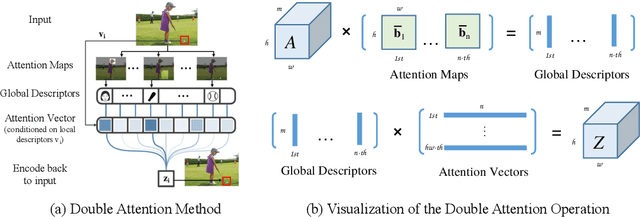
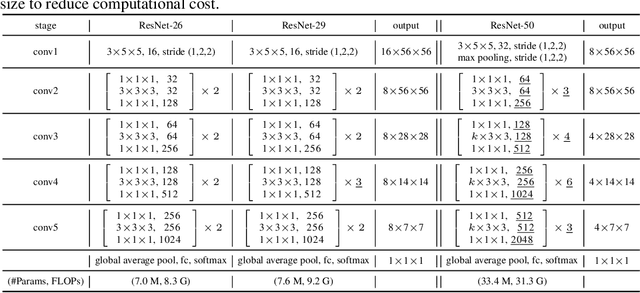
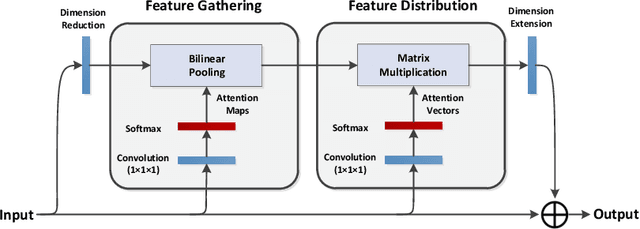
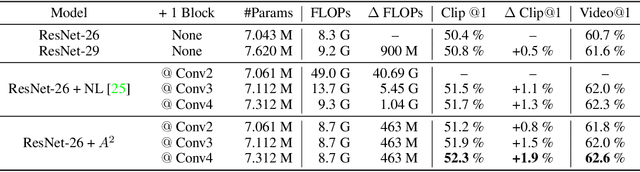
Learning to capture long-range relations is fundamental to image/video recognition. Existing CNN models generally rely on increasing depth to model such relations which is highly inefficient. In this work, we propose the "double attention block", a novel component that aggregates and propagates informative global features from the entire spatio-temporal space of input images/videos, enabling subsequent convolution layers to access features from the entire space efficiently. The component is designed with a double attention mechanism in two steps, where the first step gathers features from the entire space into a compact set through second-order attention pooling and the second step adaptively selects and distributes features to each location via another attention. The proposed double attention block is easy to adopt and can be plugged into existing deep neural networks conveniently. We conduct extensive ablation studies and experiments on both image and video recognition tasks for evaluating its performance. On the image recognition task, a ResNet-50 equipped with our double attention blocks outperforms a much larger ResNet-152 architecture on ImageNet-1k dataset with over 40% less the number of parameters and less FLOPs. On the action recognition task, our proposed model achieves the state-of-the-art results on the Kinetics and UCF-101 datasets with significantly higher efficiency than recent works.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018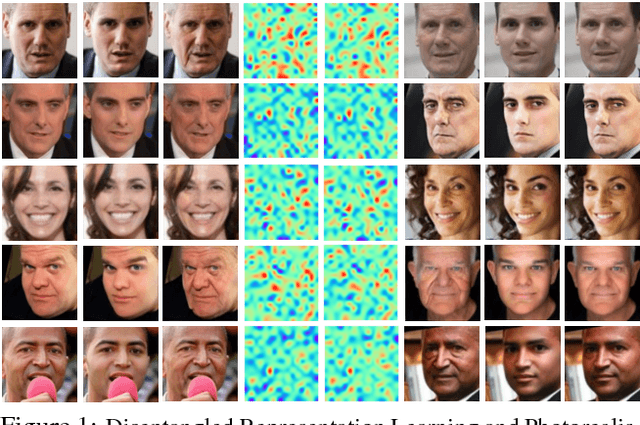
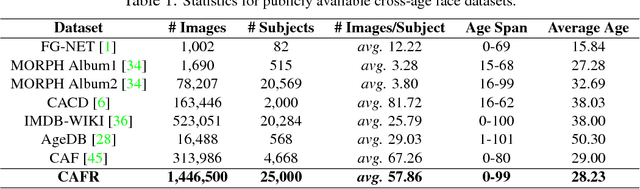
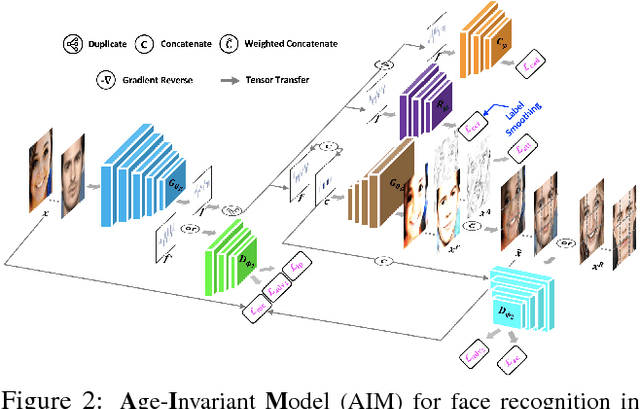
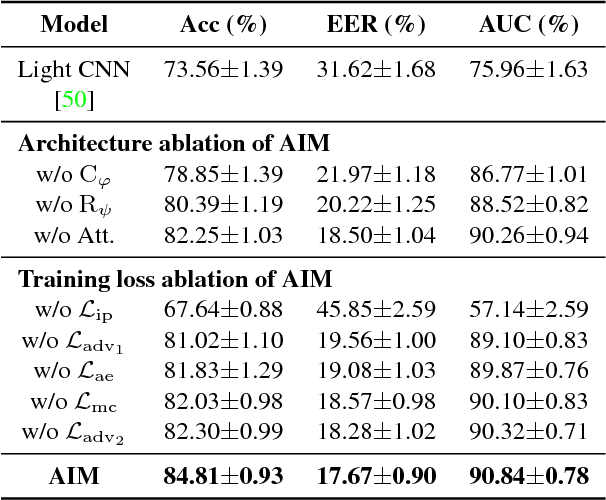
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.