 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Lifting: Neural Urban Semantic and Building Instance Lifting from Aerial Imagery
Mar 18, 2024



We present a neural radiance field method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D. This is a challenging problem due to two primary reasons. Firstly, objects in urban aerial images exhibit substantial variations in size, including buildings, cars, and roads, which pose a significant challenge for accurate 2D segmentation. Secondly, the 2D labels generated by existing segmentation methods suffer from the multi-view inconsistency problem, especially in the case of aerial images, where each image captures only a small portion of the entire scene. To overcome these limitations, we first introduce a scale-adaptive semantic label fusion strategy that enhances the segmentation of objects of varying sizes by combining labels predicted from different altitudes, harnessing the novel-view synthesis capabilities of NeRF. We then introduce a novel cross-view instance label grouping strategy based on the 3D scene representation to mitigate the multi-view inconsistency problem in the 2D instance labels. Furthermore, we exploit multi-view reconstructed depth priors to improve the geometric quality of the reconstructed radiance field, resulting in enhanced segmentation results. Experiments on multiple real-world urban-scale datasets demonstrate that our approach outperforms existing methods, highlighting its effectiveness.
Generating, Reconstructing, and Representing Discrete and Continuous Data: Generalized Diffusion with Learnable Encoding-Decoding
Feb 29, 2024The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), autoregressive models, and diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce generalized diffusion with learnable encoder-decoder (DiLED), that seamlessly integrates the core capabilities for broad applicability and enhanced performance. DiLED generalizes the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, DiLED is compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), DiLED naturally applies to different data types. Extensive experiments on text, proteins, and images demonstrate DiLED's flexibility to handle diverse data and tasks and its strong improvement over various existing models.
Fast and Accurate Cooperative Radio Map Estimation Enabled by GAN
Feb 05, 2024



In the 6G era, real-time radio resource monitoring and management are urged to support diverse wireless-empowered applications. This calls for fast and accurate estimation on the distribution of the radio resources, which is usually represented by the spatial signal power strength over the geographical environment, known as a radio map. In this paper, we present a cooperative radio map estimation (CRME) approach enabled by the generative adversarial network (GAN), called as GAN-CRME, which features fast and accurate radio map estimation without the transmitters' information. The radio map is inferred by exploiting the interaction between distributed received signal strength (RSS) measurements at mobile users and the geographical map using a deep neural network estimator, resulting in low data-acquisition cost and computational complexity. Moreover, a GAN-based learning algorithm is proposed to boost the inference capability of the deep neural network estimator by exploiting the power of generative AI. Simulation results showcase that the proposed GAN-CRME is even capable of coarse error-correction when the geographical map information is inaccurate.
Large Language Model Adaptation for Networking
Feb 04, 2024Many networking tasks now employ deep learning (DL) to solve complex prediction and system optimization problems. However, current design philosophy of DL-based algorithms entails intensive engineering overhead due to the manual design of deep neural networks (DNNs) for different networking tasks. Besides, DNNs tend to achieve poor generalization performance on unseen data distributions/environments. Motivated by the recent success of large language models (LLMs), for the first time, this work studies the LLM adaptation for networking to explore a more sustainable design philosophy. With the massive pre-trained knowledge and powerful inference ability, LLM can serve as the foundation model, and is expected to achieve "one model for all" with even better performance and stronger generalization for various tasks. In this paper, we present NetLLM, the first LLM adaptation framework that efficiently adapts LLMs to solve networking problems. NetLLM addresses many practical challenges in LLM adaptation, from how to process task-specific information with LLMs, to how to improve the efficiency of answer generation and acquiring domain knowledge for networking. Across three networking-related use cases - viewport prediction (VP), adaptive bitrate streaming (ABR) and cluster job scheduling (CJS), we showcase the effectiveness of NetLLM in LLM adaptation for networking. Results show that the adapted LLM surpasses state-of-the-art algorithms by 10.1-36.6% for VP, 14.5-36.6% for ABR, 6.8-41.3% for CJS, and also achieves superior generalization performance.
Scalable Federated Unlearning via Isolated and Coded Sharding
Jan 29, 2024



Federated unlearning has emerged as a promising paradigm to erase the client-level data effect without affecting the performance of collaborative learning models. However, the federated unlearning process often introduces extensive storage overhead and consumes substantial computational resources, thus hindering its implementation in practice. To address this issue, this paper proposes a scalable federated unlearning framework based on isolated sharding and coded computing. We first divide distributed clients into multiple isolated shards across stages to reduce the number of clients being affected. Then, to reduce the storage overhead of the central server, we develop a coded computing mechanism by compressing the model parameters across different shards. In addition, we provide the theoretical analysis of time efficiency and storage effectiveness for the isolated and coded sharding. Finally, extensive experiments on two typical learning tasks, i.e., classification and generation, demonstrate that our proposed framework can achieve better performance than three state-of-the-art frameworks in terms of accuracy, retraining time, storage overhead, and F1 scores for resisting membership inference attacks.
A Survey on Indoor Visible Light Positioning Systems: Fundamentals, Applications, and Challenges
Jan 25, 2024



The growing demand for location-based services in areas like virtual reality, robot control, and navigation has intensified the focus on indoor localization. Visible light positioning (VLP), leveraging visible light communications (VLC), becomes a promising indoor positioning technology due to its high accuracy and low cost. This paper provides a comprehensive survey of VLP systems. In particular, since VLC lays the foundation for VLP, we first present a detailed overview of the principles of VLC. The performance of each positioning algorithm is also compared in terms of various metrics such as accuracy, coverage, and orientation limitation. Beyond the physical layer studies, the network design for a VLP system is also investigated, including multi-access technologies resource allocation, and light-emitting diode (LED) placements. Next, the applications of the VLP systems are overviewed. Finally, this paper outlines open issues, challenges, and future research directions for the research field. In a nutshell, this paper constitutes the first holistic survey on VLP from state-of-the-art studies to practical uses.
ECC-PolypDet: Enhanced CenterNet with Contrastive Learning for Automatic Polyp Detection
Jan 10, 2024



Accurate polyp detection is critical for early colorectal cancer diagnosis. Although remarkable progress has been achieved in recent years, the complex colon environment and concealed polyps with unclear boundaries still pose severe challenges in this area. Existing methods either involve computationally expensive context aggregation or lack prior modeling of polyps, resulting in poor performance in challenging cases. In this paper, we propose the Enhanced CenterNet with Contrastive Learning (ECC-PolypDet), a two-stage training \& end-to-end inference framework that leverages images and bounding box annotations to train a general model and fine-tune it based on the inference score to obtain a final robust model. Specifically, we conduct Box-assisted Contrastive Learning (BCL) during training to minimize the intra-class difference and maximize the inter-class difference between foreground polyps and backgrounds, enabling our model to capture concealed polyps. Moreover, to enhance the recognition of small polyps, we design the Semantic Flow-guided Feature Pyramid Network (SFFPN) to aggregate multi-scale features and the Heatmap Propagation (HP) module to boost the model's attention on polyp targets. In the fine-tuning stage, we introduce the IoU-guided Sample Re-weighting (ISR) mechanism to prioritize hard samples by adaptively adjusting the loss weight for each sample during fine-tuning. Extensive experiments on six large-scale colonoscopy datasets demonstrate the superiority of our model compared with previous state-of-the-art detectors.
Integrated Sensing, Communication, and Powering (ISCAP): Towards Multi-functional 6G Wireless Networks
Jan 07, 2024



This article presents a novel multi-functional system for a sixth-generation (6G) wireless network with integrated sensing, communication, and powering (ISCAP), which unifies integrated sensing and communication (ISAC) and wireless information and power transfer (WIPT) techniques. The multi-functional ISCAP network promises to enhance resource utilization efficiency, reduce network costs, and improve overall performance through versatile operational modes. Specifically, a multi-functional base station (BS) can enable multi-functional transmission, by exploiting the same radio signals to perform target/environment sensing, wireless communication, and wireless power transfer (WPT), simultaneously. Besides, the three functions can be intelligently coordinated to pursue mutual benefits,i.e., wireless sensing can be leveraged to enable light-training or even training-free WIPT by providing side-channel information, and the BS can utilize WPT to wirelessly charge low-power devices for ensuring sustainable ISAC. Furthermore, multiple multi-functional BSs can cooperate in both transmission and reception phases for efficient interference management, multi-static sensing, and distributed energy beamforming. For these operational modes, we discuss the technical challenges and potential solutions, particularly focusing on the fundamental performance tradeoff limits, transmission protocol design, as well as waveform and beamforming optimization. Finally, interesting research directions are identified.
MOC-RVQ: Multilevel Codebook-assisted Digital Generative Semantic Communication
Jan 02, 2024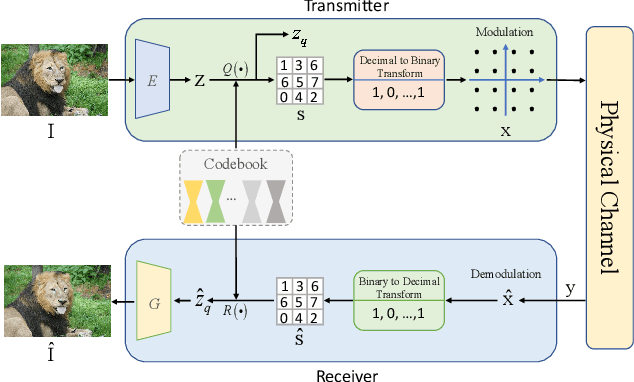
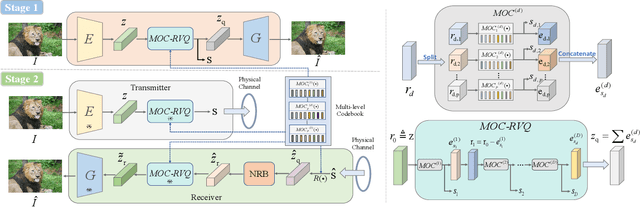
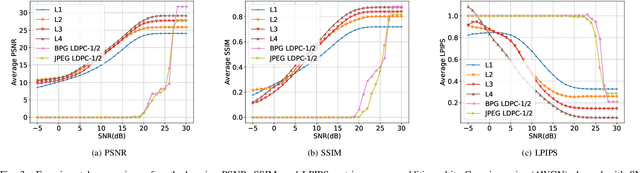
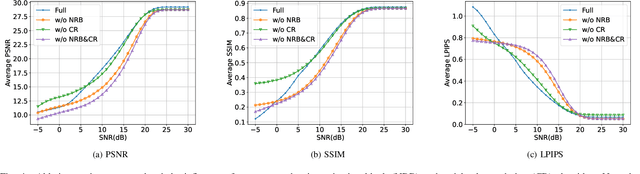
Vector quantization-based image semantic communication systems have successfully boosted transmission efficiency, but face a challenge with conflicting requirements between codebook design and digital constellation modulation. Traditional codebooks need a wide index range, while modulation favors few discrete states. To address this, we propose a multilevel generative semantic communication system with a two-stage training framework. In the first stage, we train a high-quality codebook, using a multi-head octonary codebook (MOC) to compress the index range. We also integrate a residual vector quantization (RVQ) mechanism for effective multilevel communication. In the second stage, a noise reduction block (NRB) based on Swin Transformer is introduced, coupled with the multilevel codebook from the first stage, serving as a high-quality semantic knowledge base (SKB) for generative feature restoration. Experimental results highlight MOC-RVQ's superior performance over methods like BPG or JPEG, even without channel error correction coding.
RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Dec 19, 2023



3D occupancy prediction is an emerging task that aims to estimate the occupancy states and semantics of 3D scenes using multi-view images. However, image-based scene perception encounters significant challenges in achieving accurate prediction due to the absence of geometric priors. In this paper, we address this issue by exploring cross-modal knowledge distillation in this task, i.e., we leverage a stronger multi-modal model to guide the visual model during training. In practice, we observe that directly applying features or logits alignment, proposed and widely used in bird's-eyeview (BEV) perception, does not yield satisfactory results. To overcome this problem, we introduce RadOcc, a Rendering assisted distillation paradigm for 3D Occupancy prediction. By employing differentiable volume rendering, we generate depth and semantic maps in perspective views and propose two novel consistency criteria between the rendered outputs of teacher and student models. Specifically, the depth consistency loss aligns the termination distributions of the rendered rays, while the semantic consistency loss mimics the intra-segment similarity guided by vision foundation models (VLMs). Experimental results on the nuScenes dataset demonstrate the effectiveness of our proposed method in improving various 3D occupancy prediction approaches, e.g., our proposed methodology enhances our baseline by 2.2% in the metric of mIoU and achieves 50% in Occ3D benchmark.