 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning
May 18, 2026Supervised open-loop training has been widely adopted for training traffic simulation models; however, it fails to capture the inherently dynamic, multi-agent interactions common in complex driving scenarios. We introduce RLFTSim, a reinforcement-learning-based fine-tuning framework that enhances scenario realism by aligning simulator rollouts with real-world data distributions and provides a method for distilling goal-conditioned controllability in scenario generation. We instantiate RLFTSim on top of a pre-trained simulation model, design a reward that balances fidelity and controllability, and perform comprehensive experiments on the Waymo Open Motion Dataset. Our results show improvements in realism, achieving state-of-the-art performance. Compared with other heuristic search-based fine-tuning methods, RLFTSim requires significantly fewer samples due to a proposed low-variance and dense reward signal, and it directly addresses the realism alignment issue by design. We also demonstrate the effectiveness of our approach for distilling traffic simulation controllability through goal conditioning. The project page is available at https://ehsan-ami.github.io/rlftsim.
TurboVGGT: Fast Visual Geometry Reconstruction with Adaptive Alternating Attention
May 14, 2026Recent feed-forward 3D reconstruction methods, such as visual geometry transformers, have substantially advanced the traditional per-scene optimization paradigm by enabling effective multi-view reconstruction in a single forward pass. However, most existing methods struggle to achieve a balance between reconstruction quality and computational efficiency, which limits their scalability and efficiency. Although some efficient visual geometry transformers have recently emerged, they typically use the same sparsity ratio across layers and frames and lack mechanisms to adaptively learn representative tokens to capture global relationships, leading to suboptimal performance. In this work, we propose TurboVGGT, a novel approach that employs an efficient visual geometry transformer with adaptive alternating attention for fast multi-view 3D reconstruction. Specifically, TurboVGGT employs an end-to-end trainable framework with adaptive sparse global attention guided by adaptive sparsity selection to capture global relationships across frames and frame attention to aggregate local details within each frame. In the adaptive sparse global attention, TurboVGGT adaptively learns representative tokens with varying sparsity levels for global geometry modeling, considering that token importance varies across frames, attention layers operate tokens at different levels of abstraction, and global dependencies rely on structurally informative regions. Extensive experiments on multiple 3D reconstruction benchmarks demonstrate that TurboVGGT achieves fast multi-view reconstruction while maintaining competitive reconstruction quality compared with state-of-the-art methods. Project page: https://turbovggt.github.io/.
Part-Level 3D Gaussian Vehicle Generation with Joint and Hinge Axis Estimation
Apr 06, 2026Simulation is essential for autonomous driving, yet current frameworks often model vehicles as rigid assets and fail to capture part-level articulation. With perception algorithms increasingly leveraging dynamics such as wheel steering or door opening, realistic simulation requires animatable vehicle representations. Existing CAD-based pipelines are limited by library coverage and fixed templates, preventing faithful reconstruction of in-the-wild instances. We propose a generative framework that, from a single image or sparse multi-view input, synthesizes an animatable 3D Gaussian vehicle. Our method addresses two challenges: (i) large 3D asset generators are optimized for static quality but not articulation, leading to distortions at part boundaries when animated; and (ii) segmentation alone cannot provide the kinematic parameters required for motion. To overcome this, we introduce a part-edge refinement module that enforces exclusive Gaussian ownership and a kinematic reasoning head that predicts joint positions and hinge axes of movable parts. Together, these components enable faithful part-aware simulation, bridging the gap between static generation and animatable vehicle models.
UniScale: Unified Scale-Aware 3D Reconstruction for Multi-View Understanding via Prior Injection for Robotic Perception
Feb 26, 2026We present UniScale, a unified, scale-aware multi-view 3D reconstruction framework for robotic applications that flexibly integrates geometric priors through a modular, semantically informed design. In vision-based robotic navigation, the accurate extraction of environmental structure from raw image sequences is critical for downstream tasks. UniScale addresses this challenge with a single feed-forward network that jointly estimates camera intrinsics and extrinsics, scale-invariant depth and point maps, and the metric scale of a scene from multi-view images, while optionally incorporating auxiliary geometric priors when available. By combining global contextual reasoning with camera-aware feature representations, UniScale is able to recover the metric-scale of the scene. In robotic settings where camera intrinsics are known, they can be easily incorporated to improve performance, with additional gains obtained when camera poses are also available. This co-design enables robust, metric-aware 3D reconstruction within a single unified model. Importantly, UniScale does not require training from scratch, and leverages world priors exhibited in pre-existing models without geometric encoding strategies, making it particularly suitable for resource-constrained robotic teams. We evaluate UniScale on multiple benchmarks, demonstrating strong generalization and consistent performance across diverse environments. We will release our implementation upon acceptance.
Language and Geometry Grounded Sparse Voxel Representations for Holistic Scene Understanding
Feb 17, 2026Existing 3D open-vocabulary scene understanding methods mostly emphasize distilling language features from 2D foundation models into 3D feature fields, but largely overlook the synergy among scene appearance, semantics, and geometry. As a result, scene understanding often deviates from the underlying geometric structure of scenes and becomes decoupled from the reconstruction process. In this work, we propose a novel approach that leverages language and geometry grounded sparse voxel representations to comprehensively model appearance, semantics, and geometry within a unified framework. Specifically, we use 3D sparse voxels as primitives and employ an appearance field, a density field, a feature field, and a confidence field to holistically represent a 3D scene. To promote synergy among the appearance, density, and feature fields, we construct a feature modulation module and distill language features from a 2D foundation model into our 3D scene model. In addition, we integrate geometric distillation into feature field distillation to transfer geometric knowledge from a geometry foundation model to our 3D scene representations via depth correlation regularization and pattern consistency regularization. These components work together to synergistically model the appearance, semantics, and geometry of the 3D scene within a unified framework. Extensive experiments demonstrate that our approach achieves superior overall performance compared with state-of-the-art methods in holistic scene understanding and reconstruction.
Nighttime Autonomous Driving Scene Reconstruction with Physically-Based Gaussian Splatting
Feb 14, 2026This paper focuses on scene reconstruction under nighttime conditions in autonomous driving simulation. Recent methods based on Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) have achieved photorealistic modeling in autonomous driving scene reconstruction, but they primarily focus on normal-light conditions. Low-light driving scenes are more challenging to model due to their complex lighting and appearance conditions, which often causes performance degradation of existing methods. To address this problem, this work presents a novel approach that integrates physically based rendering into 3DGS to enhance nighttime scene reconstruction for autonomous driving. Specifically, our approach integrates physically based rendering into composite scene Gaussian representations and jointly optimizes Bidirectional Reflectance Distribution Function (BRDF) based material properties. We explicitly model diffuse components through a global illumination module and specular components by anisotropic spherical Gaussians. As a result, our approach improves reconstruction quality for outdoor nighttime driving scenes, while maintaining real-time rendering. Extensive experiments across diverse nighttime scenarios on two real-world autonomous driving datasets, including nuScenes and Waymo, demonstrate that our approach outperforms the state-of-the-art methods both quantitatively and qualitatively.
FreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
Jan 28, 2026Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
MoVieDrive: Multi-Modal Multi-View Urban Scene Video Generation
Aug 20, 2025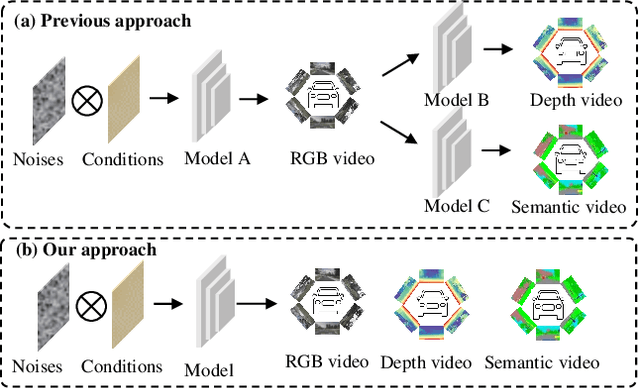
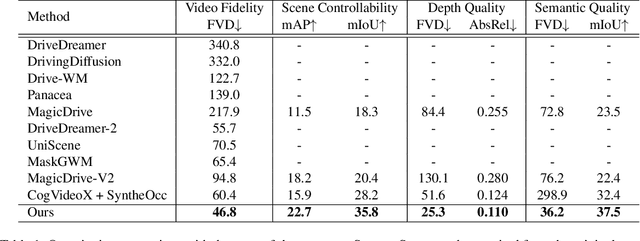
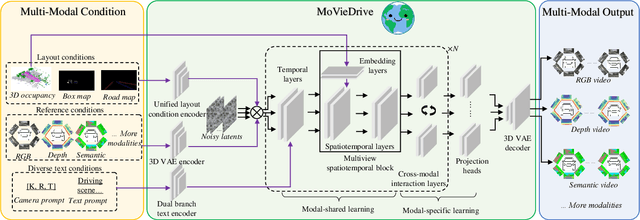
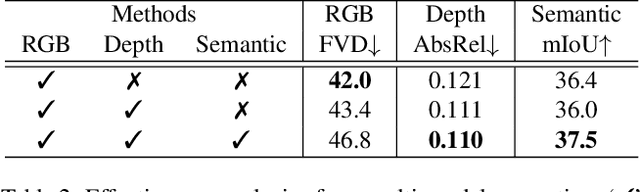
Video generation has recently shown superiority in urban scene synthesis for autonomous driving. Existing video generation approaches to autonomous driving primarily focus on RGB video generation and lack the ability to support multi-modal video generation. However, multi-modal data, such as depth maps and semantic maps, are crucial for holistic urban scene understanding in autonomous driving. Although it is feasible to use multiple models to generate different modalities, this increases the difficulty of model deployment and does not leverage complementary cues for multi-modal data generation. To address this problem, in this work, we propose a novel multi-modal multi-view video generation approach to autonomous driving. Specifically, we construct a unified diffusion transformer model composed of modal-shared components and modal-specific components. Then, we leverage diverse conditioning inputs to encode controllable scene structure and content cues into the unified diffusion model for multi-modal multi-view video generation. In this way, our approach is capable of generating multi-modal multi-view driving scene videos in a unified framework. Our experiments on the challenging real-world autonomous driving dataset, nuScenes, show that our approach can generate multi-modal multi-view urban scene videos with high fidelity and controllability, surpassing the state-of-the-art methods.