 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
DiffuGR: Generative Document Retrieval with Diffusion Language Models
Nov 19, 2025Generative retrieval (GR) re-frames document retrieval as a sequence-based document identifier (DocID) generation task, memorizing documents with model parameters and enabling end-to-end retrieval without explicit indexing. Existing GR methods are based on auto-regressive generative models, i.e., the token generation is performed from left to right. However, such auto-regressive methods suffer from: (1) mismatch between DocID generation and natural language generation, e.g., an incorrect DocID token generated in early left steps would lead to totally erroneous retrieval; and (2) failure to balance the trade-off between retrieval efficiency and accuracy dynamically, which is crucial for practical applications. To address these limitations, we propose generative document retrieval with diffusion language models, dubbed DiffuGR. It models DocID generation as a discrete diffusion process: during training, DocIDs are corrupted through a stochastic masking process, and a diffusion language model is learned to recover them under a retrieval-aware objective. For inference, DiffuGR attempts to generate DocID tokens in parallel and refines them through a controllable number of denoising steps. In contrast to conventional left-to-right auto-regressive decoding, DiffuGR provides a novel mechanism to first generate more confident DocID tokens and refine the generation through diffusion-based denoising. Moreover, DiffuGR also offers explicit runtime control over the qualitylatency tradeoff. Extensive experiments on benchmark retrieval datasets show that DiffuGR is competitive with strong auto-regressive generative retrievers, while offering flexible speed and accuracy tradeoffs through variable denoising budgets. Overall, our results indicate that non-autoregressive diffusion models are a practical and effective alternative for generative document retrieval.
Efficient Thought Space Exploration through Strategic Intervention
Nov 13, 2025While large language models (LLMs) demonstrate emerging reasoning capabilities, current inference-time expansion methods incur prohibitive computational costs by exhaustive sampling. Through analyzing decoding trajectories, we observe that most next-token predictions align well with the golden output, except for a few critical tokens that lead to deviations. Inspired by this phenomenon, we propose a novel Hint-Practice Reasoning (HPR) framework that operationalizes this insight through two synergistic components: 1) a hinter (powerful LLM) that provides probabilistic guidance at critical decision points, and 2) a practitioner (efficient smaller model) that executes major reasoning steps. The framework's core innovation lies in Distributional Inconsistency Reduction (DIR), a theoretically-grounded metric that dynamically identifies intervention points by quantifying the divergence between practitioner's reasoning trajectory and hinter's expected distribution in a tree-structured probabilistic space. Through iterative tree updates guided by DIR, HPR reweights promising reasoning paths while deprioritizing low-probability branches. Experiments across arithmetic and commonsense reasoning benchmarks demonstrate HPR's state-of-the-art efficiency-accuracy tradeoffs: it achieves comparable performance to self-consistency and MCTS baselines while decoding only 1/5 tokens, and outperforms existing methods by at most 5.1% absolute accuracy while maintaining similar or lower FLOPs.
Thinking Forward and Backward: Multi-Objective Reinforcement Learning for Retrieval-Augmented Reasoning
Nov 13, 2025Retrieval-augmented generation (RAG) has proven to be effective in mitigating hallucinations in large language models, yet its effectiveness remains limited in complex, multi-step reasoning scenarios. Recent efforts have incorporated search-based interactions into RAG, enabling iterative reasoning with real-time retrieval. Most approaches rely on outcome-based supervision, offering no explicit guidance for intermediate steps. This often leads to reward hacking and degraded response quality. We propose Bi-RAR, a novel retrieval-augmented reasoning framework that evaluates each intermediate step jointly in both forward and backward directions. To assess the information completeness of each step, we introduce a bidirectional information distance grounded in Kolmogorov complexity, approximated via language model generation probabilities. This quantification measures both how far the current reasoning is from the answer and how well it addresses the question. To optimize reasoning under these bidirectional signals, we adopt a multi-objective reinforcement learning framework with a cascading reward structure that emphasizes early trajectory alignment. Empirical results on seven question answering benchmarks demonstrate that Bi-RAR surpasses previous methods and enables efficient interaction and reasoning with the search engine during training and inference.
Can LLM Annotations Replace User Clicks for Learning to Rank?
Nov 10, 2025Large-scale supervised data is essential for training modern ranking models, but obtaining high-quality human annotations is costly. Click data has been widely used as a low-cost alternative, and with recent advances in large language models (LLMs), LLM-based relevance annotation has emerged as another promising annotation. This paper investigates whether LLM annotations can replace click data for learning to rank (LTR) by conducting a comprehensive comparison across multiple dimensions. Experiments on both a public dataset, TianGong-ST, and an industrial dataset, Baidu-Click, show that click-supervised models perform better on high-frequency queries, while LLM annotation-supervised models are more effective on medium- and low-frequency queries. Further analysis shows that click-supervised models are better at capturing document-level signals such as authority or quality, while LLM annotation-supervised models are more effective at modeling semantic matching between queries and documents and at distinguishing relevant from non-relevant documents. Motivated by these observations, we explore two training strategies -- data scheduling and frequency-aware multi-objective learning -- that integrate both supervision signals. Both approaches enhance ranking performance across queries at all frequency levels, with the latter being more effective. Our code is available at https://github.com/Trustworthy-Information-Access/LLMAnn_Click.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025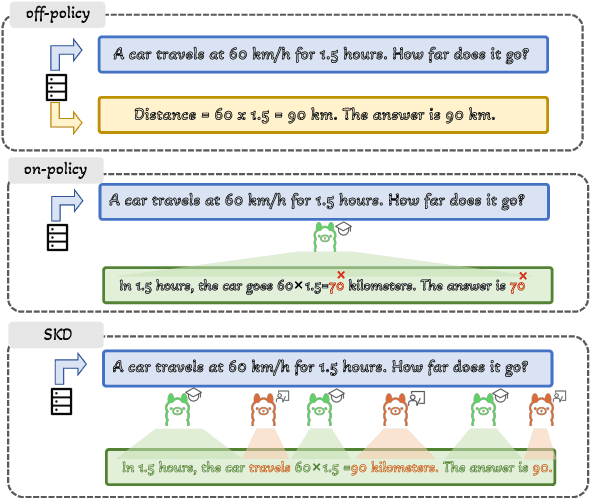
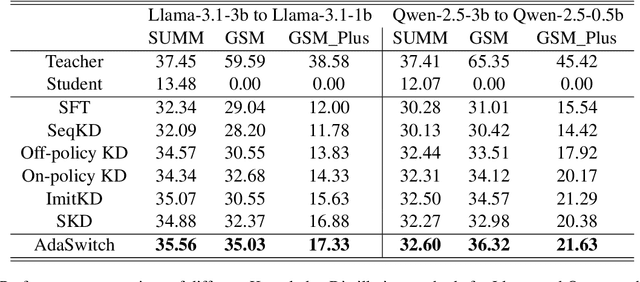
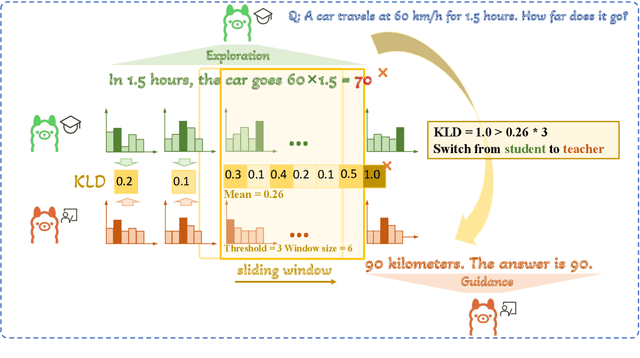
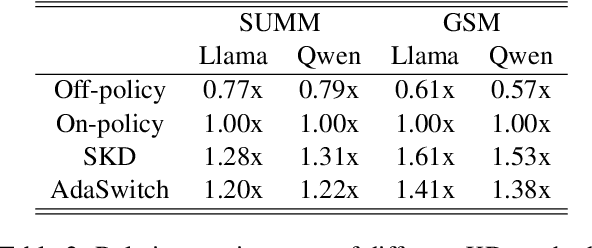
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
A Question Answering Dataset for Temporal-Sensitive Retrieval-Augmented Generation
Aug 17, 2025We introduce ChronoQA, a large-scale benchmark dataset for Chinese question answering, specifically designed to evaluate temporal reasoning in Retrieval-Augmented Generation (RAG) systems. ChronoQA is constructed from over 300,000 news articles published between 2019 and 2024, and contains 5,176 high-quality questions covering absolute, aggregate, and relative temporal types with both explicit and implicit time expressions. The dataset supports both single- and multi-document scenarios, reflecting the real-world requirements for temporal alignment and logical consistency. ChronoQA features comprehensive structural annotations and has undergone multi-stage validation, including rule-based, LLM-based, and human evaluation, to ensure data quality. By providing a dynamic, reliable, and scalable resource, ChronoQA enables structured evaluation across a wide range of temporal tasks, and serves as a robust benchmark for advancing time-sensitive retrieval-augmented question answering systems.
Leveraging LLMs to Evaluate Usefulness of Document
Jun 11, 2025The conventional Cranfield paradigm struggles to effectively capture user satisfaction due to its weak correlation between relevance and satisfaction, alongside the high costs of relevance annotation in building test collections. To tackle these issues, our research explores the potential of leveraging large language models (LLMs) to generate multilevel usefulness labels for evaluation. We introduce a new user-centric evaluation framework that integrates users' search context and behavioral data into LLMs. This framework uses a cascading judgment structure designed for multilevel usefulness assessments, drawing inspiration from ordinal regression techniques. Our study demonstrates that when well-guided with context and behavioral information, LLMs can accurately evaluate usefulness, allowing our approach to surpass third-party labeling methods. Furthermore, we conduct ablation studies to investigate the influence of key components within the framework. We also apply the labels produced by our method to predict user satisfaction, with real-world experiments indicating that these labels substantially improve the performance of satisfaction prediction models.
Proactive Guidance of Multi-Turn Conversation in Industrial Search
May 30, 2025



The evolution of Large Language Models (LLMs) has significantly advanced multi-turn conversation systems, emphasizing the need for proactive guidance to enhance users' interactions. However, these systems face challenges in dynamically adapting to shifts in users' goals and maintaining low latency for real-time interactions. In the Baidu Search AI assistant, an industrial-scale multi-turn search system, we propose a novel two-phase framework to provide proactive guidance. The first phase, Goal-adaptive Supervised Fine-Tuning (G-SFT), employs a goal adaptation agent that dynamically adapts to user goal shifts and provides goal-relevant contextual information. G-SFT also incorporates scalable knowledge transfer to distill insights from LLMs into a lightweight model for real-time interaction. The second phase, Click-oriented Reinforcement Learning (C-RL), adopts a generate-rank paradigm, systematically constructs preference pairs from user click signals, and proactively improves click-through rates through more engaging guidance. This dual-phase architecture achieves complementary objectives: G-SFT ensures accurate goal tracking, while C-RL optimizes interaction quality through click signal-driven reinforcement learning. Extensive experiments demonstrate that our framework achieves 86.10% accuracy in offline evaluation (+23.95% over baseline) and 25.28% CTR in online deployment (149.06% relative improvement), while reducing inference latency by 69.55% through scalable knowledge distillation.