 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Action Priors for Cross-embodiment Robot Manipulation
Jun 24, 2026Most Vision-Language-Action (VLA) models build on a Vision-Language Model (VLM) backbone by attaching an action module and optimizing the full policy jointly. This design inherits strong visual and linguistic priors from the VLM, but leaves the action module to learn physical motion almost from scratch. As a result, the policy lacks an explicit motion prior, forcing early optimization to simultaneously discover temporal action dynamics and cross-modal alignment, a challenge further amplified in cross-embodiment settings. In this work, we propose to pretrain the action module with motion priors before cross-modal VLA alignment. Specifically, we introduce a two-stage training framework that equips the action module with cross-embodiment temporal motion structure before VLA training begins. In Stage~1, a lightweight flow-matching-based encoder-decoder action module efficiently learns temporal motion structure solely from unconditioned action trajectories, without processing visual or language tokens. In Stage~2, this learned prior is transferred to VLA training through decoder reuse and early-stage latent distillation, aligning visual-language features with the action embedding space while still allowing end-to-end policy refinement. In addition, the trained encoder serves as a compact history compressor, summarizing state-action histories into a single temporal context token for history-aware modeling at negligible cost. Extensive experiments across 13 diverse cross-embodiment tasks on both simulated and real-world platforms validate the effectiveness of our approach. Compared with VLA training without action priors, our model achieves faster convergence, higher success rates, and substantially stronger performance on data-scarce real-world tasks. Moreover, scaling up the action data in Stage~1 yields a more generalizable action prior that directly improves downstream VLA performance.
Efficient and Trainable Language Model Test-Time Scaling via Local Branch Routing
Jun 24, 2026Test-time scaling improves language-model reasoning, but existing approaches often face a difficult trade-off: long chain-of-thought sampling remains single-threaded, while sentence- or solution-level search can be computationally expensive and hard to train end-to-end. We introduce Local Branch Routing (LBR), a token-level test-time scaling framework that expands a small local lookahead tree, forwards all sampled branches through the language model, and uses a lightweight router to select the depth-1 subtree to commit. By routing over the hidden states of candidate local futures, LBR allows each token decision to use evidence beyond the root next-token distribution while avoiding full solution-level search. The resulting prune-shift-grow decoding process preserves discrete branch identities and defines a tractable tree-trajectory likelihood: newly grown nodes are counted when first sampled, and router decisions are assigned explicit probabilities. This enables end-to-end reinforcement learning with verifiable rewards, jointly optimizing the base model and router under the same likelihood-ratio principle as discrete-token RLVR. On synthetic hierarchical-planning tasks, LBR shows that post-candidate hidden states provide useful routing evidence. On mathematical reasoning benchmarks, LBR improves both Pass@1 and Pass@32 over discrete chain-of-thought, vanilla discrete-token RLVR, and RL-compatible soft-token branching baselines. These results suggest that lightweight local branching offers an efficient, trainable, and discrete form of language-model test-time scaling.
EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
May 14, 2026Extending the context window of large language models typically requires training on sequences at the target length, incurring quadratic memory and computational costs that make long-context adaptation expensive and difficult to reproduce. We propose EndPrompt, a method that achieves effective context extension using only short training sequences. The core insight is that exposing a model to long-range relative positional distances does not require constructing full-length inputs: we preserve the original short context as an intact first segment and append a brief terminal prompt as a second segment, assigning it positional indices near the target context length. This two-segment construction introduces both local and long-range relative distances within a short physical sequence while maintaining the semantic continuity of the training text--a property absent in chunk-based simulation approaches that split contiguous context. We provide a theoretical analysis grounded in Rotary Position Embedding and the Bernstein inequality, showing that position interpolation induces a rigorous smoothness constraint over the attention function, with shared Transformer parameters further suppressing unstable extrapolation to unobserved intermediate distances. Applied to LLaMA-family models extending the context window from 8K to 64K, EndPrompt achieves an average RULER score of 76.03 and the highest average on LongBench, surpassing LCEG (72.24), LongLoRA (72.95), and full-length fine-tuning (69.23) while requiring substantially less computation. These results demonstrate that long-context generalization can be induced from sparse positional supervision, challenging the prevailing assumption that dense long-sequence training is necessary for reliable context-window extension. The code is available at https://github.com/clx1415926/EndPrompt.
All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs
May 12, 2026In this paper, we present empirical and theoretical evidence against a central but largely implicit assumption in circuit and sheaf discovery (CSD), which we term the Functional Anisotropy Hypothesis: the idea that functions in large language models (LLMs) are localised to a unique or near-unique internal mechanism. We show that a single LLM task can instead be supported by multiple, structurally distinct circuits or sheaves that are simultaneously faithful, sparse, and complete. To systematically uncover such competing mechanisms, we introduce Overlap-Aware Sheaf Repulsion, a method that augments the CSD objective with an explicit penalty on structural overlap across multiple discovery runs, enabling the discovery of circuits or sheaves with strong task performance but minimal shared structure across a plethora of common CSD benchmarks. We find that this phenomenon becomes increasingly pronounced as the number of discovered sheaves grows and persists robustly across major CSD methods. We further identify an ultra-sparse three-edge sheaf and show that none of its edges is individually indispensable, undermining even weakened notions of canonical or essential components. To explain these findings, we propose a Distributive Dense Circuit Hypothesis and provide a theoretical analysis demonstrating that non-unique, low-overlap circuit explanations arise naturally from high-dimensional superposition under mild assumptions. Together, our results suggest that mechanistic explanations in LLMs are inherently non-canonical and call for a rethinking of how CSD results should be interpreted and evaluated.
What Happens Inside Agent Memory? Circuit Analysis from Emergence to Diagnosis
May 05, 2026Agent memory failures are silent: an LLM-based agent can produce a fluent response even when it fails to extract, retain, or retrieve the information needed across sessions. The write-manage-read loop describes the external pipeline of these systems but leaves open which internal computations implement each stage. Tracing internal feature circuits across the Qwen-3 family (0.6B--14B) and two memory frameworks (mem0 and A-MEM), we report three findings. First, control is detectable before content: routing circuitry is causally active at 0.6B, while content circuitry produces no detectable signal until 4B under our tracing setup, creating a deployment regime where small models route with apparent competence but silently fail at extraction and grounding. Second, within the content group, Write and Read share a late-layer hub that operates as a context-grounding substrate already present in the base model; only memory framing recruits a functional grounding direction on this substrate, and the hub transfers across both frameworks. Third, emergence does not imply steerability: although the content circuit becomes detectable at 4B, it becomes reliably steerable only at 8B, indicating that detection and intervention have distinct scale thresholds. As a practical implication, the feature-space separation between the two circuit groups enables per-operation failure localization at 76.2% accuracy without supervision, providing a stage-level diagnostic for otherwise silent agent-memory failures.
Reinforcing Consistency in Video MLLMs with Structured Rewards
Apr 01, 2026Multimodal large language models (MLLMs) have achieved remarkable progress in video understanding. However, seemingly plausible outputs often suffer from poor visual and temporal grounding: a model may fabricate object existence, assign incorrect attributes, or collapse repeated events while still producing a globally reasonable caption or answer. We study this failure mode through a compositional consistency audit that decomposes a caption into supporting factual and temporal claims, investigating whether a correct high-level prediction is actually backed by valid lower-level evidence. Our top-down audit reveals that even correct root relational claims often lack reliable attribute and existence support. This indicates that standard sentence-level supervision is a weak proxy for faithful video understanding. Furthermore, when turning to reinforcement learning (RL) for better alignment, standard sentence-level rewards often prove too coarse to accurately localize specific grounding failures. To address this, we replace generic sentence-level rewards with a structured reward built from factual and temporal units. Our training objective integrates three complementary components: (1) an instance-aware scene-graph reward for factual objects, attributes, and relations; (2) a temporal reward for event ordering and repetition; and (3) a video-grounded VQA reward for hierarchical self-verification. Across temporal, general video understanding, and hallucination-oriented benchmarks, this objective yields consistent gains on open-source backbones. These results suggest that structured reward shaping is a practical route to more faithful video understanding.
CodeHacker: Automated Test Case Generation for Detecting Vulnerabilities in Competitive Programming Solutions
Feb 23, 2026The evaluation of Large Language Models (LLMs) for code generation relies heavily on the quality and robustness of test cases. However, existing benchmarks often lack coverage for subtle corner cases, allowing incorrect solutions to pass. To bridge this gap, we propose CodeHacker, an automated agent framework dedicated to generating targeted adversarial test cases that expose latent vulnerabilities in program submissions. Mimicking the hack mechanism in competitive programming, CodeHacker employs a multi-strategy approach, including stress testing, anti-hash attacks, and logic-specific targeting to break specific code submissions. To ensure the validity and reliability of these attacks, we introduce a Calibration Phase, where the agent iteratively refines its own Validator and Checker via self-generated adversarial probes before evaluating contestant code.Experiments demonstrate that CodeHacker significantly improves the True Negative Rate (TNR) of existing datasets, effectively filtering out incorrect solutions that were previously accepted. Furthermore, generated adversarial cases prove to be superior training data, boosting the performance of RL-trained models on benchmarks like LiveCodeBench.
Not All Preferences Are Created Equal: Stability-Aware and Gradient-Efficient Alignment for Reasoning Models
Feb 01, 2026Preference-based alignment is pivotal for training large reasoning models; however, standard methods like Direct Preference Optimization (DPO) typically treat all preference pairs uniformly, overlooking the evolving utility of training instances. This static approach often leads to inefficient or unstable optimization, as it wastes computation on trivial pairs with negligible gradients and suffers from noise induced by samples near uncertain decision boundaries. Facing these challenges, we propose SAGE (Stability-Aware Gradient Efficiency), a dynamic framework designed to enhance alignment reliability by maximizing the Signal-to-Noise Ratio of policy updates. Concretely, SAGE integrates a coarse-grained curriculum mechanism that refreshes candidate pools based on model competence with a fine-grained, stability-aware scoring function that prioritizes informative, confident errors while filtering out unstable samples. Experiments on multiple mathematical reasoning benchmarks demonstrate that SAGE significantly accelerates convergence and outperforms static baselines, highlighting the critical role of policy-aware, stability-conscious data selection in reasoning alignment.
Mitigating Hallucinations in Video Large Language Models via Spatiotemporal-Semantic Contrastive Decoding
Jan 30, 2026Although Video Large Language Models perform remarkably well across tasks such as video understanding, question answering, and reasoning, they still suffer from the problem of hallucination, which refers to generating outputs that are inconsistent with explicit video content or factual evidence. However, existing decoding methods for mitigating video hallucinations, while considering the spatiotemporal characteristics of videos, mostly rely on heuristic designs. As a result, they fail to precisely capture the root causes of hallucinations and their fine-grained temporal and semantic correlations, leading to limited robustness and generalization in complex scenarios. To more effectively mitigate video hallucinations, we propose a novel decoding strategy termed Spatiotemporal-Semantic Contrastive Decoding. This strategy constructs negative features by deliberately disrupting the spatiotemporal consistency and semantic associations of video features, and suppresses video hallucinations through contrastive decoding against the original video features during inference. Extensive experiments demonstrate that our method not only effectively mitigates the occurrence of hallucinations, but also preserves the general video understanding and reasoning capabilities of the model.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025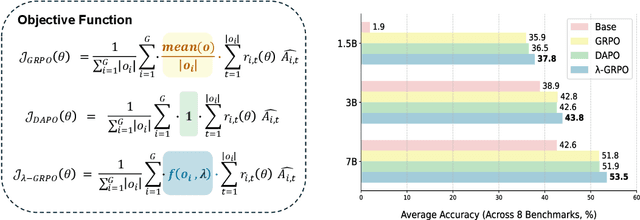
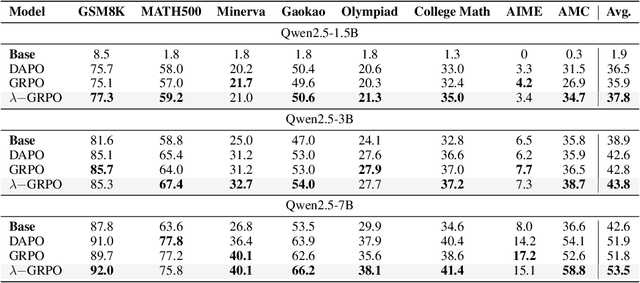
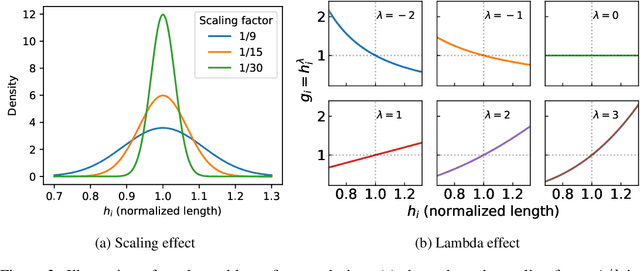

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.