 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPNet: Dynamic Pooling Network for Tiny Object Detection
May 05, 2025



In unmanned aerial systems, especially in complex environments, accurately detecting tiny objects is crucial. Resizing images is a common strategy to improve detection accuracy, particularly for small objects. However, simply enlarging images significantly increases computational costs and the number of negative samples, severely degrading detection performance and limiting its applicability. This paper proposes a Dynamic Pooling Network (DPNet) for tiny object detection to mitigate these issues. DPNet employs a flexible down-sampling strategy by introducing a factor (df) to relax the fixed downsampling process of the feature map to an adjustable one. Furthermore, we design a lightweight predictor to predict df for each input image, which is used to decrease the resolution of feature maps in the backbone. Thus, we achieve input-aware downsampling. We also design an Adaptive Normalization Module (ANM) to make a unified detector compatible with different dfs. A guidance loss supervises the predictor's training. DPNet dynamically allocates computing resources to trade off between detection accuracy and efficiency. Experiments on the TinyCOCO and TinyPerson datasets show that DPNet can save over 35% and 25% GFLOPs, respectively, while maintaining comparable detection performance. The code will be made publicly available.
Exploring Cognitive and Aesthetic Causality for Multimodal Aspect-Based Sentiment Analysis
Apr 22, 2025



Multimodal aspect-based sentiment classification (MASC) is an emerging task due to an increase in user-generated multimodal content on social platforms, aimed at predicting sentiment polarity toward specific aspect targets (i.e., entities or attributes explicitly mentioned in text-image pairs). Despite extensive efforts and significant achievements in existing MASC, substantial gaps remain in understanding fine-grained visual content and the cognitive rationales derived from semantic content and impressions (cognitive interpretations of emotions evoked by image content). In this study, we present Chimera: a cognitive and aesthetic sentiment causality understanding framework to derive fine-grained holistic features of aspects and infer the fundamental drivers of sentiment expression from both semantic perspectives and affective-cognitive resonance (the synergistic effect between emotional responses and cognitive interpretations). Specifically, this framework first incorporates visual patch features for patch-word alignment. Meanwhile, it extracts coarse-grained visual features (e.g., overall image representation) and fine-grained visual regions (e.g., aspect-related regions) and translates them into corresponding textual descriptions (e.g., facial, aesthetic). Finally, we leverage the sentimental causes and impressions generated by a large language model (LLM) to enhance the model's awareness of sentimental cues evoked by semantic content and affective-cognitive resonance. Experimental results on standard MASC datasets demonstrate the effectiveness of the proposed model, which also exhibits greater flexibility to MASC compared to LLMs such as GPT-4o. We have publicly released the complete implementation and dataset at https://github.com/Xillv/Chimera
Aspect-Based Summarization with Self-Aspect Retrieval Enhanced Generation
Apr 17, 2025Aspect-based summarization aims to generate summaries tailored to specific aspects, addressing the resource constraints and limited generalizability of traditional summarization approaches. Recently, large language models have shown promise in this task without the need for training. However, they rely excessively on prompt engineering and face token limits and hallucination challenges, especially with in-context learning. To address these challenges, in this paper, we propose a novel framework for aspect-based summarization: Self-Aspect Retrieval Enhanced Summary Generation. Rather than relying solely on in-context learning, given an aspect, we employ an embedding-driven retrieval mechanism to identify its relevant text segments. This approach extracts the pertinent content while avoiding unnecessary details, thereby mitigating the challenge of token limits. Moreover, our framework optimizes token usage by deleting unrelated parts of the text and ensuring that the model generates output strictly based on the given aspect. With extensive experiments on benchmark datasets, we demonstrate that our framework not only achieves superior performance but also effectively mitigates the token limitation problem.
Learning from Reference Answers: Versatile Language Model Alignment without Binary Human Preference Data
Apr 14, 2025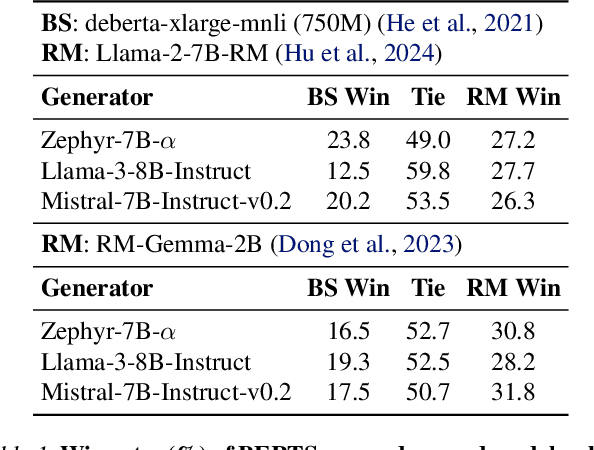

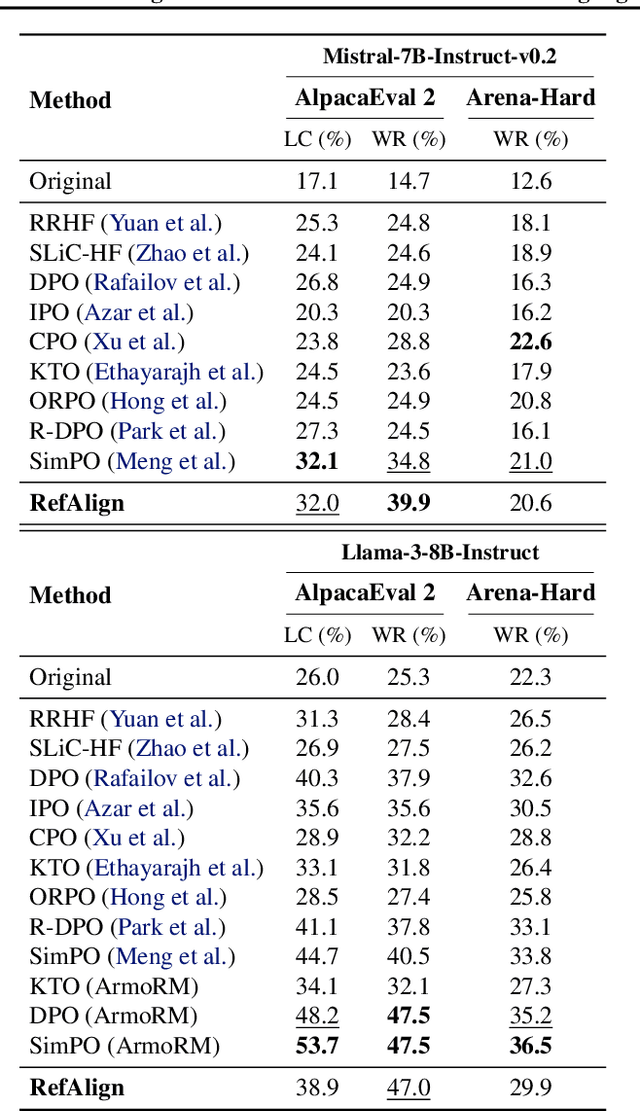
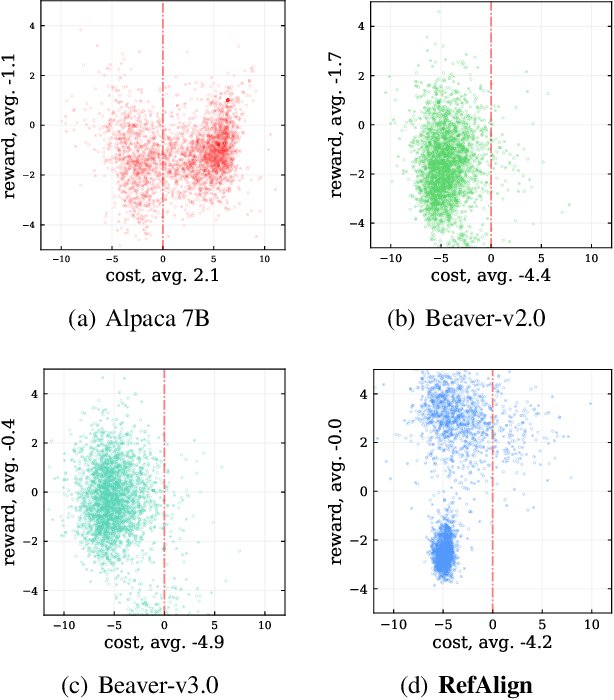
Large language models~(LLMs) are expected to be helpful, harmless, and honest. In various alignment scenarios, such as general human preference, safety, and confidence alignment, binary preference data collection and reward modeling are resource-intensive but necessary for human preference transferring. In this work, we explore using the similarity between sampled generations and high-quality reference answers as an alternative reward function for LLM alignment. Using similarity as a reward circumvents training reward models, and collecting a single reference answer potentially costs less time than constructing binary preference pairs when multiple candidates are available. Specifically, we develop \textit{RefAlign}, a versatile REINFORCE-style alignment algorithm, which is free of reference and reward models. Instead, RefAlign utilizes BERTScore between sampled generations and high-quality reference answers as the surrogate reward. Beyond general human preference optimization, RefAlign can be readily extended to diverse scenarios, such as safety and confidence alignment, by incorporating the similarity reward with task-related objectives. In various scenarios, {RefAlign} demonstrates comparable performance to previous alignment methods while offering high efficiency.
Unlocking a New Rust Programming Experience: Fast and Slow Thinking with LLMs to Conquer Undefined Behaviors
Mar 04, 2025



To provide flexibility and low-level interaction capabilities, the unsafe tag in Rust is essential in many projects, but undermines memory safety and introduces Undefined Behaviors (UBs) that reduce safety. Eliminating these UBs requires a deep understanding of Rust's safety rules and strong typing. Traditional methods require depth analysis of code, which is laborious and depends on knowledge design. The powerful semantic understanding capabilities of LLM offer new opportunities to solve this problem. Although existing large model debugging frameworks excel in semantic tasks, limited by fixed processes and lack adaptive and dynamic adjustment capabilities. Inspired by the dual process theory of decision-making (Fast and Slow Thinking), we present a LLM-based framework called RustBrain that automatically and flexibly minimizes UBs in Rust projects. Fast thinking extracts features to generate solutions, while slow thinking decomposes, verifies, and generalizes them abstractly. To apply verification and generalization results to solution generation, enabling dynamic adjustments and precise outputs, RustBrain integrates two thinking through a feedback mechanism. Experimental results on Miri dataset show a 94.3% pass rate and 80.4% execution rate, improving flexibility and Rust projects safety.
T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting
Feb 28, 2025



Zero-shot object counting aims to count instances of arbitrary object categories specified by text descriptions. Existing methods typically rely on vision-language models like CLIP, but often exhibit limited sensitivity to text prompts. We present T2ICount, a diffusion-based framework that leverages rich prior knowledge and fine-grained visual understanding from pretrained diffusion models. While one-step denoising ensures efficiency, it leads to weakened text sensitivity. To address this challenge, we propose a Hierarchical Semantic Correction Module that progressively refines text-image feature alignment, and a Representational Regional Coherence Loss that provides reliable supervision signals by leveraging the cross-attention maps extracted from the denosing U-Net. Furthermore, we observe that current benchmarks mainly focus on majority objects in images, potentially masking models' text sensitivity. To address this, we contribute a challenging re-annotated subset of FSC147 for better evaluation of text-guided counting ability. Extensive experiments demonstrate that our method achieves superior performance across different benchmarks. Code is available at https://github.com/cha15yq/T2ICount.
CutPaste&Find: Efficient Multimodal Hallucination Detector with Visual-aid Knowledge Base
Feb 18, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive multimodal reasoning capabilities, but they remain susceptible to hallucination, particularly object hallucination where non-existent objects or incorrect attributes are fabricated in generated descriptions. Existing detection methods achieve strong performance but rely heavily on expensive API calls and iterative LVLM-based validation, making them impractical for large-scale or offline use. To address these limitations, we propose CutPaste\&Find, a lightweight and training-free framework for detecting hallucinations in LVLM-generated outputs. Our approach leverages off-the-shelf visual and linguistic modules to perform multi-step verification efficiently without requiring LVLM inference. At the core of our framework is a Visual-aid Knowledge Base that encodes rich entity-attribute relationships and associated image representations. We introduce a scaling factor to refine similarity scores, mitigating the issue of suboptimal alignment values even for ground-truth image-text pairs. Comprehensive evaluations on benchmark datasets, including POPE and R-Bench, demonstrate that CutPaste\&Find achieves competitive hallucination detection performance while being significantly more efficient and cost-effective than previous methods.
Uni-Retrieval: A Multi-Style Retrieval Framework for STEM's Education
Feb 09, 2025In AI-facilitated teaching, leveraging various query styles to interpret abstract text descriptions is crucial for ensuring high-quality teaching. However, current retrieval models primarily focus on natural text-image retrieval, making them insufficiently tailored to educational scenarios due to the ambiguities in the retrieval process. In this paper, we propose a diverse expression retrieval task tailored to educational scenarios, supporting retrieval based on multiple query styles and expressions. We introduce the STEM Education Retrieval Dataset (SER), which contains over 24,000 query pairs of different styles, and the Uni-Retrieval, an efficient and style-diversified retrieval vision-language model based on prompt tuning. Uni-Retrieval extracts query style features as prototypes and builds a continuously updated Prompt Bank containing prompt tokens for diverse queries. This bank can updated during test time to represent domain-specific knowledge for different subject retrieval scenarios. Our framework demonstrates scalability and robustness by dynamically retrieving prompt tokens based on prototype similarity, effectively facilitating learning for unknown queries. Experimental results indicate that Uni-Retrieval outperforms existing retrieval models in most retrieval tasks. This advancement provides a scalable and precise solution for diverse educational needs.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Enhancing Multimodal Entity Linking with Jaccard Distance-based Conditional Contrastive Learning and Contextual Visual Augmentation
Jan 24, 2025Previous research on multimodal entity linking (MEL) has primarily employed contrastive learning as the primary objective. However, using the rest of the batch as negative samples without careful consideration, these studies risk leveraging easy features and potentially overlook essential details that make entities unique. In this work, we propose JD-CCL (Jaccard Distance-based Conditional Contrastive Learning), a novel approach designed to enhance the ability to match multimodal entity linking models. JD-CCL leverages meta-information to select negative samples with similar attributes, making the linking task more challenging and robust. Additionally, to address the limitations caused by the variations within the visual modality among mentions and entities, we introduce a novel method, CVaCPT (Contextual Visual-aid Controllable Patch Transform). It enhances visual representations by incorporating multi-view synthetic images and contextual textual representations to scale and shift patch representations. Experimental results on benchmark MEL datasets demonstrate the strong effectiveness of our approach.