 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Signals to Transfer: A Factorised Study of Probe-Based Uncertainty Estimation in Large Language Models
Jun 26, 2026Probe-based uncertainty estimation (UE) has emerged as a prominent approach to detect hallucinations in Large Language Models (LLMs) by learning uncertainty from internal model signals. Yet, recent methods vary simultaneously across feature design, training data construction, and evaluation setting, obscuring what actually drives performance. To address this issue, we propose a factorised study of probe-based UE under matched conditions. Our results show that raw hidden states and attention features are difficult to outperform in-domain. However, under distribution shift, structured and compressed features are more robust, suggesting that in-domain performance alone is insufficient to measure progress. Furthermore, prompting and label construction significantly affect probe behaviour. Building on these best-practice findings, we train benchmark-based pretrained probes that transfer reasonably well to open-ended factual generation, providing a stable off-the-shelf baseline. Our work encourages more deployment-oriented evaluation of probe-based uncertainty estimators. The code repository is available at https://github.com/ponhvoan/ProbeUE.
DeepSurvey: Enhancing Analytical Depth and Citation Reliability in Automated Survey Generation
May 28, 2026As scientific literature grows rapidly, automated survey generation has become a key capability for AI scientists and human researchers. However, existing systems suffer from limited analytical depth due to reliance on abstracts and isolated paper processing, and unreliable citations from imprecise retrieval and post-hoc grounding, producing superficial surveys and may mislead researchers. We present DeepSurvey, an agentic system that addresses both. To enhance depth, DeepSurvey extracts structured keynotes from full-text papers, models cross-paper relationships through clustering and comparative analysis, and integrates code-repository analysis to recover implementation-level details. To fortify reliability, it combines citation-graph expansion with hybrid filtering for topic-focussed retrieval, enforces evidence-constrained citation assignment, and deploys multi-granularity agentic refinement to validate citation-claim alignment. Experiments show that DeepSurvey achieves the highest content score (8.644/10) and citation quality (12.3% and 9.3% recall and precision gains over the strongest baseline), generalizes more robustly across domains (0.14 vs 0.22 to 0.69 CS-to-non-CS drop), and is preferred over human-written surveys by domain experts (83.3% overall quality, 100% content depth).
Understanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
May 12, 2026Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving the reasoning ability of large language models. However, widely used RLVR algorithms, such as GRPO, often suffer from entropy collapse, leading to premature determinism and unstable optimization. Existing remedies, including entropy regularization and ratio-based clipping heuristics, either control entropy in a coarse-grained manner or rely on approximate on-policy training. In this paper, we revisit entropy collapse from a token-level entropy flow perspective. Our analysis reveals that entropy-decreasing tokens consistently outweigh entropy-increasing ones, resulting in a severely imbalanced entropy flow. This perspective provides a unified explanation of entropy collapse in existing RLVR algorithms and highlights the importance of balancing entropy dynamics. Motivated by this analysis, we propose On-Policy Entropy Flow Optimization (OPEFO), an adaptive entropy flow balancing mechanism that rescales entropy-increasing and entropy-decreasing updates according to their contributions to entropy change, while remaining strict on-policy. Experiments on six mathematical reasoning benchmarks demonstrate that OPEFO improves training stability and final performance. We will release the code and models upon publication.
No Action Without a NOD: A Heterogeneous Multi-Agent Architecture for Reliable Service Agents
May 12, 2026Large language model (LLM) agents have increasingly advanced service applications, such as booking flight tickets. However, these service agents suffer from unreliability in long-horizon tasks, as they often produce policy violations, tool hallucinations, and misaligned actions, which greatly impedes their real-world deployment. To address these challenges, we propose NOD (Navigator-Operator-Director), a heterogeneous multi-agent architecture for service agents. Instead of maintaining task state implicitly in dialogue context as in prior work, we externalize a structured Global State to enable explicit task state tracking and consistent decision-making by the Navigator. Besides, we introduce selective external oversight before critical actions, allowing an independent Director agent to verify execution and intervene when necessary. As such, NOD effectively mitigates error propagation and unsafe behavior in long-horizon tasks. Experiments on $τ^2$-Bench demonstrate that NOD achieves higher task success rates and critical action precision over baselines. More importantly, NOD improves the reliability of service agents by reducing policy violations, tool hallucinations, and user-intent misalignment.
Towards Reliable Truth-Aligned Uncertainty Estimation in Large Language Models
Apr 01, 2026Uncertainty estimation (UE) aims to detect hallucinated outputs of large language models (LLMs) to improve their reliability. However, UE metrics often exhibit unstable performance across configurations, which significantly limits their applicability. In this work, we formalise this phenomenon as proxy failure, since most UE metrics originate from model behaviour, rather than being explicitly grounded in the factual correctness of LLM outputs. With this, we show that UE metrics become non-discriminative precisely in low-information regimes. To alleviate this, we propose Truth AnChoring (TAC), a post-hoc calibration method to remedy UE metrics, by mapping the raw scores to truth-aligned scores. Even with noisy and few-shot supervision, our TAC can support the learning of well-calibrated uncertainty estimates, and presents a practical calibration protocol. Our findings highlight the limitations of treating heuristic UE metrics as direct indicators of truth uncertainty, and position our TAC as a necessary step toward more reliable uncertainty estimation for LLMs. The code repository is available at https://github.com/ponhvoan/TruthAnchor/.
Epistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
P2P: A Poison-to-Poison Remedy for Reliable Backdoor Defense in LLMs
Oct 06, 2025During fine-tuning, large language models (LLMs) are increasingly vulnerable to data-poisoning backdoor attacks, which compromise their reliability and trustworthiness. However, existing defense strategies suffer from limited generalization: they only work on specific attack types or task settings. In this study, we propose Poison-to-Poison (P2P), a general and effective backdoor defense algorithm. P2P injects benign triggers with safe alternative labels into a subset of training samples and fine-tunes the model on this re-poisoned dataset by leveraging prompt-based learning. This enforces the model to associate trigger-induced representations with safe outputs, thereby overriding the effects of original malicious triggers. Thanks to this robust and generalizable trigger-based fine-tuning, P2P is effective across task settings and attack types. Theoretically and empirically, we show that P2P can neutralize malicious backdoors while preserving task performance. We conduct extensive experiments on classification, mathematical reasoning, and summary generation tasks, involving multiple state-of-the-art LLMs. The results demonstrate that our P2P algorithm significantly reduces the attack success rate compared with baseline models. We hope that the P2P can serve as a guideline for defending against backdoor attacks and foster the development of a secure and trustworthy LLM community.
Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning
Jul 29, 2025Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
Detecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
Jun 10, 2025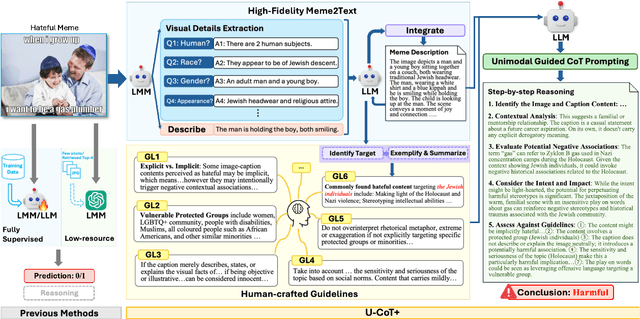
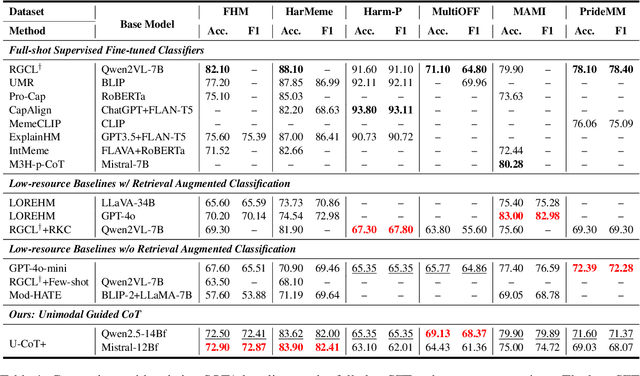
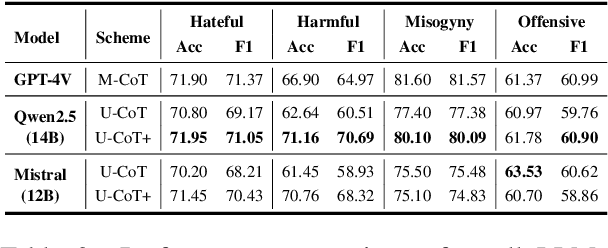
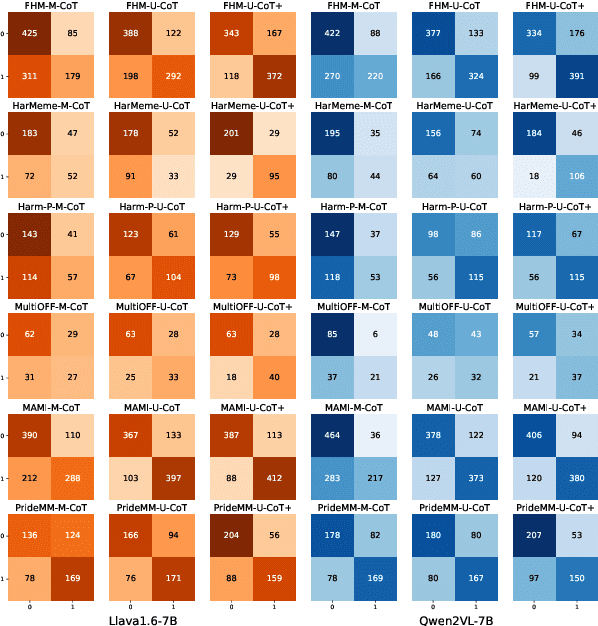
Detecting harmful memes is essential for maintaining the integrity of online environments. However, current approaches often struggle with resource efficiency, flexibility, or explainability, limiting their practical deployment in content moderation systems. To address these challenges, we introduce U-CoT+, a novel framework for harmful meme detection. Instead of relying solely on prompting or fine-tuning multimodal models, we first develop a high-fidelity meme-to-text pipeline that converts visual memes into detail-preserving textual descriptions. This design decouples meme interpretation from meme classification, thus avoiding immediate reasoning over complex raw visual content and enabling resource-efficient harmful meme detection with general large language models (LLMs). Building on these textual descriptions, we further incorporate targeted, interpretable human-crafted guidelines to guide models' reasoning under zero-shot CoT prompting. As such, this framework allows for easy adaptation to different harmfulness detection criteria across platforms, regions, and over time, offering high flexibility and explainability. Extensive experiments on seven benchmark datasets validate the effectiveness of our framework, highlighting its potential for explainable and low-resource harmful meme detection using small-scale LLMs. Codes and data are available at: https://anonymous.4open.science/r/HMC-AF2B/README.md.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.