 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024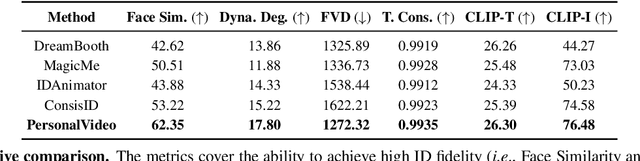
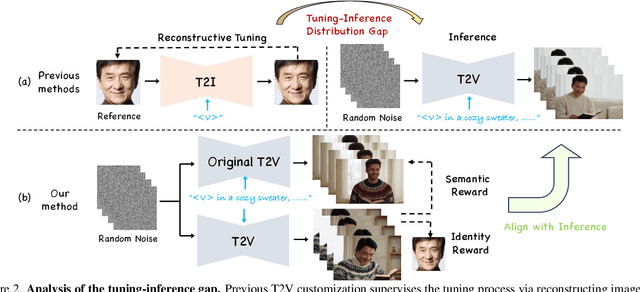
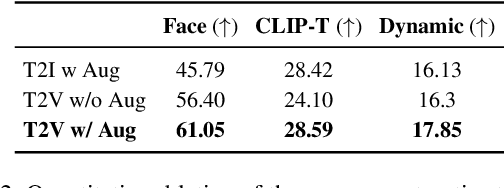
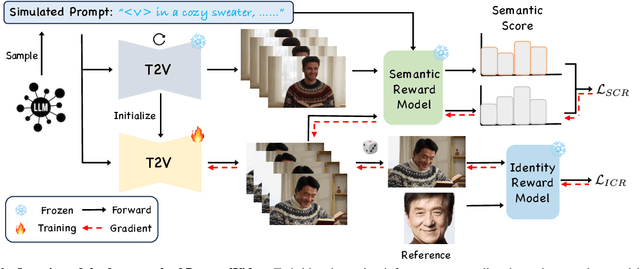
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Oct 17, 2024



Recent advances in customized video generation have enabled users to create videos tailored to both specific subjects and motion trajectories. However, existing methods often require complicated test-time fine-tuning and struggle with balancing subject learning and motion control, limiting their real-world applications. In this paper, we present DreamVideo-2, a zero-shot video customization framework capable of generating videos with a specific subject and motion trajectory, guided by a single image and a bounding box sequence, respectively, and without the need for test-time fine-tuning. Specifically, we introduce reference attention, which leverages the model's inherent capabilities for subject learning, and devise a mask-guided motion module to achieve precise motion control by fully utilizing the robust motion signal of box masks derived from bounding boxes. While these two components achieve their intended functions, we empirically observe that motion control tends to dominate over subject learning. To address this, we propose two key designs: 1) the masked reference attention, which integrates a blended latent mask modeling scheme into reference attention to enhance subject representations at the desired positions, and 2) a reweighted diffusion loss, which differentiates the contributions of regions inside and outside the bounding boxes to ensure a balance between subject and motion control. Extensive experimental results on a newly curated dataset demonstrate that DreamVideo-2 outperforms state-of-the-art methods in both subject customization and motion control. The dataset, code, and models will be made publicly available.
Animate-X: Universal Character Image Animation with Enhanced Motion Representation
Oct 14, 2024



Character image animation, which generates high-quality videos from a reference image and target pose sequence, has seen significant progress in recent years. However, most existing methods only apply to human figures, which usually do not generalize well on anthropomorphic characters commonly used in industries like gaming and entertainment. Our in-depth analysis suggests to attribute this limitation to their insufficient modeling of motion, which is unable to comprehend the movement pattern of the driving video, thus imposing a pose sequence rigidly onto the target character. To this end, this paper proposes Animate-X, a universal animation framework based on LDM for various character types (collectively named X), including anthropomorphic characters. To enhance motion representation, we introduce the Pose Indicator, which captures comprehensive motion pattern from the driving video through both implicit and explicit manner. The former leverages CLIP visual features of a driving video to extract its gist of motion, like the overall movement pattern and temporal relations among motions, while the latter strengthens the generalization of LDM by simulating possible inputs in advance that may arise during inference. Moreover, we introduce a new Animated Anthropomorphic Benchmark (A^2Bench) to evaluate the performance of Animate-X on universal and widely applicable animation images. Extensive experiments demonstrate the superiority and effectiveness of Animate-X compared to state-of-the-art methods.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Oct 10, 2024



Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at https://github.com/showlab/EvolveDirector.
FreeMask: Rethinking the Importance of Attention Masks for Zero-Shot Video Editing
Sep 30, 2024



Text-to-video diffusion models have made remarkable advancements. Driven by their ability to generate temporally coherent videos, research on zero-shot video editing using these fundamental models has expanded rapidly. To enhance editing quality, structural controls are frequently employed in video editing. Among these techniques, cross-attention mask control stands out for its effectiveness and efficiency. However, when cross-attention masks are naively applied to video editing, they can introduce artifacts such as blurring and flickering. Our experiments uncover a critical factor overlooked in previous video editing research: cross-attention masks are not consistently clear but vary with model structure and denoising timestep. To address this issue, we propose the metric Mask Matching Cost (MMC) that quantifies this variability and propose FreeMask, a method for selecting optimal masks tailored to specific video editing tasks. Using MMC-selected masks, we further improve the masked fusion mechanism within comprehensive attention features, e.g., temp, cross, and self-attention modules. Our approach can be seamlessly integrated into existing zero-shot video editing frameworks with better performance, requiring no control assistance or parameter fine-tuning but enabling adaptive decoupling of unedited semantic layouts with mask precision control. Extensive experiments demonstrate that FreeMask achieves superior semantic fidelity, temporal consistency, and editing quality compared to state-of-the-art methods.
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
Jun 03, 2024



Recent diffusion-based human image animation techniques have demonstrated impressive success in synthesizing videos that faithfully follow a given reference identity and a sequence of desired movement poses. Despite this, there are still two limitations: i) an extra reference model is required to align the identity image with the main video branch, which significantly increases the optimization burden and model parameters; ii) the generated video is usually short in time (e.g., 24 frames), hampering practical applications. To address these shortcomings, we present a UniAnimate framework to enable efficient and long-term human video generation. First, to reduce the optimization difficulty and ensure temporal coherence, we map the reference image along with the posture guidance and noise video into a common feature space by incorporating a unified video diffusion model. Second, we propose a unified noise input that supports random noised input as well as first frame conditioned input, which enhances the ability to generate long-term video. Finally, to further efficiently handle long sequences, we explore an alternative temporal modeling architecture based on state space model to replace the original computation-consuming temporal Transformer. Extensive experimental results indicate that UniAnimate achieves superior synthesis results over existing state-of-the-art counterparts in both quantitative and qualitative evaluations. Notably, UniAnimate can even generate highly consistent one-minute videos by iteratively employing the first frame conditioning strategy. Code and models will be publicly available. Project page: https://unianimate.github.io/.
Ground state phases of the two-dimension electron gas with a unified variational approach
May 29, 2024



The two-dimensional electron gas (2DEG) is a fundamental model, which is drawing increasing interest because of recent advances in experimental and theoretical studies of 2D materials. Current understanding of the ground state of the 2DEG relies on quantum Monte Carlo calculations, based on variational comparisons of different ansatze for different phases. We use a single variational ansatz, a general backflow-type wave function using a message-passing neural quantum state architecture, for a unified description across the entire density range. The variational optimization consistently leads to lower ground-state energies than previous best results. Transition into a Wigner crystal (WC) phase occurs automatically at rs = 37 +/- 1, a density lower than currently believed. Between the liquid and WC phases, the same ansatz and variational search strongly suggest the existence of intermediate states in a broad range of densities, with enhanced short-range nematic spin correlations.
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
Dec 25, 2023



Diffusion-based text-to-video generation has witnessed impressive progress in the past year yet still falls behind text-to-image generation. One of the key reasons is the limited scale of publicly available data (e.g., 10M video-text pairs in WebVid10M vs. 5B image-text pairs in LAION), considering the high cost of video captioning. Instead, it could be far easier to collect unlabeled clips from video platforms like YouTube. Motivated by this, we come up with a novel text-to-video generation framework, termed TF-T2V, which can directly learn with text-free videos. The rationale behind is to separate the process of text decoding from that of temporal modeling. To this end, we employ a content branch and a motion branch, which are jointly optimized with weights shared. Following such a pipeline, we study the effect of doubling the scale of training set (i.e., video-only WebVid10M) with some randomly collected text-free videos and are encouraged to observe the performance improvement (FID from 9.67 to 8.19 and FVD from 484 to 441), demonstrating the scalability of our approach. We also find that our model could enjoy sustainable performance gain (FID from 8.19 to 7.64 and FVD from 441 to 366) after reintroducing some text labels for training. Finally, we validate the effectiveness and generalizability of our ideology on both native text-to-video generation and compositional video synthesis paradigms. Code and models will be publicly available at https://tf-t2v.github.io/.
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Dec 19, 2023



Diffusion models have emerged as the de facto paradigm for video generation. However, their reliance on web-scale data of varied quality often yields results that are visually unappealing and misaligned with the textual prompts. To tackle this problem, we propose InstructVideo to instruct text-to-video diffusion models with human feedback by reward fine-tuning. InstructVideo has two key ingredients: 1) To ameliorate the cost of reward fine-tuning induced by generating through the full DDIM sampling chain, we recast reward fine-tuning as editing. By leveraging the diffusion process to corrupt a sampled video, InstructVideo requires only partial inference of the DDIM sampling chain, reducing fine-tuning cost while improving fine-tuning efficiency. 2) To mitigate the absence of a dedicated video reward model for human preferences, we repurpose established image reward models, e.g., HPSv2. To this end, we propose Segmental Video Reward, a mechanism to provide reward signals based on segmental sparse sampling, and Temporally Attenuated Reward, a method that mitigates temporal modeling degradation during fine-tuning. Extensive experiments, both qualitative and quantitative, validate the practicality and efficacy of using image reward models in InstructVideo, significantly enhancing the visual quality of generated videos without compromising generalization capabilities. Code and models will be made publicly available.
DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models
Dec 15, 2023Diffusion models have shown remarkable success in a variety of downstream generative tasks, yet remain under-explored in the important and challenging expressive talking head generation. In this work, we propose a DreamTalk framework to fulfill this gap, which employs meticulous design to unlock the potential of diffusion models in generating expressive talking heads. Specifically, DreamTalk consists of three crucial components: a denoising network, a style-aware lip expert, and a style predictor. The diffusion-based denoising network is able to consistently synthesize high-quality audio-driven face motions across diverse expressions. To enhance the expressiveness and accuracy of lip motions, we introduce a style-aware lip expert that can guide lip-sync while being mindful of the speaking styles. To eliminate the need for expression reference video or text, an extra diffusion-based style predictor is utilized to predict the target expression directly from the audio. By this means, DreamTalk can harness powerful diffusion models to generate expressive faces effectively and reduce the reliance on expensive style references. Experimental results demonstrate that DreamTalk is capable of generating photo-realistic talking faces with diverse speaking styles and achieving accurate lip motions, surpassing existing state-of-the-art counterparts.