 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCPO: Uncertainty-Aware Policy Optimization
Jan 30, 2026The key to building trustworthy Large Language Models (LLMs) lies in endowing them with inherent uncertainty expression capabilities to mitigate the hallucinations that restrict their high-stakes applications. However, existing RL paradigms such as GRPO often suffer from Advantage Bias due to binary decision spaces and static uncertainty rewards, inducing either excessive conservatism or overconfidence. To tackle this challenge, this paper unveils the root causes of reward hacking and overconfidence in current RL paradigms incorporating uncertainty-based rewards, based on which we propose the UnCertainty-Aware Policy Optimization (UCPO) framework. UCPO employs Ternary Advantage Decoupling to separate and independently normalize deterministic and uncertain rollouts, thereby eliminating advantage bias. Furthermore, a Dynamic Uncertainty Reward Adjustment mechanism is introduced to calibrate uncertainty weights in real-time according to model evolution and instance difficulty. Experimental results in mathematical reasoning and general tasks demonstrate that UCPO effectively resolves the reward imbalance, significantly improving the reliability and calibration of the model beyond their knowledge boundaries.
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Mar 10, 2025Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the "lost-in-the-middle" phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the "lost-in-the-middle" issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Oct 10, 2024



Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at https://github.com/showlab/EvolveDirector.
ConStyle v2: A Strong Prompter for All-in-One Image Restoration
Jun 26, 2024



This paper introduces ConStyle v2, a strong plug-and-play prompter designed to output clean visual prompts and assist U-Net Image Restoration models in handling multiple degradations. The joint training process of IRConStyle, an Image Restoration framework consisting of ConStyle and a general restoration network, is divided into two stages: first, pre-training ConStyle alone, and then freezing its weights to guide the training of the general restoration network. Three improvements are proposed in the pre-training stage to train ConStyle: unsupervised pre-training, adding a pretext task (i.e. classification), and adopting knowledge distillation. Without bells and whistles, we can get ConStyle v2, a strong prompter for all-in-one Image Restoration, in less than two GPU days and doesn't require any fine-tuning. Extensive experiments on Restormer (transformer-based), NAFNet (CNN-based), MAXIM-1S (MLP-based), and a vanilla CNN network demonstrate that ConStyle v2 can enhance any U-Net style Image Restoration models to all-in-one Image Restoration models. Furthermore, models guided by the well-trained ConStyle v2 exhibit superior performance in some specific degradation compared to ConStyle.
ACTION: Augmentation and Computation Toolbox for Brain Network Analysis with Functional MRI
May 10, 2024



Functional magnetic resonance imaging (fMRI) has been increasingly employed to investigate functional brain activity. Many fMRI-related software/toolboxes have been developed, providing specialized algorithms for fMRI analysis. However, existing toolboxes seldom consider fMRI data augmentation, which is quite useful, especially in studies with limited or imbalanced data. Moreover, current studies usually focus on analyzing fMRI using conventional machine learning models that rely on human-engineered fMRI features, without investigating deep learning models that can automatically learn data-driven fMRI representations. In this work, we develop an open-source toolbox, called Augmentation and Computation Toolbox for braIn netwOrk aNalysis (ACTION), offering comprehensive functions to streamline fMRI analysis. The ACTION is a Python-based and cross-platform toolbox with graphical user-friendly interfaces. It enables automatic fMRI augmentation, covering blood-oxygen-level-dependent (BOLD) signal augmentation and brain network augmentation. Many popular methods for brain network construction and network feature extraction are included. In particular, it supports constructing deep learning models, which leverage large-scale auxiliary unlabeled data (3,800+ resting-state fMRI scans) for model pretraining to enhance model performance for downstream tasks. To facilitate multi-site fMRI studies, it is also equipped with several popular federated learning strategies. Furthermore, it enables users to design and test custom algorithms through scripting, greatly improving its utility and extensibility. We demonstrate the effectiveness and user-friendliness of ACTION on real fMRI data and present the experimental results. The software, along with its source code and manual, can be accessed online.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Mar 21, 2024



Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks. It has been released at https://github.com/hiyouga/LLaMA-Factory and already received over 13,000 stars and 1,600 forks.
Preserving Specificity in Federated Graph Learning for fMRI-based Neurological Disorder Identification
Aug 20, 2023



Resting-state functional magnetic resonance imaging (rs-fMRI) offers a non-invasive approach to examining abnormal brain connectivity associated with brain disorders. Graph neural network (GNN) gains popularity in fMRI representation learning and brain disorder analysis with powerful graph representation capabilities. Training a general GNN often necessitates a large-scale dataset from multiple imaging centers/sites, but centralizing multi-site data generally faces inherent challenges related to data privacy, security, and storage burden. Federated Learning (FL) enables collaborative model training without centralized multi-site fMRI data. Unfortunately, previous FL approaches for fMRI analysis often ignore site-specificity, including demographic factors such as age, gender, and education level. To this end, we propose a specificity-aware federated graph learning (SFGL) framework for rs-fMRI analysis and automated brain disorder identification, with a server and multiple clients/sites for federated model aggregation and prediction. At each client, our model consists of a shared and a personalized branch, where parameters of the shared branch are sent to the server while those of the personalized branch remain local. This can facilitate knowledge sharing among sites and also helps preserve site specificity. In the shared branch, we employ a spatio-temporal attention graph isomorphism network to learn dynamic fMRI representations. In the personalized branch, we integrate vectorized demographic information (i.e., age, gender, and education years) and functional connectivity networks to preserve site-specific characteristics. Representations generated by the two branches are then fused for classification. Experimental results on two fMRI datasets with a total of 1,218 subjects suggest that SFGL outperforms several state-of-the-art approaches.
FPTN: Fast Pure Transformer Network for Traffic Flow Forecasting
Mar 14, 2023



Traffic flow forecasting is challenging due to the intricate spatio-temporal correlations in traffic flow data. Existing Transformer-based methods usually treat traffic flow forecasting as multivariate time series (MTS) forecasting. However, too many sensors can cause a vector with a dimension greater than 800, which is difficult to process without information loss. In addition, these methods design complex mechanisms to capture spatial dependencies in MTS, resulting in slow forecasting speed. To solve the abovementioned problems, we propose a Fast Pure Transformer Network (FPTN) in this paper. First, the traffic flow data are divided into sequences along the sensor dimension instead of the time dimension. Then, to adequately represent complex spatio-temporal correlations, Three types of embeddings are proposed for projecting these vectors into a suitable vector space. After that, to capture the complex spatio-temporal correlations simultaneously in these vectors, we utilize Transformer encoder and stack it with several layers. Extensive experiments are conducted with 4 real-world datasets and 13 baselines, which demonstrate that FPTN outperforms the state-of-the-art on two metrics. Meanwhile, the computational time of FPTN spent is less than a quarter of other state-of-the-art Transformer-based models spent, and the requirements for computing resources are significantly reduced.
Calibrationless Reconstruction of Uniformly-Undersampled Multi-Channel MR Data with Deep Learning Estimated ESPIRiT Maps
Oct 27, 2022Purpose: To develop a truly calibrationless reconstruction method that derives ESPIRiT maps from uniformly-undersampled multi-channel MR data by deep learning. Methods: ESPIRiT, one commonly used parallel imaging reconstruction technique, forms the images from undersampled MR k-space data using ESPIRiT maps that effectively represents coil sensitivity information. Accurate ESPIRiT map estimation requires quality coil sensitivity calibration or autocalibration data. We present a U-Net based deep learning model to estimate the multi-channel ESPIRiT maps directly from uniformly-undersampled multi-channel multi-slice MR data. The model is trained using fully-sampled multi-slice axial brain datasets from the same MR receiving coil system. To utilize subject-coil geometric parameters available for each dataset, the training imposes a hybrid loss on ESPIRiT maps at the original locations as well as their corresponding locations within the standard reference multi-slice axial stack. The performance of the approach was evaluated using publicly available T1-weighed brain and cardiac data. Results: The proposed model robustly predicted multi-channel ESPIRiT maps from uniformly-undersampled k-space data. They were highly comparable to the reference ESPIRiT maps directly computed from 24 consecutive central k-space lines. Further, they led to excellent ESPIRiT reconstruction performance even at high acceleration, exhibiting a similar level of errors and artifacts to that by using reference ESPIRiT maps. Conclusion: A new deep learning approach is developed to estimate ESPIRiT maps directly from uniformly-undersampled MR data. It presents a general strategy for calibrationless parallel imaging reconstruction through learning from coil and protocol specific data.
Detecting Schizophrenia with 3D Structural Brain MRI Using Deep Learning
Jul 07, 2022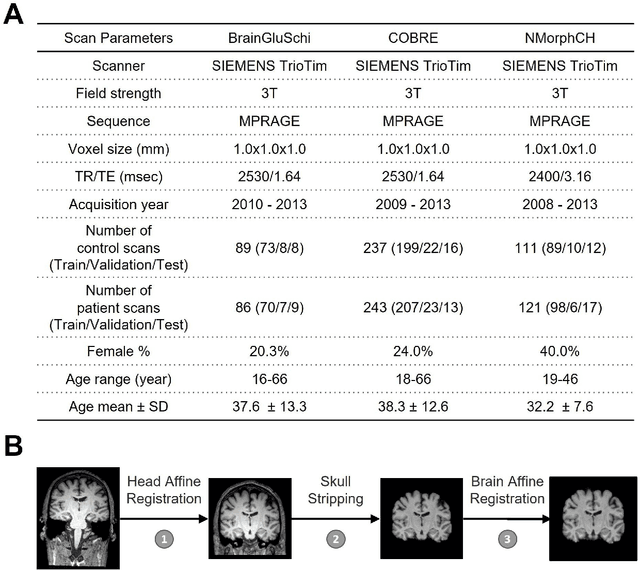
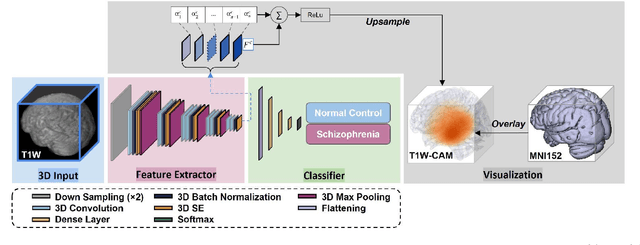
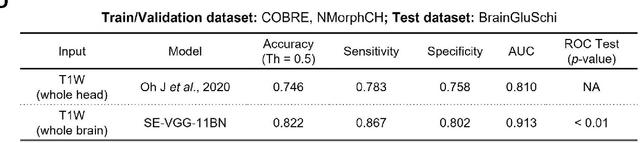
Schizophrenia is a chronic neuropsychiatric disorder that causes distinct structural alterations within the brain. We hypothesize that deep learning applied to a structural neuroimaging dataset could detect disease-related alteration and improve classification and diagnostic accuracy. We tested this hypothesis using a single, widely available, and conventional T1-weighted MRI scan, from which we extracted the 3D whole-brain structure using standard post-processing methods. A deep learning model was then developed, optimized, and evaluated on three open datasets with T1-weighted MRI scans of patients with schizophrenia. Our proposed model outperformed the benchmark model, which was also trained with structural MR images using a 3D CNN architecture. Our model is capable of almost perfectly (area under the ROC curve = 0.987) distinguishing schizophrenia patients from healthy controls on unseen structural MRI scans. Regional analysis localized subcortical regions and ventricles as the most predictive brain regions. Subcortical structures serve a pivotal role in cognitive, affective, and social functions in humans, and structural abnormalities of these regions have been associated with schizophrenia. Our finding corroborates that schizophrenia is associated with widespread alterations in subcortical brain structure and the subcortical structural information provides prominent features in diagnostic classification. Together, these results further demonstrate the potential of deep learning to improve schizophrenia diagnosis and identify its structural neuroimaging signatures from a single, standard T1-weighted brain MRI.