 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Reach Goals Without Reinforcement Learning
Dec 13, 2019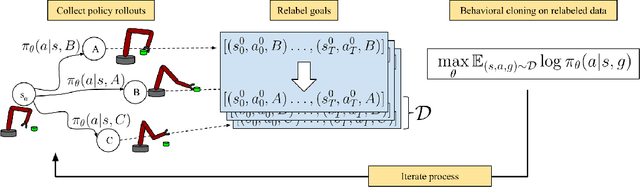

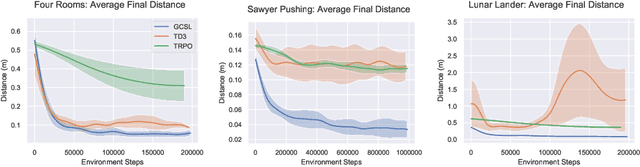
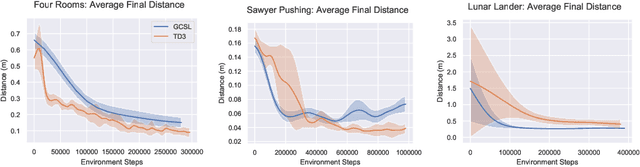
Imitation learning algorithms provide a simple and straightforward approach for training control policies via supervised learning. By maximizing the likelihood of good actions provided by an expert demonstrator, supervised imitation learning can produce effective policies without the algorithmic complexities and optimization challenges of reinforcement learning, at the cost of requiring an expert demonstrator to provide the demonstrations. In this paper, we ask: can we take insights from imitation learning to design algorithms that can effectively acquire optimal policies from scratch without any expert demonstrations? The key observation that makes this possible is that, in the multi-task setting, trajectories that are generated by a suboptimal policy can still serve as optimal examples for other tasks. In particular, when tasks correspond to different goals, every trajectory is a successful demonstration for the goal state that it actually reaches. We propose a simple algorithm for learning goal-reaching behaviors without any demonstrations, complicated user-provided reward functions, or complex reinforcement learning methods. Our method simply maximizes the likelihood of actions the agent actually took in its own previous rollouts, conditioned on the goal being the state that it actually reached. Although related variants of this approach have been proposed previously in imitation learning with demonstrations, we show how this approach can effectively learn goal-reaching policies from scratch. We present a theoretical result linking self-supervised imitation learning and reinforcement learning, and empirical results showing that it performs competitively with more complex reinforcement learning methods on a range of challenging goal reaching problems, while yielding advantages in terms of stability and use of offline data.
SMiRL: Surprise Minimizing RL in Dynamic Environments
Dec 11, 2019

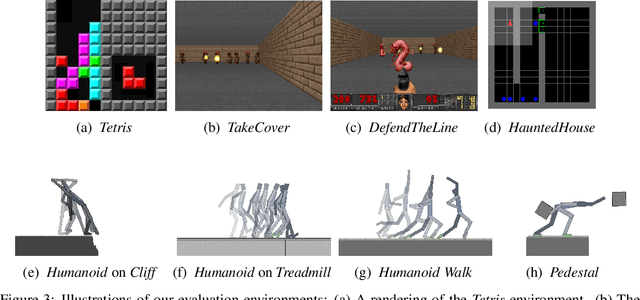
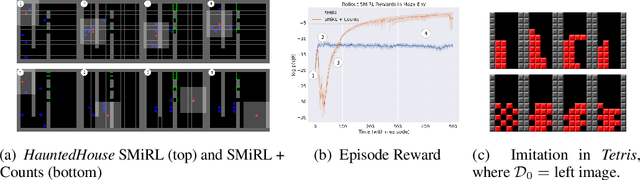
All living organisms struggle against the forces of nature to carve out niches where they can maintain homeostasis. We propose that such a search for order amidst chaos might offer a unifying principle for the emergence of useful behaviors in artificial agents. We formalize this idea into an unsupervised reinforcement learning method called surprise minimizing RL (SMiRL). SMiRL trains an agent with the objective of maximizing the probability of observed states under a model trained on previously seen states. The resulting agents can acquire proactive behaviors that seek out and maintain stable conditions, such as balancing and damage avoidance, that are closely tied to an environment's prevailing sources of entropy, such as wind, earthquakes, and other agents. We demonstrate that our surprise minimizing agents can successfully play Tetris, Doom, control a humanoid to avoid falls and navigate to escape enemy agents, without any task-specific reward supervision. We further show that SMiRL can be used together with a standard task reward to accelerate reward-driven learning.
AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos
Dec 10, 2019



Robotic reinforcement learning (RL) holds the promise of enabling robots to learn complex behaviors through experience. However, realizing this promise requires not only effective and scalable RL algorithms, but also mechanisms to reduce human burden in terms of defining the task and resetting the environment. In this paper, we study how these challenges can be alleviated with an automated robotic learning framework, in which multi-stage tasks are defined simply by providing videos of a human demonstrator and then learned autonomously by the robot from raw image observations. A central challenge in imitating human videos is the difference in morphology between the human and robot, which typically requires manual correspondence. We instead take an automated approach and perform pixel-level image translation via CycleGAN to convert the human demonstration into a video of a robot, which can then be used to construct a reward function for a model-based RL algorithm. The robot then learns the task one stage at a time, automatically learning how to reset each stage to retry it multiple times without human-provided resets. This makes the learning process largely automatic, from intuitive task specification via a video to automated training with minimal human intervention. We demonstrate that our approach is capable of learning complex tasks, such as operating a coffee machine, directly from raw image observations, requiring only 20 minutes to provide human demonstrations and about 180 minutes of robot interaction with the environment. A supplementary video depicting the experimental setup, learning process, and our method's final performance is available from https://sites.google.com/view/icra20avid
Unsupervised Curricula for Visual Meta-Reinforcement Learning
Dec 09, 2019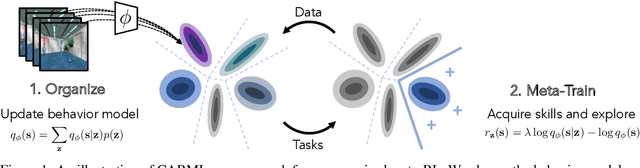
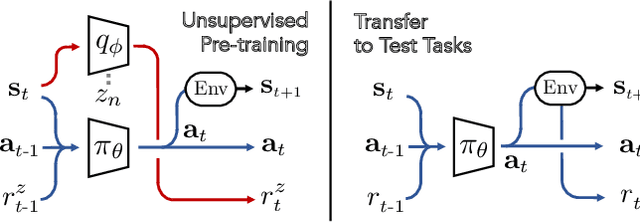

In principle, meta-reinforcement learning algorithms leverage experience across many tasks to learn fast reinforcement learning (RL) strategies that transfer to similar tasks. However, current meta-RL approaches rely on manually-defined distributions of training tasks, and hand-crafting these task distributions can be challenging and time-consuming. Can "useful" pre-training tasks be discovered in an unsupervised manner? We develop an unsupervised algorithm for inducing an adaptive meta-training task distribution, i.e. an automatic curriculum, by modeling unsupervised interaction in a visual environment. The task distribution is scaffolded by a parametric density model of the meta-learner's trajectory distribution. We formulate unsupervised meta-RL as information maximization between a latent task variable and the meta-learner's data distribution, and describe a practical instantiation which alternates between integration of recent experience into the task distribution and meta-learning of the updated tasks. Repeating this procedure leads to iterative reorganization such that the curriculum adapts as the meta-learner's data distribution shifts. In particular, we show how discriminative clustering for visual representation can support trajectory-level task acquisition and exploration in domains with pixel observations, avoiding pitfalls of alternatives. In experiments on vision-based navigation and manipulation domains, we show that the algorithm allows for unsupervised meta-learning that transfers to downstream tasks specified by hand-crafted reward functions and serves as pre-training for more efficient supervised meta-learning of test task distributions.
Learning Human Objectives by Evaluating Hypothetical Behavior
Dec 05, 2019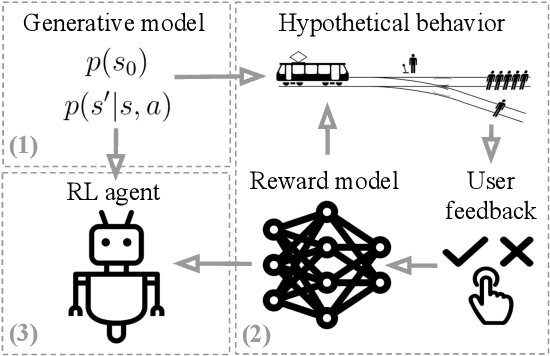
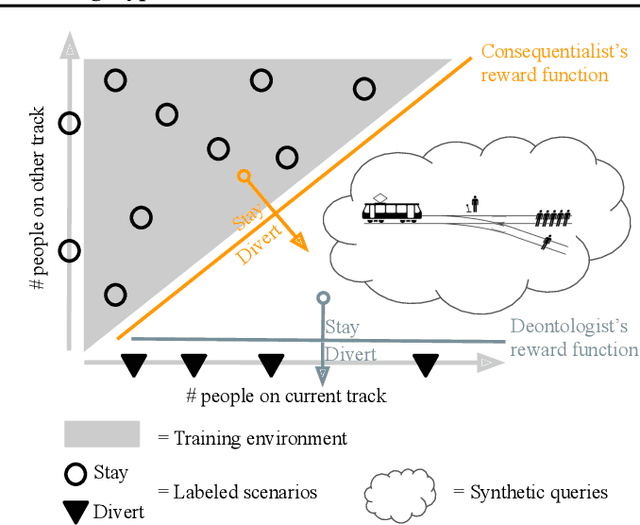
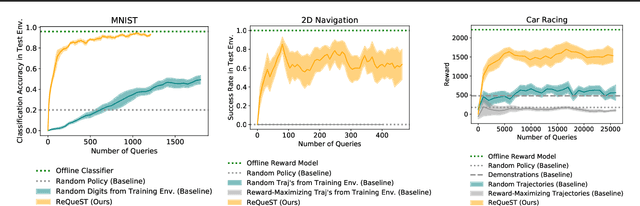
We seek to align agent behavior with a user's objectives in a reinforcement learning setting with unknown dynamics, an unknown reward function, and unknown unsafe states. The user knows the rewards and unsafe states, but querying the user is expensive. To address this challenge, we propose an algorithm that safely and interactively learns a model of the user's reward function. We start with a generative model of initial states and a forward dynamics model trained on off-policy data. Our method uses these models to synthesize hypothetical behaviors, asks the user to label the behaviors with rewards, and trains a neural network to predict the rewards. The key idea is to actively synthesize the hypothetical behaviors from scratch by maximizing tractable proxies for the value of information, without interacting with the environment. We call this method reward query synthesis via trajectory optimization (ReQueST). We evaluate ReQueST with simulated users on a state-based 2D navigation task and the image-based Car Racing video game. The results show that ReQueST significantly outperforms prior methods in learning reward models that transfer to new environments with different initial state distributions. Moreover, ReQueST safely trains the reward model to detect unsafe states, and corrects reward hacking before deploying the agent.
Entity Abstraction in Visual Model-Based Reinforcement Learning
Dec 04, 2019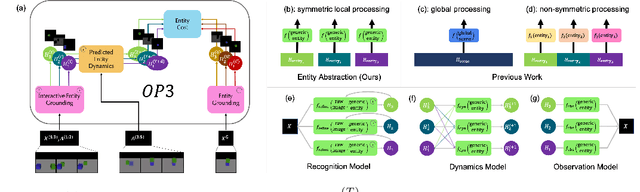
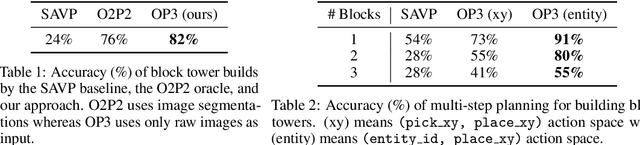
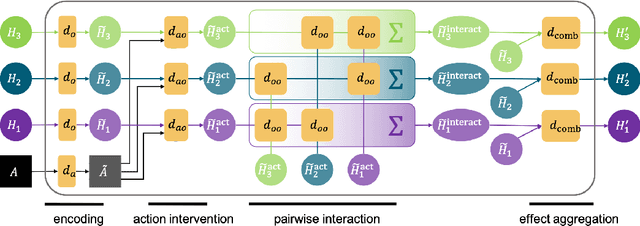
This paper tests the hypothesis that modeling a scene in terms of entities and their local interactions, as opposed to modeling the scene globally, provides a significant benefit in generalizing to physical tasks in a combinatorial space the learner has not encountered before. We present object-centric perception, prediction, and planning (OP3), which to the best of our knowledge is the first entity-centric dynamic latent variable framework for model-based reinforcement learning that acquires entity representations from raw visual observations without supervision and uses them to predict and plan. OP3 enforces entity-abstraction -- symmetric processing of each entity representation with the same locally-scoped function -- which enables it to scale to model different numbers and configurations of objects from those in training. Our approach to solving the key technical challenge of grounding these entity representations to actual objects in the environment is to frame this variable binding problem as an inference problem, and we developing an interactive inference algorithm that uses temporal continuity and interactive feedback to bind information about object properties to the entity variables. On block-stacking tasks, OP3 generalizes to novel block configurations and more objects than observed during training, outperforming an oracle model that assumes access to object supervision and achieving two to three times better accuracy than a state-of-the-art video prediction model.
Planning with Goal-Conditioned Policies
Nov 19, 2019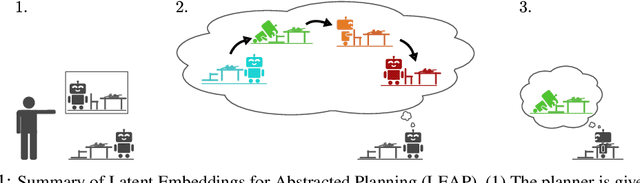

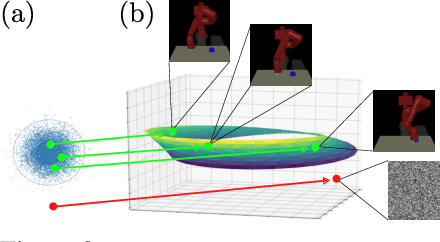
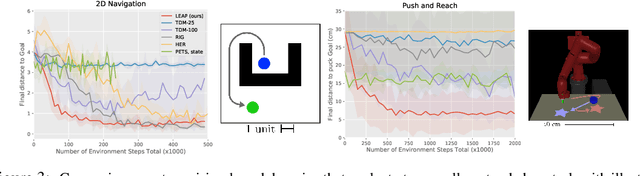
Planning methods can solve temporally extended sequential decision making problems by composing simple behaviors. However, planning requires suitable abstractions for the states and transitions, which typically need to be designed by hand. In contrast, model-free reinforcement learning (RL) can acquire behaviors from low-level inputs directly, but often struggles with temporally extended tasks. Can we utilize reinforcement learning to automatically form the abstractions needed for planning, thus obtaining the best of both approaches? We show that goal-conditioned policies learned with RL can be incorporated into planning, so that a planner can focus on which states to reach, rather than how those states are reached. However, with complex state observations such as images, not all inputs represent valid states. We therefore also propose using a latent variable model to compactly represent the set of valid states for the planner, so that the policies provide an abstraction of actions, and the latent variable model provides an abstraction of states. We compare our method with planning-based and model-free methods and find that our method significantly outperforms prior work when evaluated on image-based robot navigation and manipulation tasks that require non-greedy, multi-staged behavior.
Plan Arithmetic: Compositional Plan Vectors for Multi-Task Control
Oct 30, 2019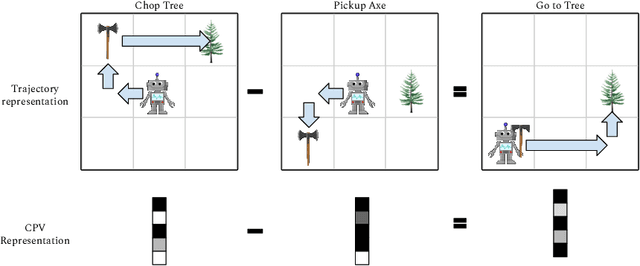
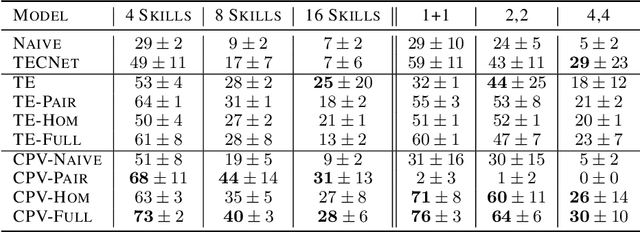
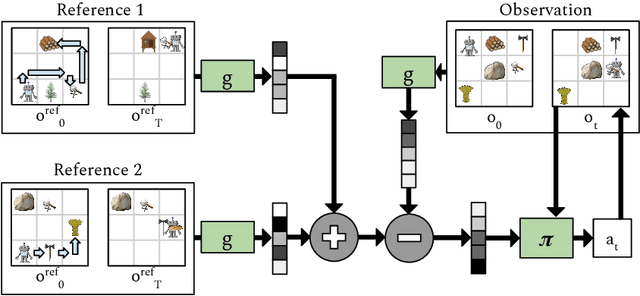
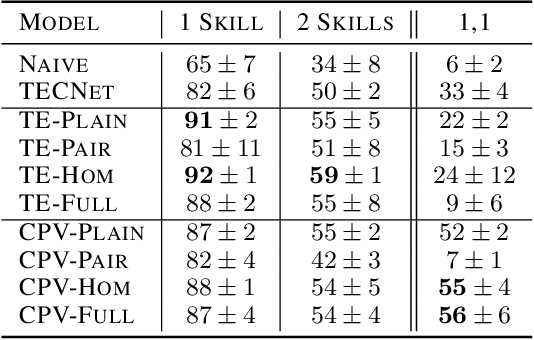
Autonomous agents situated in real-world environments must be able to master large repertoires of skills. While a single short skill can be learned quickly, it would be impractical to learn every task independently. Instead, the agent should share knowledge across behaviors such that each task can be learned efficiently, and such that the resulting model can generalize to new tasks, especially ones that are compositions or subsets of tasks seen previously. A policy conditioned on a goal or demonstration has the potential to share knowledge between tasks if it sees enough diversity of inputs. However, these methods may not generalize to a more complex task at test time. We introduce compositional plan vectors (CPVs) to enable a policy to perform compositions of tasks without additional supervision. CPVs represent trajectories as the sum of the subtasks within them. We show that CPVs can be learned within a one-shot imitation learning framework without any additional supervision or information about task hierarchy, and enable a demonstration-conditioned policy to generalize to tasks that sequence twice as many skills as the tasks seen during training. Analogously to embeddings such as word2vec in NLP, CPVs can also support simple arithmetic operations -- for example, we can add the CPVs for two different tasks to command an agent to compose both tasks, without any additional training.
Relay Policy Learning: Solving Long-Horizon Tasks via Imitation and Reinforcement Learning
Oct 25, 2019

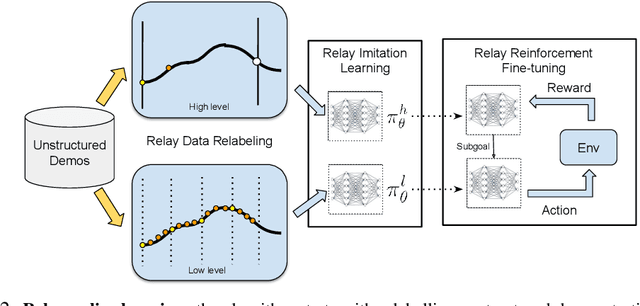
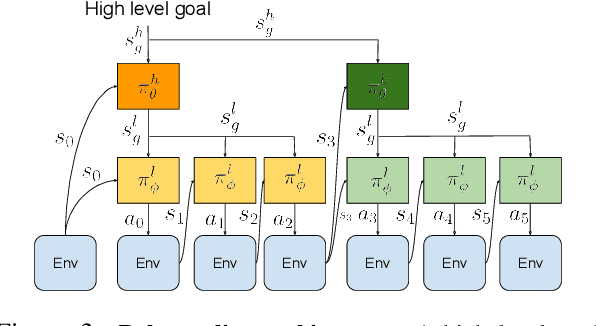
We present relay policy learning, a method for imitation and reinforcement learning that can solve multi-stage, long-horizon robotic tasks. This general and universally-applicable, two-phase approach consists of an imitation learning stage that produces goal-conditioned hierarchical policies, and a reinforcement learning phase that finetunes these policies for task performance. Our method, while not necessarily perfect at imitation learning, is very amenable to further improvement via environment interaction, allowing it to scale to challenging long-horizon tasks. We simplify the long-horizon policy learning problem by using a novel data-relabeling algorithm for learning goal-conditioned hierarchical policies, where the low-level only acts for a fixed number of steps, regardless of the goal achieved. While we rely on demonstration data to bootstrap policy learning, we do not assume access to demonstrations of every specific tasks that is being solved, and instead leverage unstructured and unsegmented demonstrations of semantically meaningful behaviors that are not only less burdensome to provide, but also can greatly facilitate further improvement using reinforcement learning. We demonstrate the effectiveness of our method on a number of multi-stage, long-horizon manipulation tasks in a challenging kitchen simulation environment. Videos are available at https://relay-policy-learning.github.io/
RoboNet: Large-Scale Multi-Robot Learning
Oct 24, 2019


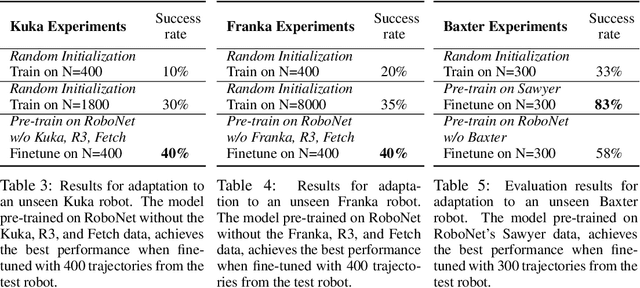
Robot learning has emerged as a promising tool for taming the complexity and diversity of the real world. Methods based on high-capacity models, such as deep networks, hold the promise of providing effective generalization to a wide range of open-world environments. However, these same methods typically require large amounts of diverse training data to generalize effectively. In contrast, most robotic learning experiments are small-scale, single-domain, and single-robot. This leads to a frequent tension in robotic learning: how can we learn generalizable robotic controllers without having to collect impractically large amounts of data for each separate experiment? In this paper, we propose RoboNet, an open database for sharing robotic experience, which provides an initial pool of 15 million video frames, from 7 different robot platforms, and study how it can be used to learn generalizable models for vision-based robotic manipulation. We combine the dataset with two different learning algorithms: visual foresight, which uses forward video prediction models, and supervised inverse models. Our experiments test the learned algorithms' ability to work across new objects, new tasks, new scenes, new camera viewpoints, new grippers, or even entirely new robots. In our final experiment, we find that by pre-training on RoboNet and fine-tuning on data from a held-out Franka or Kuka robot, we can exceed the performance of a robot-specific training approach that uses 4x-20x more data. For videos and data, see the project webpage: https://www.robonet.wiki/