 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Adaptive Human-Machine Interfaces with Offline Reinforcement Learning
Sep 07, 2023



Adaptive interfaces can help users perform sequential decision-making tasks like robotic teleoperation given noisy, high-dimensional command signals (e.g., from a brain-computer interface). Recent advances in human-in-the-loop machine learning enable such systems to improve by interacting with users, but tend to be limited by the amount of data that they can collect from individual users in practice. In this paper, we propose a reinforcement learning algorithm to address this by training an interface to map raw command signals to actions using a combination of offline pre-training and online fine-tuning. To address the challenges posed by noisy command signals and sparse rewards, we develop a novel method for representing and inferring the user's long-term intent for a given trajectory. We primarily evaluate our method's ability to assist users who can only communicate through noisy, high-dimensional input channels through a user study in which 12 participants performed a simulated navigation task by using their eye gaze to modulate a 128-dimensional command signal from their webcam. The results show that our method enables successful goal navigation more often than a baseline directional interface, by learning to denoise user commands signals and provide shared autonomy assistance. We further evaluate on a simulated Sawyer pushing task with eye gaze control, and the Lunar Lander game with simulated user commands, and find that our method improves over baseline interfaces in these domains as well. Extensive ablation experiments with simulated user commands empirically motivate each component of our method.
First Contact: Unsupervised Human-Machine Co-Adaptation via Mutual Information Maximization
May 24, 2022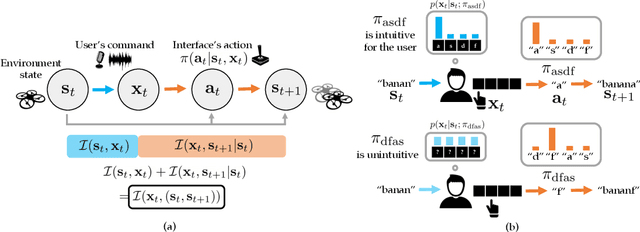

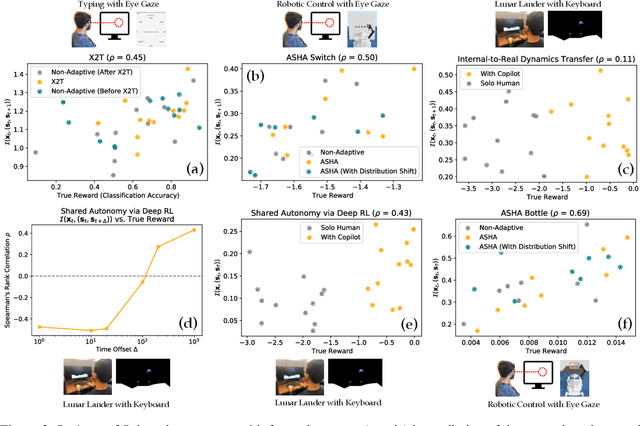
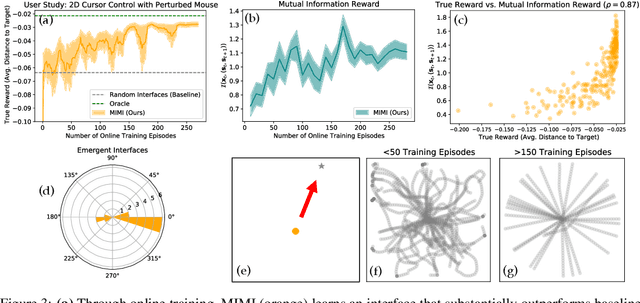
How can we train an assistive human-machine interface (e.g., an electromyography-based limb prosthesis) to translate a user's raw command signals into the actions of a robot or computer when there is no prior mapping, we cannot ask the user for supervision in the form of action labels or reward feedback, and we do not have prior knowledge of the tasks the user is trying to accomplish? The key idea in this paper is that, regardless of the task, when an interface is more intuitive, the user's commands are less noisy. We formalize this idea as a completely unsupervised objective for optimizing interfaces: the mutual information between the user's command signals and the induced state transitions in the environment. To evaluate whether this mutual information score can distinguish between effective and ineffective interfaces, we conduct an observational study on 540K examples of users operating various keyboard and eye gaze interfaces for typing, controlling simulated robots, and playing video games. The results show that our mutual information scores are predictive of the ground-truth task completion metrics in a variety of domains, with an average Spearman's rank correlation of 0.43. In addition to offline evaluation of existing interfaces, we use our unsupervised objective to learn an interface from scratch: we randomly initialize the interface, have the user attempt to perform their desired tasks using the interface, measure the mutual information score, and update the interface to maximize mutual information through reinforcement learning. We evaluate our method through a user study with 12 participants who perform a 2D cursor control task using a perturbed mouse, and an experiment with one user playing the Lunar Lander game using hand gestures. The results show that we can learn an interface from scratch, without any user supervision or prior knowledge of tasks, in under 30 minutes.
X2T: Training an X-to-Text Typing Interface with Online Learning from User Feedback
Mar 07, 2022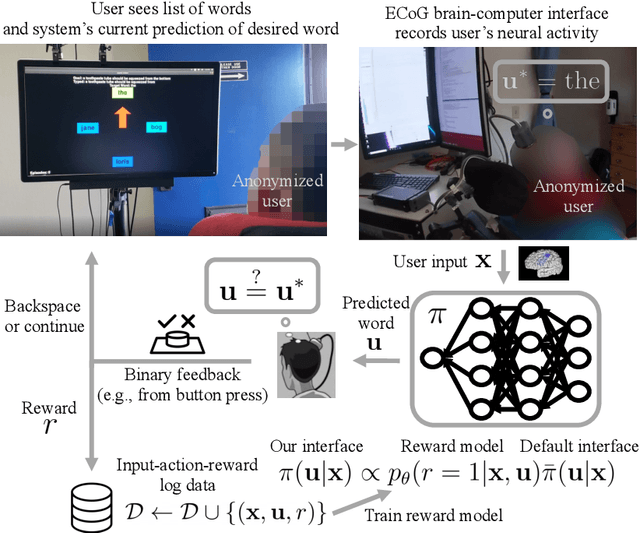
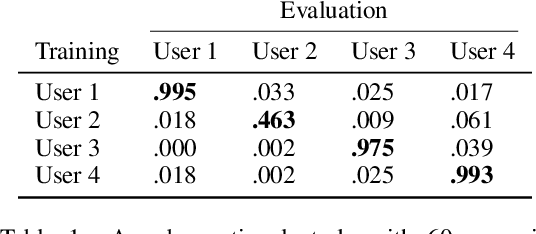
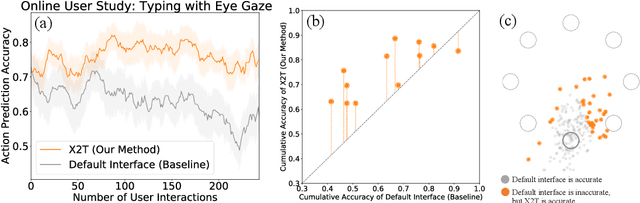

We aim to help users communicate their intent to machines using flexible, adaptive interfaces that translate arbitrary user input into desired actions. In this work, we focus on assistive typing applications in which a user cannot operate a keyboard, but can instead supply other inputs, such as webcam images that capture eye gaze or neural activity measured by a brain implant. Standard methods train a model on a fixed dataset of user inputs, then deploy a static interface that does not learn from its mistakes; in part, because extracting an error signal from user behavior can be challenging. We investigate a simple idea that would enable such interfaces to improve over time, with minimal additional effort from the user: online learning from user feedback on the accuracy of the interface's actions. In the typing domain, we leverage backspaces as feedback that the interface did not perform the desired action. We propose an algorithm called x-to-text (X2T) that trains a predictive model of this feedback signal, and uses this model to fine-tune any existing, default interface for translating user input into actions that select words or characters. We evaluate X2T through a small-scale online user study with 12 participants who type sentences by gazing at their desired words, a large-scale observational study on handwriting samples from 60 users, and a pilot study with one participant using an electrocorticography-based brain-computer interface. The results show that X2T learns to outperform a non-adaptive default interface, stimulates user co-adaptation to the interface, personalizes the interface to individual users, and can leverage offline data collected from the default interface to improve its initial performance and accelerate online learning.
ASHA: Assistive Teleoperation via Human-in-the-Loop Reinforcement Learning
Feb 05, 2022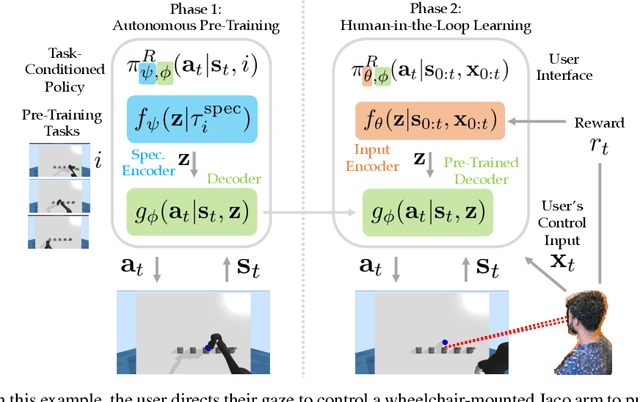
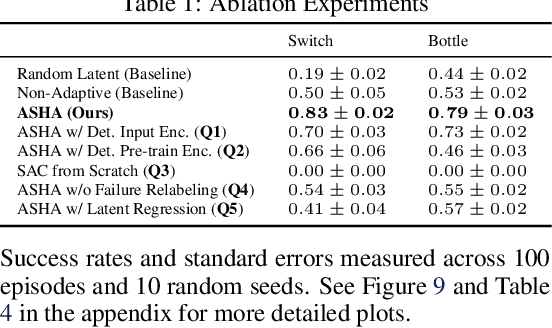
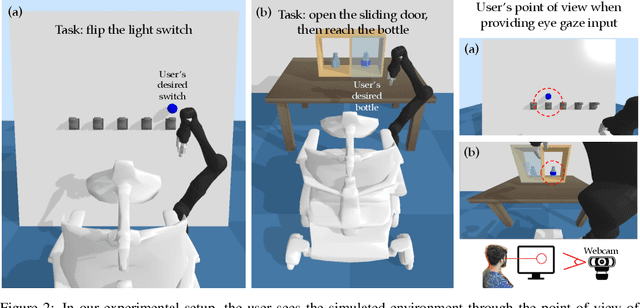
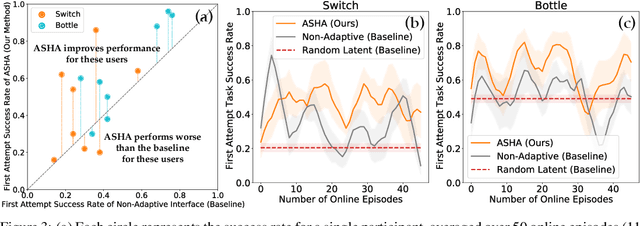
Building assistive interfaces for controlling robots through arbitrary, high-dimensional, noisy inputs (e.g., webcam images of eye gaze) can be challenging, especially when it involves inferring the user's desired action in the absence of a natural 'default' interface. Reinforcement learning from online user feedback on the system's performance presents a natural solution to this problem, and enables the interface to adapt to individual users. However, this approach tends to require a large amount of human-in-the-loop training data, especially when feedback is sparse. We propose a hierarchical solution that learns efficiently from sparse user feedback: we use offline pre-training to acquire a latent embedding space of useful, high-level robot behaviors, which, in turn, enables the system to focus on using online user feedback to learn a mapping from user inputs to desired high-level behaviors. The key insight is that access to a pre-trained policy enables the system to learn more from sparse rewards than a na\"ive RL algorithm: using the pre-trained policy, the system can make use of successful task executions to relabel, in hindsight, what the user actually meant to do during unsuccessful executions. We evaluate our method primarily through a user study with 12 participants who perform tasks in three simulated robotic manipulation domains using a webcam and their eye gaze: flipping light switches, opening a shelf door to reach objects inside, and rotating a valve. The results show that our method successfully learns to map 128-dimensional gaze features to 7-dimensional joint torques from sparse rewards in under 10 minutes of online training, and seamlessly helps users who employ different gaze strategies, while adapting to distributional shift in webcam inputs, tasks, and environments.
Pragmatic Image Compression for Human-in-the-Loop Decision-Making
Jul 07, 2021

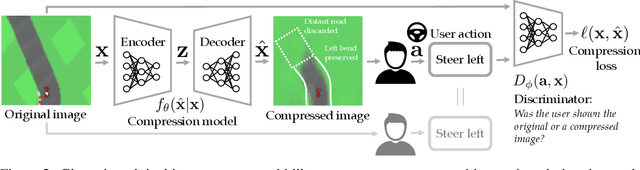
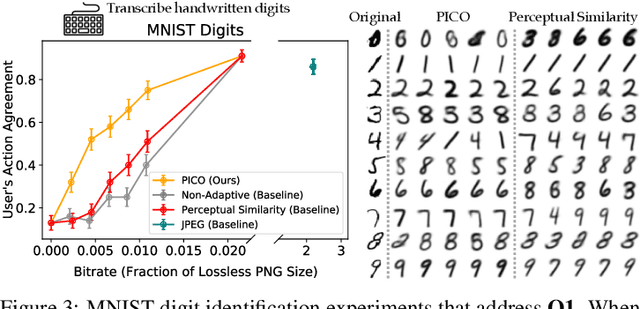
Standard lossy image compression algorithms aim to preserve an image's appearance, while minimizing the number of bits needed to transmit it. However, the amount of information actually needed by a user for downstream tasks -- e.g., deciding which product to click on in a shopping website -- is likely much lower. To achieve this lower bitrate, we would ideally only transmit the visual features that drive user behavior, while discarding details irrelevant to the user's decisions. We approach this problem by training a compression model through human-in-the-loop learning as the user performs tasks with the compressed images. The key insight is to train the model to produce a compressed image that induces the user to take the same action that they would have taken had they seen the original image. To approximate the loss function for this model, we train a discriminator that tries to distinguish whether a user's action was taken in response to the compressed image or the original. We evaluate our method through experiments with human participants on four tasks: reading handwritten digits, verifying photos of faces, browsing an online shopping catalogue, and playing a car racing video game. The results show that our method learns to match the user's actions with and without compression at lower bitrates than baseline methods, and adapts the compression model to the user's behavior: it preserves the digit number and randomizes handwriting style in the digit reading task, preserves hats and eyeglasses while randomizing faces in the photo verification task, preserves the perceived price of an item while randomizing its color and background in the online shopping task, and preserves upcoming bends in the road in the car racing game.
Assisted Perception: Optimizing Observations to Communicate State
Aug 06, 2020



We aim to help users estimate the state of the world in tasks like robotic teleoperation and navigation with visual impairments, where users may have systematic biases that lead to suboptimal behavior: they might struggle to process observations from multiple sensors simultaneously, receive delayed observations, or overestimate distances to obstacles. While we cannot directly change the user's internal beliefs or their internal state estimation process, our insight is that we can still assist them by modifying the user's observations. Instead of showing the user their true observations, we synthesize new observations that lead to more accurate internal state estimates when processed by the user. We refer to this method as assistive state estimation (ASE): an automated assistant uses the true observations to infer the state of the world, then generates a modified observation for the user to consume (e.g., through an augmented reality interface), and optimizes the modification to induce the user's new beliefs to match the assistant's current beliefs. We evaluate ASE in a user study with 12 participants who each perform four tasks: two tasks with known user biases -- bandwidth-limited image classification and a driving video game with observation delay -- and two with unknown biases that our method has to learn -- guided 2D navigation and a lunar lander teleoperation video game. A different assistance strategy emerges in each domain, such as quickly revealing informative pixels to speed up image classification, using a dynamics model to undo observation delay in driving, identifying nearby landmarks for navigation, and exaggerating a visual indicator of tilt in the lander game. The results show that ASE substantially improves the task performance of users with bandwidth constraints, observation delay, and other unknown biases.
Learning Human Objectives by Evaluating Hypothetical Behavior
Dec 05, 2019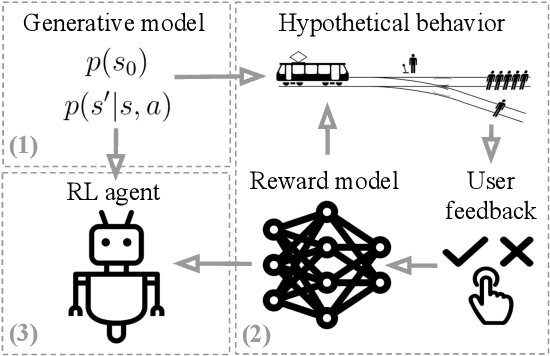
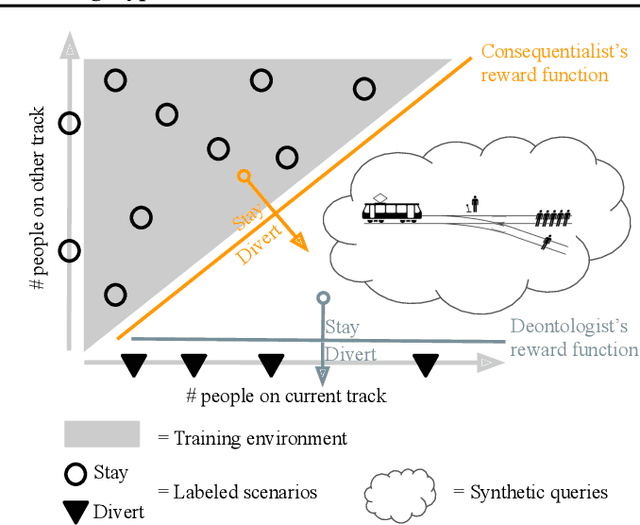
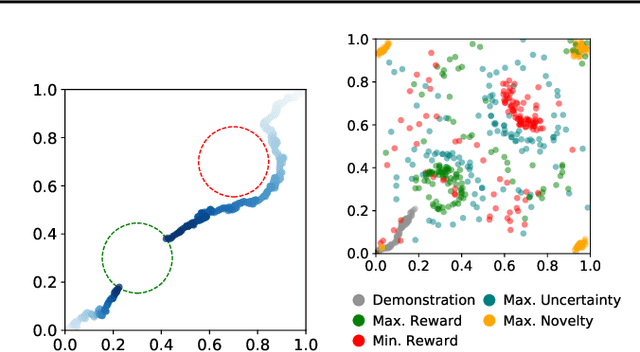
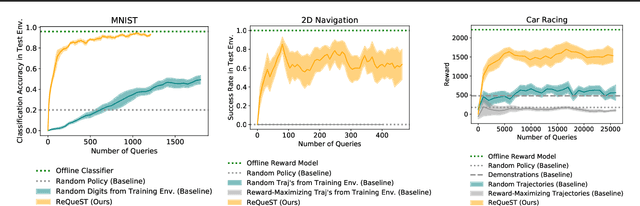
We seek to align agent behavior with a user's objectives in a reinforcement learning setting with unknown dynamics, an unknown reward function, and unknown unsafe states. The user knows the rewards and unsafe states, but querying the user is expensive. To address this challenge, we propose an algorithm that safely and interactively learns a model of the user's reward function. We start with a generative model of initial states and a forward dynamics model trained on off-policy data. Our method uses these models to synthesize hypothetical behaviors, asks the user to label the behaviors with rewards, and trains a neural network to predict the rewards. The key idea is to actively synthesize the hypothetical behaviors from scratch by maximizing tractable proxies for the value of information, without interacting with the environment. We call this method reward query synthesis via trajectory optimization (ReQueST). We evaluate ReQueST with simulated users on a state-based 2D navigation task and the image-based Car Racing video game. The results show that ReQueST significantly outperforms prior methods in learning reward models that transfer to new environments with different initial state distributions. Moreover, ReQueST safely trains the reward model to detect unsafe states, and corrects reward hacking before deploying the agent.
Scaled Autonomy: Enabling Human Operators to Control Robot Fleets
Sep 22, 2019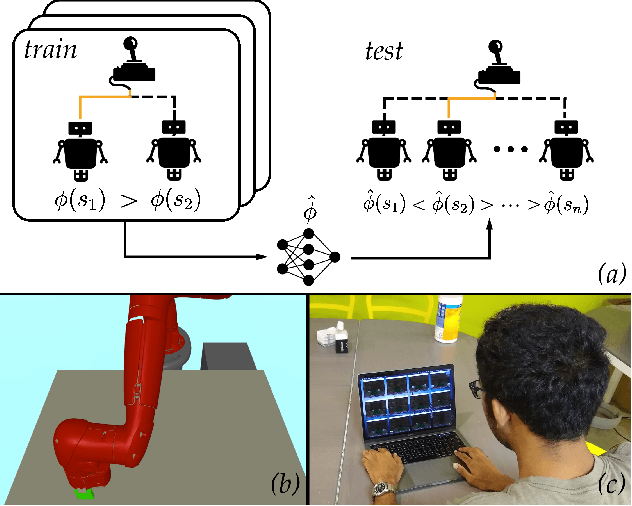
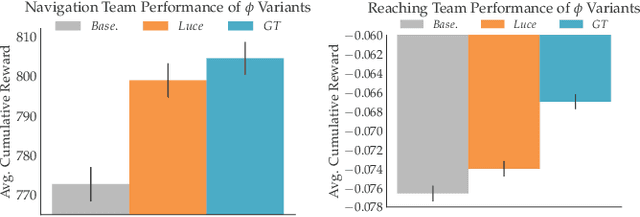
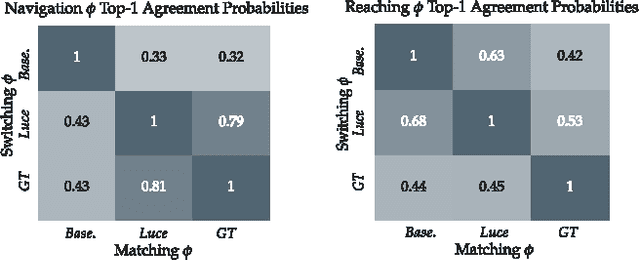
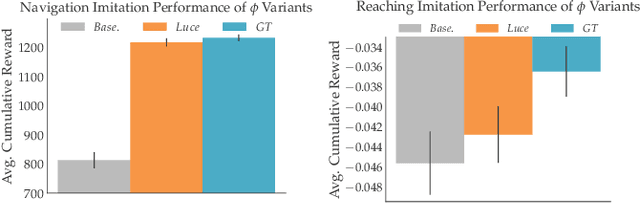
Autonomous robots often encounter challenging situations where their control policies fail and an expert human operator must briefly intervene, e.g., through teleoperation. In settings where multiple robots act in separate environments, a single human operator can manage a fleet of robots by identifying and teleoperating one robot at any given time. The key challenge is that users have limited attention: as the number of robots increases, users lose the ability to decide which robot requires teleoperation the most. Our goal is to automate this decision, thereby enabling users to supervise more robots than their attention would normally allow for. Our insight is that we can model the user's choice of which robot to control as an approximately optimal decision that maximizes the user's utility function. We learn a model of the user's preferences from observations of the user's choices in easy settings with a few robots, and use it in challenging settings with more robots to automatically identify which robot the user would most likely choose to control, if they were able to evaluate the states of all robots at all times. We run simulation experiments and a user study with twelve participants that show our method can be used to assist users in performing a navigation task and manipulator reaching task.
SQIL: Imitation Learning via Regularized Behavioral Cloning
Jun 14, 2019
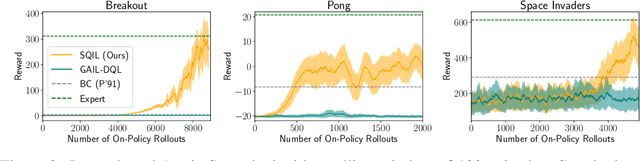
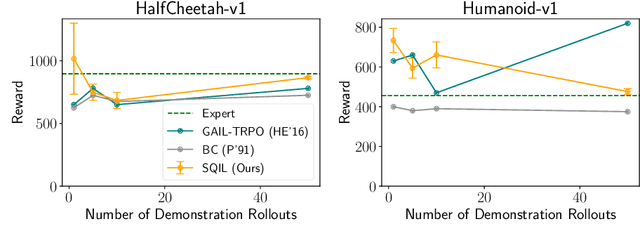

Learning to imitate expert behavior given action demonstrations containing high-dimensional, continuous observations and unknown dynamics is a difficult problem in robotic control. Simple approaches based on behavioral cloning (BC) suffer from state distribution shift, while more complex methods that generalize to out-of-distribution states can be difficult to use, since they typically involve adversarial optimization. We propose an alternative that combines the simplicity of BC with the robustness of adversarial imitation learning. The key insight is that under the maximum entropy model of expert behavior, BC corresponds to fitting a soft Q function that maximizes the likelihood of observed actions. This perspective suggests a way to regularize BC so that it generalizes to out-of-distribution states: combine the standard maximum-likelihood objective with a penalty on the soft Bellman error of the soft Q function. We show that this penalty term gives the agent an incentive to take actions that lead it back to demonstrated states when it encounters new states. Experiments show that our method outperforms BC and GAIL on a variety of image-based and low-dimensional environments in Box2D, Atari, and MuJoCo.
Where Do You Think You're Going?: Inferring Beliefs about Dynamics from Behavior
Oct 20, 2018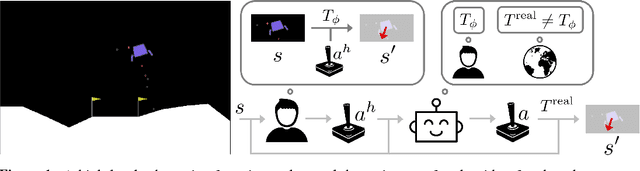

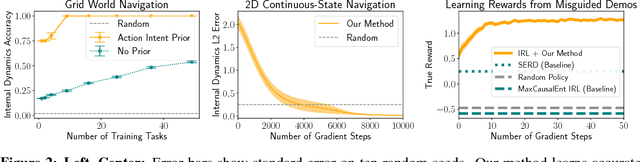
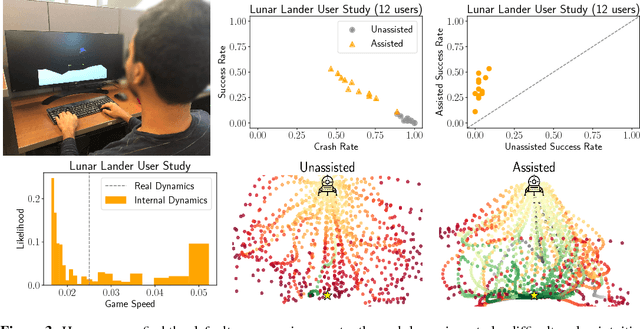
Inferring intent from observed behavior has been studied extensively within the frameworks of Bayesian inverse planning and inverse reinforcement learning. These methods infer a goal or reward function that best explains the actions of the observed agent, typically a human demonstrator. Another agent can use this inferred intent to predict, imitate, or assist the human user. However, a central assumption in inverse reinforcement learning is that the demonstrator is close to optimal. While models of suboptimal behavior exist, they typically assume that suboptimal actions are the result of some type of random noise or a known cognitive bias, like temporal inconsistency. In this paper, we take an alternative approach, and model suboptimal behavior as the result of internal model misspecification: the reason that user actions might deviate from near-optimal actions is that the user has an incorrect set of beliefs about the rules -- the dynamics -- governing how actions affect the environment. Our insight is that while demonstrated actions may be suboptimal in the real world, they may actually be near-optimal with respect to the user's internal model of the dynamics. By estimating these internal beliefs from observed behavior, we arrive at a new method for inferring intent. We demonstrate in simulation and in a user study with 12 participants that this approach enables us to more accurately model human intent, and can be used in a variety of applications, including offering assistance in a shared autonomy framework and inferring human preferences.