 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Closing the AI generalization gap by adjusting for dermatology condition distribution differences across clinical settings
Feb 23, 2024Recently, there has been great progress in the ability of artificial intelligence (AI) algorithms to classify dermatological conditions from clinical photographs. However, little is known about the robustness of these algorithms in real-world settings where several factors can lead to a loss of generalizability. Understanding and overcoming these limitations will permit the development of generalizable AI that can aid in the diagnosis of skin conditions across a variety of clinical settings. In this retrospective study, we demonstrate that differences in skin condition distribution, rather than in demographics or image capture mode are the main source of errors when an AI algorithm is evaluated on data from a previously unseen source. We demonstrate a series of steps to close this generalization gap, requiring progressively more information about the new source, ranging from the condition distribution to training data enriched for data less frequently seen during training. Our results also suggest comparable performance from end-to-end fine tuning versus fine tuning solely the classification layer on top of a frozen embedding model. Our approach can inform the adaptation of AI algorithms to new settings, based on the information and resources available.
Planning with Goal-Conditioned Policies
Nov 19, 2019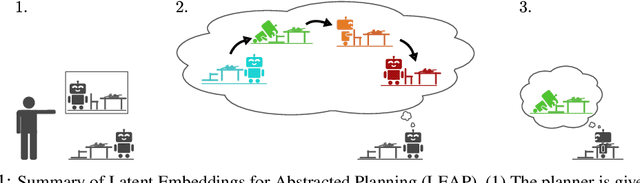

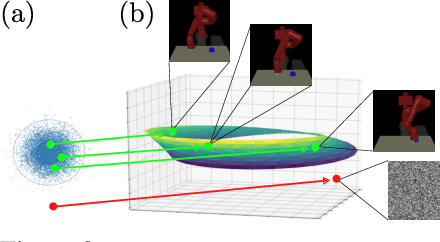
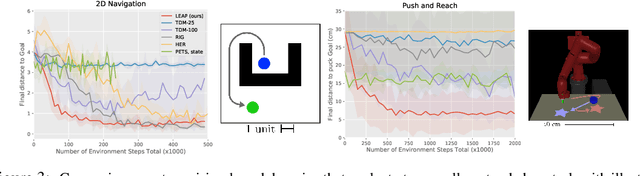
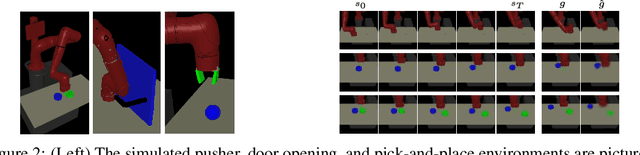
Planning methods can solve temporally extended sequential decision making problems by composing simple behaviors. However, planning requires suitable abstractions for the states and transitions, which typically need to be designed by hand. In contrast, model-free reinforcement learning (RL) can acquire behaviors from low-level inputs directly, but often struggles with temporally extended tasks. Can we utilize reinforcement learning to automatically form the abstractions needed for planning, thus obtaining the best of both approaches? We show that goal-conditioned policies learned with RL can be incorporated into planning, so that a planner can focus on which states to reach, rather than how those states are reached. However, with complex state observations such as images, not all inputs represent valid states. We therefore also propose using a latent variable model to compactly represent the set of valid states for the planner, so that the policies provide an abstraction of actions, and the latent variable model provides an abstraction of states. We compare our method with planning-based and model-free methods and find that our method significantly outperforms prior work when evaluated on image-based robot navigation and manipulation tasks that require non-greedy, multi-staged behavior.
Skew-Fit: State-Covering Self-Supervised Reinforcement Learning
Mar 08, 2019
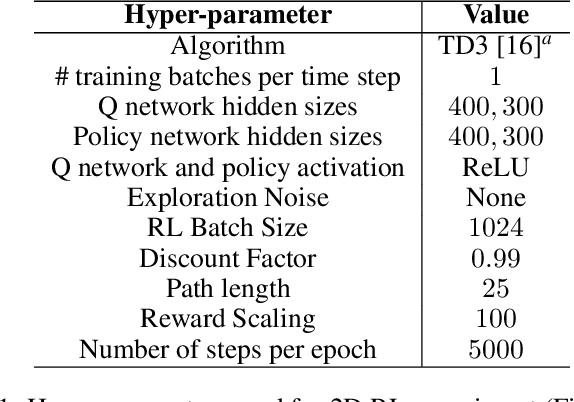
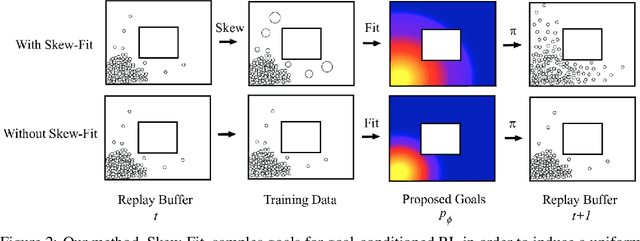
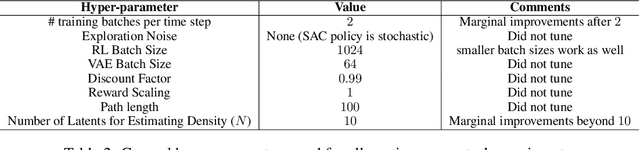
In standard reinforcement learning, each new skill requires a manually-designed reward function, which takes considerable manual effort and engineering. Self-supervised goal setting has the potential to automate this process, enabling an agent to propose its own goals and acquire skills that achieve these goals. However, such methods typically rely on manually-designed goal distributions, or heuristics to force the agent to explore a wide range of states. We propose a formal exploration objective for goal-reaching policies that maximizes state coverage. We show that this objective is equivalent to maximizing the entropy of the goal distribution together with goal reaching performance, where goals correspond to entire states. We present an algorithm called Skew-Fit for learning such a maximum-entropy goal distribution, and show that under certain regularity conditions, our method converges to a uniform distribution over the set of possible states, even when we do not know this set beforehand. Skew-Fit enables self-supervised agents to autonomously choose and practice diverse goals. Our experiments show that it can learn a variety of manipulation tasks from images, including opening a door with a real robot, entirely from scratch and without any manually-designed reward function.
Visual Reinforcement Learning with Imagined Goals
Dec 04, 2018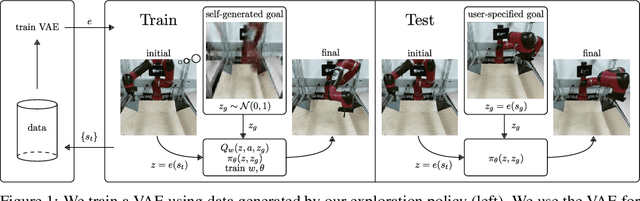
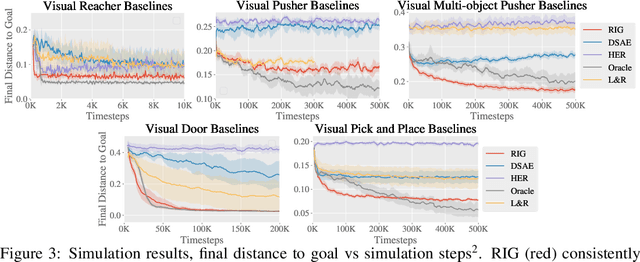
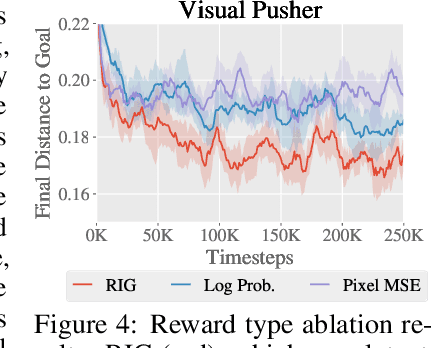
For an autonomous agent to fulfill a wide range of user-specified goals at test time, it must be able to learn broadly applicable and general-purpose skill repertoires. Furthermore, to provide the requisite level of generality, these skills must handle raw sensory input such as images. In this paper, we propose an algorithm that acquires such general-purpose skills by combining unsupervised representation learning and reinforcement learning of goal-conditioned policies. Since the particular goals that might be required at test-time are not known in advance, the agent performs a self-supervised "practice" phase where it imagines goals and attempts to achieve them. We learn a visual representation with three distinct purposes: sampling goals for self-supervised practice, providing a structured transformation of raw sensory inputs, and computing a reward signal for goal reaching. We also propose a retroactive goal relabeling scheme to further improve the sample-efficiency of our method. Our off-policy algorithm is efficient enough to learn policies that operate on raw image observations and goals for a real-world robotic system, and substantially outperforms prior techniques.