 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
Apr 28, 2021

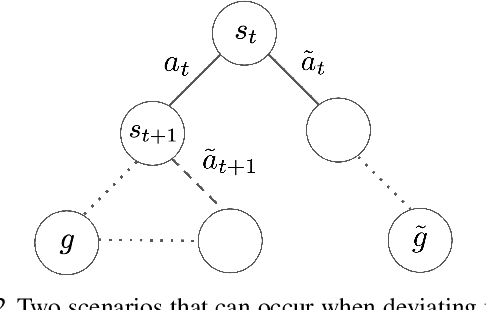
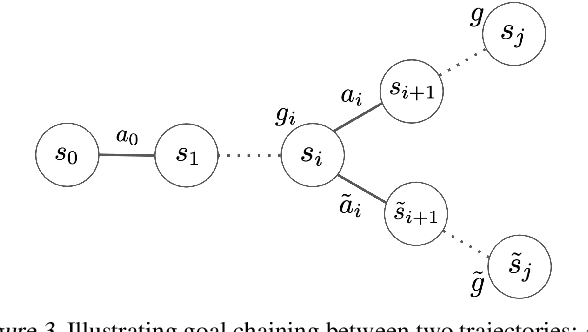
We consider the problem of learning useful robotic skills from previously collected offline data without access to manually specified rewards or additional online exploration, a setting that is becoming increasingly important for scaling robot learning by reusing past robotic data. In particular, we propose the objective of learning a functional understanding of the environment by learning to reach any goal state in a given dataset. We employ goal-conditioned Q-learning with hindsight relabeling and develop several techniques that enable training in a particularly challenging offline setting. We find that our method can operate on high-dimensional camera images and learn a variety of skills on real robots that generalize to previously unseen scenes and objects. We also show that our method can learn to reach long-horizon goals across multiple episodes, and learn rich representations that can help with downstream tasks through pre-training or auxiliary objectives. The videos of our experiments can be found at https://actionable-models.github.io
MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
Apr 27, 2021
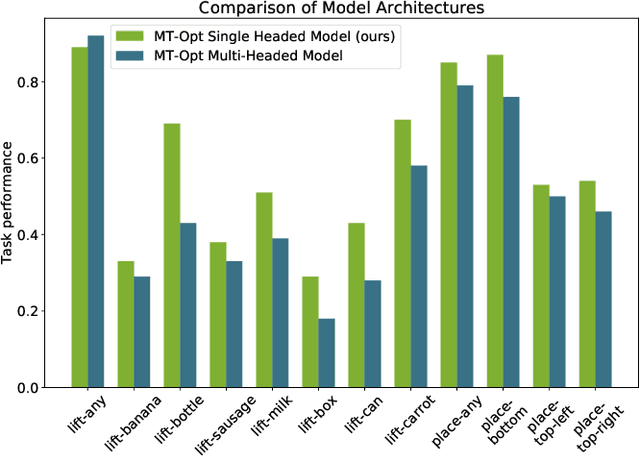
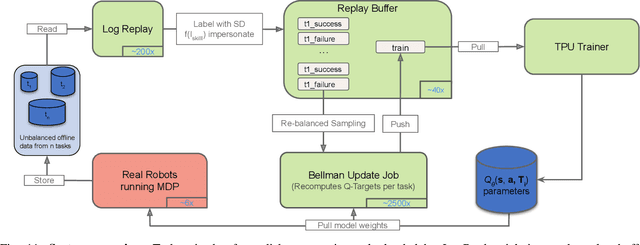
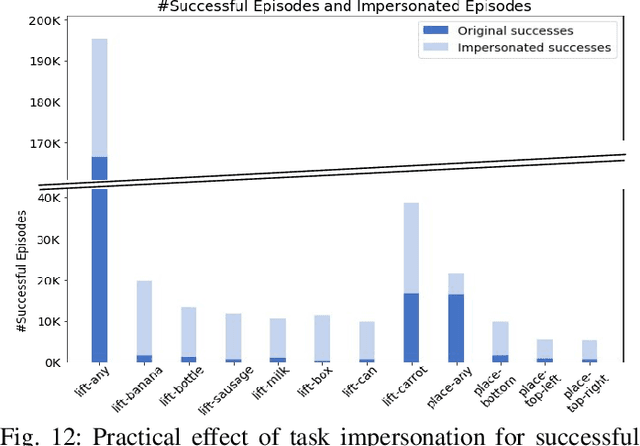
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos at https://karolhausman.github.io/mt-opt/
DisCo RL: Distribution-Conditioned Reinforcement Learning for General-Purpose Policies
Apr 23, 2021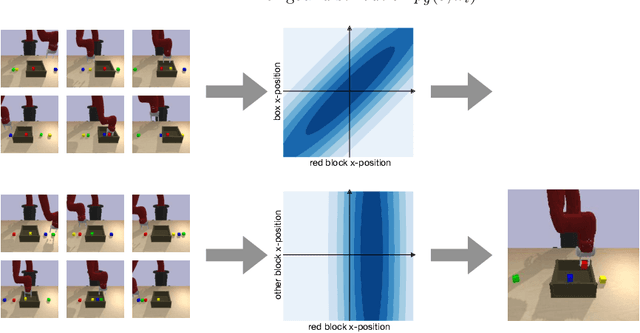
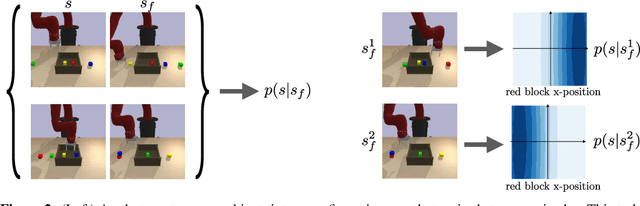
Can we use reinforcement learning to learn general-purpose policies that can perform a wide range of different tasks, resulting in flexible and reusable skills? Contextual policies provide this capability in principle, but the representation of the context determines the degree of generalization and expressivity. Categorical contexts preclude generalization to entirely new tasks. Goal-conditioned policies may enable some generalization, but cannot capture all tasks that might be desired. In this paper, we propose goal distributions as a general and broadly applicable task representation suitable for contextual policies. Goal distributions are general in the sense that they can represent any state-based reward function when equipped with an appropriate distribution class, while the particular choice of distribution class allows us to trade off expressivity and learnability. We develop an off-policy algorithm called distribution-conditioned reinforcement learning (DisCo RL) to efficiently learn these policies. We evaluate DisCo RL on a variety of robot manipulation tasks and find that it significantly outperforms prior methods on tasks that require generalization to new goal distributions.
Reset-Free Reinforcement Learning via Multi-Task Learning: Learning Dexterous Manipulation Behaviors without Human Intervention
Apr 22, 2021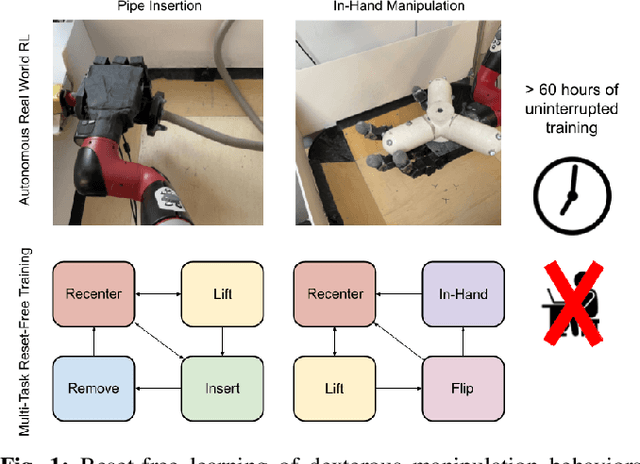



Reinforcement Learning (RL) algorithms can in principle acquire complex robotic skills by learning from large amounts of data in the real world, collected via trial and error. However, most RL algorithms use a carefully engineered setup in order to collect data, requiring human supervision and intervention to provide episodic resets. This is particularly evident in challenging robotics problems, such as dexterous manipulation. To make data collection scalable, such applications require reset-free algorithms that are able to learn autonomously, without explicit instrumentation or human intervention. Most prior work in this area handles single-task learning. However, we might also want robots that can perform large repertoires of skills. At first, this would appear to only make the problem harder. However, the key observation we make in this work is that an appropriately chosen multi-task RL setting actually alleviates the reset-free learning challenge, with minimal additional machinery required. In effect, solving a multi-task problem can directly solve the reset-free problem since different combinations of tasks can serve to perform resets for other tasks. By learning multiple tasks together and appropriately sequencing them, we can effectively learn all of the tasks together reset-free. This type of multi-task learning can effectively scale reset-free learning schemes to much more complex problems, as we demonstrate in our experiments. We propose a simple scheme for multi-task learning that tackles the reset-free learning problem, and show its effectiveness at learning to solve complex dexterous manipulation tasks in both hardware and simulation without any explicit resets. This work shows the ability to learn dexterous manipulation behaviors in the real world with RL without any human intervention.
Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
Apr 21, 2021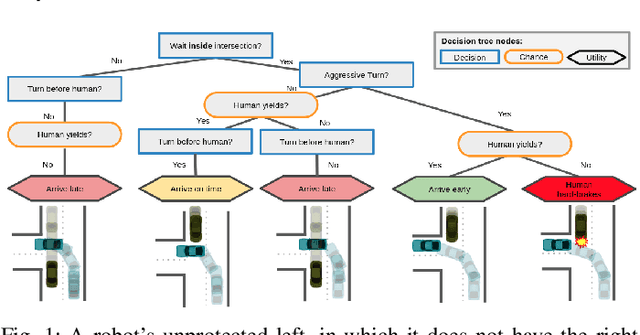
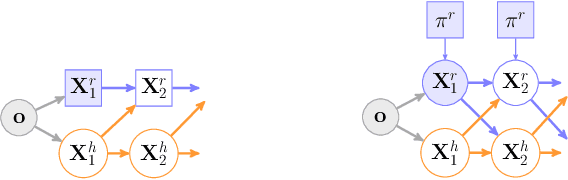
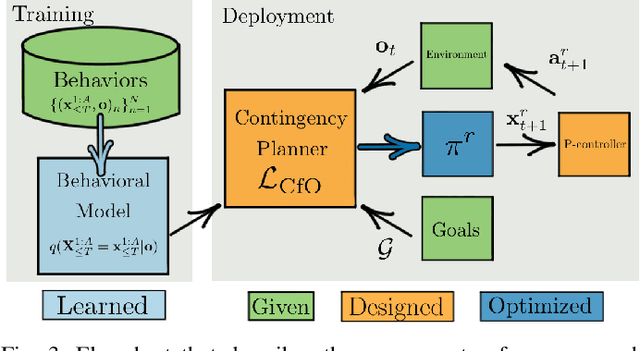
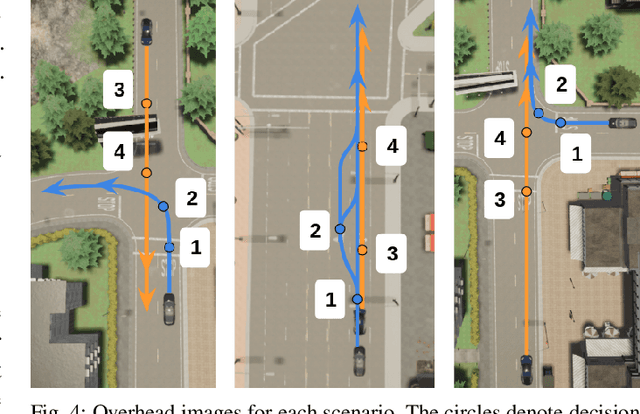
Humans have a remarkable ability to make decisions by accurately reasoning about future events, including the future behaviors and states of mind of other agents. Consider driving a car through a busy intersection: it is necessary to reason about the physics of the vehicle, the intentions of other drivers, and their beliefs about your own intentions. If you signal a turn, another driver might yield to you, or if you enter the passing lane, another driver might decelerate to give you room to merge in front. Competent drivers must plan how they can safely react to a variety of potential future behaviors of other agents before they make their next move. This requires contingency planning: explicitly planning a set of conditional actions that depend on the stochastic outcome of future events. In this work, we develop a general-purpose contingency planner that is learned end-to-end using high-dimensional scene observations and low-dimensional behavioral observations. We use a conditional autoregressive flow model to create a compact contingency planning space, and show how this model can tractably learn contingencies from behavioral observations. We developed a closed-loop control benchmark of realistic multi-agent scenarios in a driving simulator (CARLA), on which we compare our method to various noncontingent methods that reason about multi-agent future behavior, including several state-of-the-art deep learning-based planning approaches. We illustrate that these noncontingent planning methods fundamentally fail on this benchmark, and find that our deep contingency planning method achieves significantly superior performance. Code to run our benchmark and reproduce our results is available at https://sites.google.com/view/contingency-planning
Outcome-Driven Reinforcement Learning via Variational Inference
Apr 20, 2021
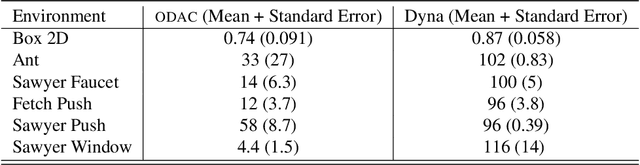
While reinforcement learning algorithms provide automated acquisition of optimal policies, practical application of such methods requires a number of design decisions, such as manually designing reward functions that not only define the task, but also provide sufficient shaping to accomplish it. In this paper, we discuss a new perspective on reinforcement learning, recasting it as the problem of inferring actions that achieve desired outcomes, rather than a problem of maximizing rewards. To solve the resulting outcome-directed inference problem, we establish a novel variational inference formulation that allows us to derive a well-shaped reward function which can be learned directly from environment interactions. From the corresponding variational objective, we also derive a new probabilistic Bellman backup operator reminiscent of the standard Bellman backup operator and use it to develop an off-policy algorithm to solve goal-directed tasks. We empirically demonstrate that this method eliminates the need to design reward functions and leads to effective goal-directed behaviors.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 14, 2021
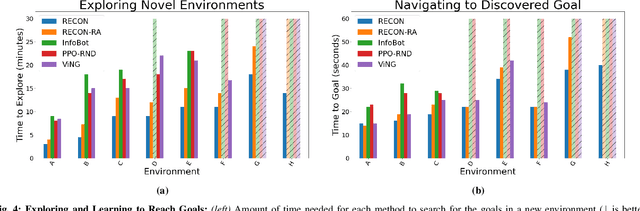
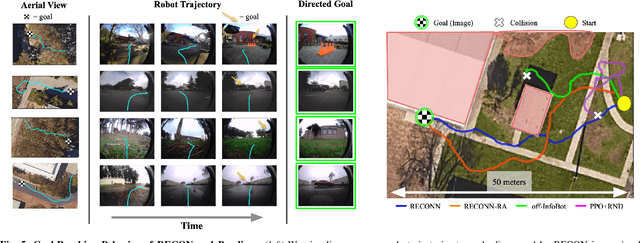
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
Apr 05, 2021
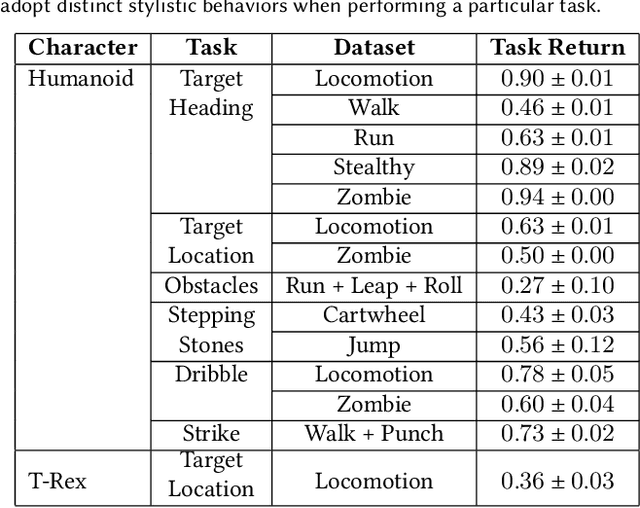
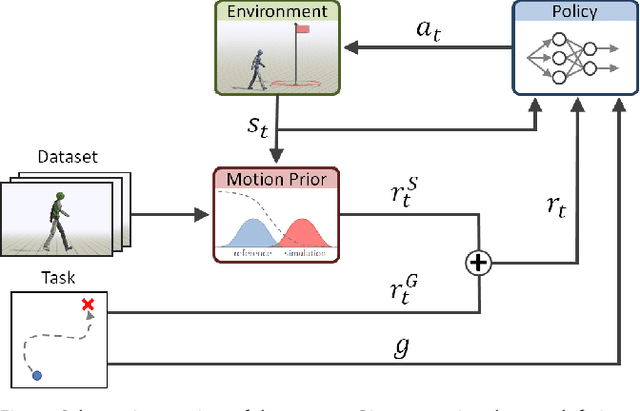
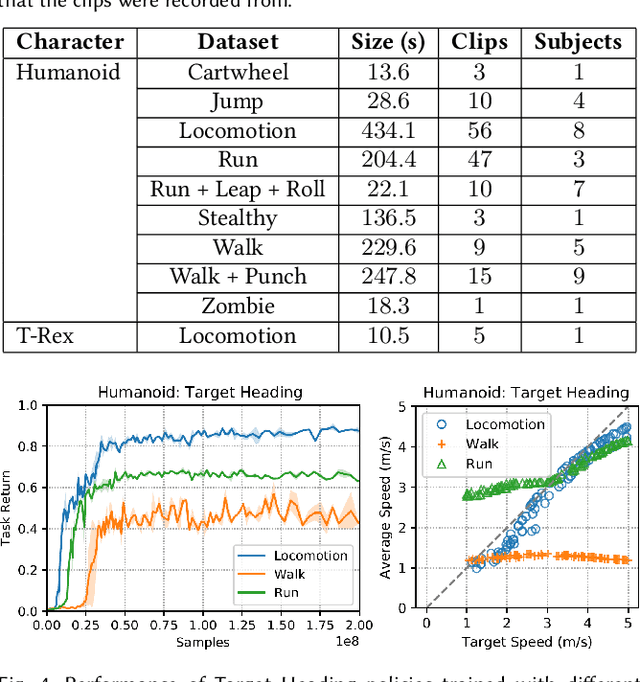
Synthesizing graceful and life-like behaviors for physically simulated characters has been a fundamental challenge in computer animation. Data-driven methods that leverage motion tracking are a prominent class of techniques for producing high fidelity motions for a wide range of behaviors. However, the effectiveness of these tracking-based methods often hinges on carefully designed objective functions, and when applied to large and diverse motion datasets, these methods require significant additional machinery to select the appropriate motion for the character to track in a given scenario. In this work, we propose to obviate the need to manually design imitation objectives and mechanisms for motion selection by utilizing a fully automated approach based on adversarial imitation learning. High-level task objectives that the character should perform can be specified by relatively simple reward functions, while the low-level style of the character's behaviors can be specified by a dataset of unstructured motion clips, without any explicit clip selection or sequencing. These motion clips are used to train an adversarial motion prior, which specifies style-rewards for training the character through reinforcement learning (RL). The adversarial RL procedure automatically selects which motion to perform, dynamically interpolating and generalizing from the dataset. Our system produces high-quality motions that are comparable to those achieved by state-of-the-art tracking-based techniques, while also being able to easily accommodate large datasets of unstructured motion clips. Composition of disparate skills emerges automatically from the motion prior, without requiring a high-level motion planner or other task-specific annotations of the motion clips. We demonstrate the effectiveness of our framework on a diverse cast of complex simulated characters and a challenging suite of motor control tasks.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021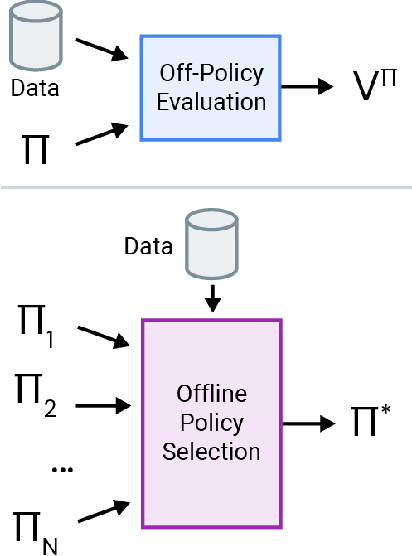
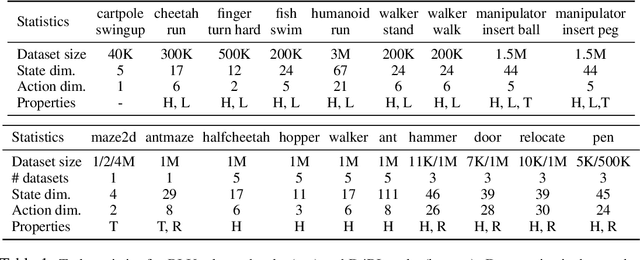
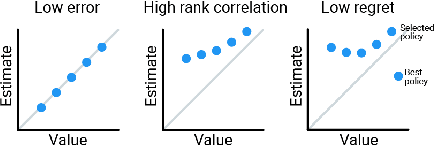
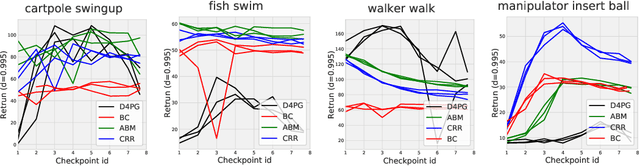
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots
Mar 26, 2021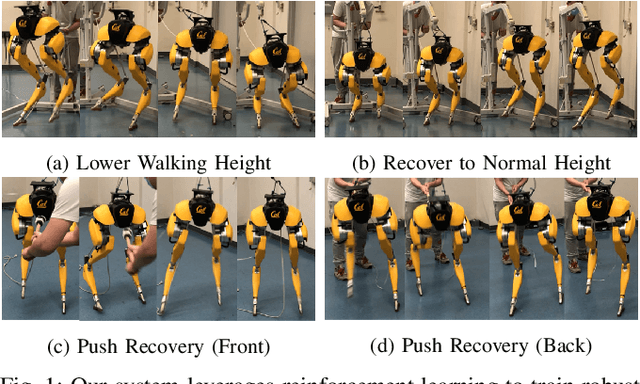
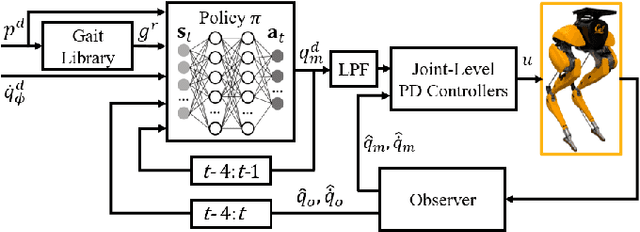
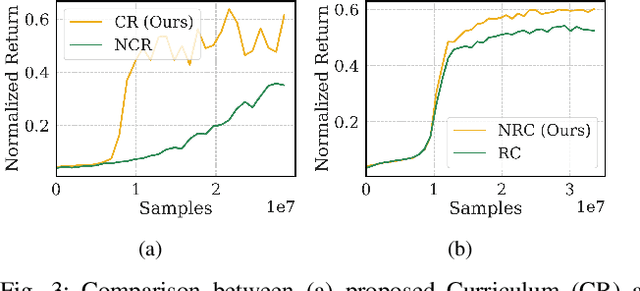
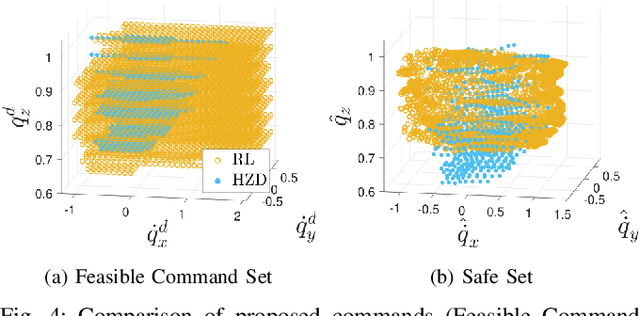
Developing robust walking controllers for bipedal robots is a challenging endeavor. Traditional model-based locomotion controllers require simplifying assumptions and careful modelling; any small errors can result in unstable control. To address these challenges for bipedal locomotion, we present a model-free reinforcement learning framework for training robust locomotion policies in simulation, which can then be transferred to a real bipedal Cassie robot. To facilitate sim-to-real transfer, domain randomization is used to encourage the policies to learn behaviors that are robust across variations in system dynamics. The learned policies enable Cassie to perform a set of diverse and dynamic behaviors, while also being more robust than traditional controllers and prior learning-based methods that use residual control. We demonstrate this on versatile walking behaviors such as tracking a target walking velocity, walking height, and turning yaw.