 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Explaining Datasets in Words: Statistical Models with Natural Language Parameters
Sep 13, 2024



To make sense of massive data, we often fit simplified models and then interpret the parameters; for example, we cluster the text embeddings and then interpret the mean parameters of each cluster. However, these parameters are often high-dimensional and hard to interpret. To make model parameters directly interpretable, we introduce a family of statistical models -- including clustering, time series, and classification models -- parameterized by natural language predicates. For example, a cluster of text about COVID could be parameterized by the predicate "discusses COVID". To learn these statistical models effectively, we develop a model-agnostic algorithm that optimizes continuous relaxations of predicate parameters with gradient descent and discretizes them by prompting language models (LMs). Finally, we apply our framework to a wide range of problems: taxonomizing user chat dialogues, characterizing how they evolve across time, finding categories where one language model is better than the other, clustering math problems based on subareas, and explaining visual features in memorable images. Our framework is highly versatile, applicable to both textual and visual domains, can be easily steered to focus on specific properties (e.g. subareas), and explains sophisticated concepts that classical methods (e.g. n-gram analysis) struggle to produce.
Learning Task Decomposition to Assist Humans in Competitive Programming
Jun 07, 2024



When using language models (LMs) to solve complex problems, humans might struggle to understand the LM-generated solutions and repair the flawed ones. To assist humans in repairing them, we propose to automatically decompose complex solutions into multiple simpler pieces that correspond to specific subtasks. We introduce a novel objective for learning task decomposition, termed assistive value (AssistV), which measures the feasibility and speed for humans to repair the decomposed solution. We collect a dataset of human repair experiences on different decomposed solutions. Utilizing the collected data as in-context examples, we then learn to critique, refine, and rank decomposed solutions to improve AssistV. We validate our method under competitive programming problems: under 177 hours of human study, our method enables non-experts to solve 33.3\% more problems, speeds them up by 3.3x, and empowers them to match unassisted experts.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Describing Differences in Image Sets with Natural Language
Dec 05, 2023



How do two sets of images differ? Discerning set-level differences is crucial for understanding model behaviors and analyzing datasets, yet manually sifting through thousands of images is impractical. To aid in this discovery process, we explore the task of automatically describing the differences between two $\textbf{sets}$ of images, which we term Set Difference Captioning. This task takes in image sets $D_A$ and $D_B$, and outputs a description that is more often true on $D_A$ than $D_B$. We outline a two-stage approach that first proposes candidate difference descriptions from image sets and then re-ranks the candidates by checking how well they can differentiate the two sets. We introduce VisDiff, which first captions the images and prompts a language model to propose candidate descriptions, then re-ranks these descriptions using CLIP. To evaluate VisDiff, we collect VisDiffBench, a dataset with 187 paired image sets with ground truth difference descriptions. We apply VisDiff to various domains, such as comparing datasets (e.g., ImageNet vs. ImageNetV2), comparing classification models (e.g., zero-shot CLIP vs. supervised ResNet), summarizing model failure modes (supervised ResNet), characterizing differences between generative models (e.g., StableDiffusionV1 and V2), and discovering what makes images memorable. Using VisDiff, we are able to find interesting and previously unknown differences in datasets and models, demonstrating its utility in revealing nuanced insights.
Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations
Jul 17, 2023Large language models (LLMs) are trained to imitate humans to explain human decisions. However, do LLMs explain themselves? Can they help humans build mental models of how LLMs process different inputs? To answer these questions, we propose to evaluate $\textbf{counterfactual simulatability}$ of natural language explanations: whether an explanation can enable humans to precisely infer the model's outputs on diverse counterfactuals of the explained input. For example, if a model answers "yes" to the input question "Can eagles fly?" with the explanation "all birds can fly", then humans would infer from the explanation that it would also answer "yes" to the counterfactual input "Can penguins fly?". If the explanation is precise, then the model's answer should match humans' expectations. We implemented two metrics based on counterfactual simulatability: precision and generality. We generated diverse counterfactuals automatically using LLMs. We then used these metrics to evaluate state-of-the-art LLMs (e.g., GPT-4) on two tasks: multi-hop factual reasoning and reward modeling. We found that LLM's explanations have low precision and that precision does not correlate with plausibility. Therefore, naively optimizing human approvals (e.g., RLHF) may not be a sufficient solution.
Goal-Driven Explainable Clustering via Language Descriptions
May 23, 2023



Unsupervised clustering is widely used to explore large corpora, but existing formulations neither consider the users' goals nor explain clusters' meanings. We propose a new task formulation, "Goal-Driven Clustering with Explanations" (GoalEx), which represents both the goal and the explanations as free-form language descriptions. For example, to categorize the errors made by a summarization system, the input to GoalEx is a corpus of annotator-written comments for system-generated summaries and a goal description "cluster the comments based on why the annotators think the summary is imperfect.''; the outputs are text clusters each with an explanation ("this cluster mentions that the summary misses important context information."), which relates to the goal and precisely explain which comments should (not) belong to a cluster. To tackle GoalEx, we prompt a language model with "[corpus subset] + [goal] + Brainstorm a list of explanations each representing a cluster."; then we classify whether each sample belongs to a cluster based on its explanation; finally, we use integer linear programming to select a subset of candidate clusters to cover most samples while minimizing overlaps. We apply GoalEx hierarchically to produce trees of progressively finer-grained clusters, inducing taxonomies over debate arguments, customer complaints, and model errors. We release our data and implementation at https://github.com/ZihanWangKi/GoalEx.
Goal Driven Discovery of Distributional Differences via Language Descriptions
Feb 28, 2023



Mining large corpora can generate useful discoveries but is time-consuming for humans. We formulate a new task, D5, that automatically discovers differences between two large corpora in a goal-driven way. The task input is a problem comprising a research goal "$\textit{comparing the side effects of drug A and drug B}$" and a corpus pair (two large collections of patients' self-reported reactions after taking each drug). The output is a language description (discovery) of how these corpora differ (patients taking drug A "$\textit{mention feelings of paranoia}$" more often). We build a D5 system, and to quantitatively measure its performance, we 1) contribute a meta-dataset, OpenD5, aggregating 675 open-ended problems ranging across business, social sciences, humanities, machine learning, and health, and 2) propose a set of unified evaluation metrics: validity, relevance, novelty, and significance. With the dataset and the unified metrics, we confirm that language models can use the goals to propose more relevant, novel, and significant candidate discoveries. Finally, our system produces discoveries previously unknown to the authors on a wide range of applications in OpenD5, including temporal and demographic differences in discussion topics, political stances and stereotypes in speech, insights in commercial reviews, and error patterns in NLP models.
DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation
Nov 18, 2022



We introduce DS-1000, a code generation benchmark with a thousand data science problems spanning seven Python libraries, such as NumPy and Pandas. Compared to prior works, DS-1000 incorporates three core features. First, our problems reflect diverse, realistic, and practical use cases since we collected them from StackOverflow. Second, our automatic evaluation is highly specific (reliable) -- across all Codex-002-predicted solutions that our evaluation accept, only 1.8% of them are incorrect; we achieve this with multi-criteria metrics, checking both functional correctness by running test cases and surface-form constraints by restricting API usages or keywords. Finally, we proactively defend against memorization by slightly modifying our problems to be different from the original StackOverflow source; consequently, models cannot answer them correctly by memorizing the solutions from pre-training. The current best public system (Codex-002) achieves 43.3% accuracy, leaving ample room for improvement. We release our benchmark at https://ds1000-code-gen.github.io.
Learning by Distilling Context
Sep 30, 2022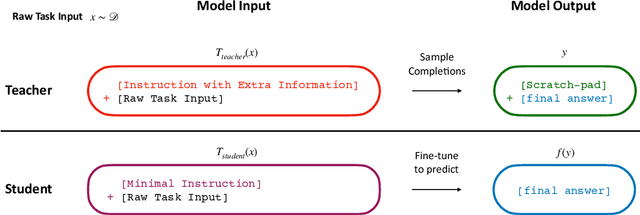
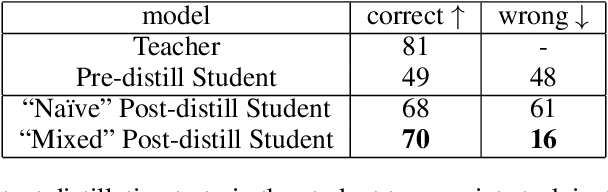
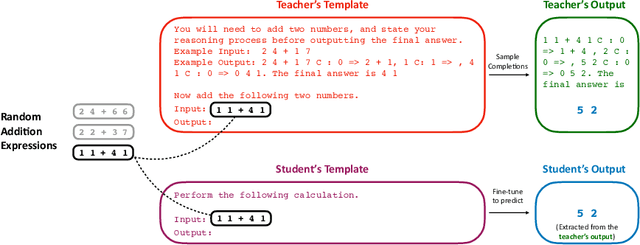
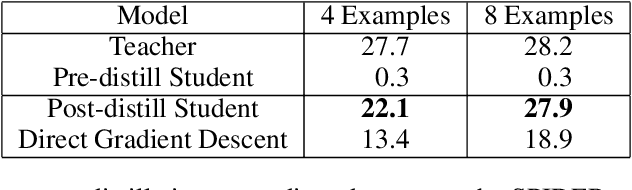
Language models significantly benefit from context tokens, such as prompts or scratchpads. They perform better when prompted with informative instructions, and they acquire new reasoning capabilities by generating a scratch-pad before predicting the final answers. However, they do not \textit{internalize} these performance gains, which disappear when the context tokens are gone. Our work proposes to apply context distillation so that a language model can improve itself by internalizing these gains. Concretely, given a synthetic unlabeled input for the target task, we condition the model on ``[instructions] + [task-input]'' to predict ``[scratch-pad] + [final answer]''; then we fine-tune the same model to predict its own ``[final answer]'' conditioned on the ``[task-input]'', without seeing the ``[instructions]'' or using the ``[scratch-pad]''. We show that context distillation is a general method to train language models, and it can effectively internalize 3 types of training signals. First, it can internalize abstract task instructions and explanations, so we can iteratively update the model parameters with new instructions and overwrite old ones. Second, it can internalize step-by-step reasoning for complex tasks (e.g., 8-digit addition), and such a newly acquired capability proves to be useful for other downstream tasks. Finally, it can internalize concrete training examples, and it outperforms directly learning with gradient descent by 9\% on the SPIDER Text-to-SQL dataset; furthermore, combining context distillation operations can internalize more training examples than the context window size allows.