 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Simulation Training for Chain-of-Thought Faithfulness
Feb 24, 2026Inspecting Chain-of-Thought reasoning is among the most common means of understanding why an LLM produced its output. But well-known problems with CoT faithfulness severely limit what insights can be gained from this practice. In this paper, we introduce a training method called Counterfactual Simulation Training (CST), which aims to improve CoT faithfulness by rewarding CoTs that enable a simulator to accurately predict a model's outputs over counterfactual inputs. We apply CST in two settings: (1) CoT monitoring with cue-based counterfactuals, to detect when models rely on spurious features, reward hack, or are sycophantic, and (2) counterfactual simulation over generic model-based counterfactuals, to encourage models to produce more faithful, generalizable reasoning in the CoT. Experiments with models up to 235B parameters show that CST can substantially improve monitor accuracy on cue-based counterfactuals (by 35 accuracy points) as well as simulatability over generic counterfactuals (by 2 points). We further show that: (1) CST outperforms prompting baselines, (2) rewriting unfaithful CoTs with an LLM is 5x more efficient than RL alone, (3) faithfulness improvements do not generalize to dissuading cues (as opposed to persuading cues), and (4) larger models do not show more faithful CoT out of the box, but they do benefit more from CST. These results suggest that CST can improve CoT faithfulness in general, with promising applications for CoT monitoring. Code for experiments in this paper is available at https://github.com/peterbhase/counterfactual-simulation-training
The Truthfulness Spectrum Hypothesis
Feb 23, 2026Large language models (LLMs) have been reported to linearly encode truthfulness, yet recent work questions this finding's generality. We reconcile these views with the truthfulness spectrum hypothesis: the representational space contains directions ranging from broadly domain-general to narrowly domain-specific. To test this hypothesis, we systematically evaluate probe generalization across five truth types (definitional, empirical, logical, fictional, and ethical), sycophantic and expectation-inverted lying, and existing honesty benchmarks. Linear probes generalize well across most domains but fail on sycophantic and expectation-inverted lying. Yet training on all domains jointly recovers strong performance, confirming that domain-general directions exist despite poor pairwise transfer. The geometry of probe directions explains these patterns: Mahalanobis cosine similarity between probes near-perfectly predicts cross-domain generalization (R^2=0.98). Concept-erasure methods further isolate truth directions that are (1) domain-general, (2) domain-specific, or (3) shared only across particular domain subsets. Causal interventions reveal that domain-specific directions steer more effectively than domain-general ones. Finally, post-training reshapes truth geometry, pushing sycophantic lying further from other truth types, suggesting a representational basis for chat models' sycophantic tendencies. Together, our results support the truthfulness spectrum hypothesis: truth directions of varying generality coexist in representational space, with post-training reshaping their geometry. Code for all experiments is provided in https://github.com/zfying/truth_spec.
Unsupervised Elicitation of Language Models
Jun 11, 2025



To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, \emph{without external supervision}. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation
May 01, 2025



LLMs trained on massive datasets may inadvertently acquire sensitive information such as personal details and potentially harmful content. This risk is further heightened in multimodal LLMs as they integrate information from multiple modalities (image and text). Adversaries can exploit this knowledge through multimodal prompts to extract sensitive details. Evaluating how effectively MLLMs can forget such information (targeted unlearning) necessitates the creation of high-quality, well-annotated image-text pairs. While prior work on unlearning has focused on text, multimodal unlearning remains underexplored. To address this gap, we first introduce a multimodal unlearning benchmark, UnLOK-VQA (Unlearning Outside Knowledge VQA), as well as an attack-and-defense framework to evaluate methods for deleting specific multimodal knowledge from MLLMs. We extend a visual question-answering dataset using an automated pipeline that generates varying-proximity samples for testing generalization and specificity, followed by manual filtering for maintaining high quality. We then evaluate six defense objectives against seven attacks (four whitebox, three blackbox), including a novel whitebox method leveraging interpretability of hidden states. Our results show multimodal attacks outperform text- or image-only ones, and that the most effective defense removes answer information from internal model states. Additionally, larger models exhibit greater post-editing robustness, suggesting that scale enhances safety. UnLOK-VQA provides a rigorous benchmark for advancing unlearning in MLLMs.
Teaching Models to Balance Resisting and Accepting Persuasion
Oct 18, 2024



Large language models (LLMs) are susceptible to persuasion, which can pose risks when models are faced with an adversarial interlocutor. We take a first step towards defending models against persuasion while also arguing that defense against adversarial (i.e. negative) persuasion is only half of the equation: models should also be able to accept beneficial (i.e. positive) persuasion to improve their answers. We show that optimizing models for only one side results in poor performance on the other. In order to balance positive and negative persuasion, we introduce Persuasion-Balanced Training (or PBT), which leverages multi-agent recursive dialogue trees to create data and trains models via preference optimization to accept persuasion when appropriate. PBT consistently improves resistance to misinformation and resilience to being challenged while also resulting in the best overall performance on holistic data containing both positive and negative persuasion. Crucially, we show that PBT models are better teammates in multi-agent debates. We find that without PBT, pairs of stronger and weaker models have unstable performance, with the order in which the models present their answers determining whether the team obtains the stronger or weaker model's performance. PBT leads to better and more stable results and less order dependence, with the stronger model consistently pulling the weaker one up.
System-1.x: Learning to Balance Fast and Slow Planning with Language Models
Jul 19, 2024



Language models can be used to solve long-horizon planning problems in two distinct modes: a fast 'System-1' mode, directly generating plans without any explicit search or backtracking, and a slow 'System-2' mode, planning step-by-step by explicitly searching over possible actions. While System-2 is typically more effective, it is also more computationally expensive, making it infeasible for long plans or large action spaces. Moreover, isolated System-1 or 2 ignores the user's end goals, failing to provide ways to control the model's behavior. To this end, we propose the System-1.x Planner, a controllable planning framework with LLMs that is capable of generating hybrid plans and balancing between the two planning modes based on the difficulty of the problem at hand. System-1.x consists of (i) a controller, (ii) a System-1 Planner, and (iii) a System-2 Planner. Based on a user-specified hybridization factor (x) governing the mixture between System-1 and 2, the controller decomposes a problem into sub-goals, and classifies them as easy or hard to be solved by either System-1 or 2, respectively. We fine-tune all three components on top of a single base LLM, requiring only search traces as supervision. Experiments with two diverse planning tasks -- Maze Navigation and Blocksworld -- show that our System-1.x Planner outperforms a System-1 Planner, a System-2 Planner trained to approximate A* search, and also a symbolic planner (A*). We demonstrate the following key properties of our planner: (1) controllability: increasing the hybridization factor (e.g., System-1.75 vs 1.5) performs more search, improving performance, (2) flexibility: by building a neuro-symbolic variant with a neural System-1 and a symbolic System-2, we can use existing symbolic methods, and (3) generalizability: by being able to learn from different search algorithms, our method is robust to the choice of search algorithm.
Fundamental Problems With Model Editing: How Should Rational Belief Revision Work in LLMs?
Jun 27, 2024



The model editing problem concerns how language models should learn new facts about the world over time. While empirical research on model editing has drawn widespread attention, the conceptual foundations of model editing remain shaky -- perhaps unsurprisingly, since model editing is essentially belief revision, a storied problem in philosophy that has eluded succinct solutions for decades. Model editing nonetheless demands a solution, since we need to be able to control the knowledge within language models. With this goal in mind, this paper critiques the standard formulation of the model editing problem and proposes a formal testbed for model editing research. We first describe 12 open problems with model editing, based on challenges with (1) defining the problem, (2) developing benchmarks, and (3) assuming LLMs have editable beliefs in the first place. Many of these challenges are extremely difficult to address, e.g. determining far-reaching consequences of edits, labeling probabilistic entailments between facts, and updating beliefs of agent simulators. Next, we introduce a semi-synthetic dataset for model editing based on Wikidata, where we can evaluate edits against labels given by an idealized Bayesian agent. This enables us to say exactly how belief revision in language models falls short of a desirable epistemic standard. We encourage further research exploring settings where such a gold standard can be compared against. Our code is publicly available at: https://github.com/peterbhase/LLM-belief-revision
Are language models rational? The case of coherence norms and belief revision
Jun 05, 2024Do norms of rationality apply to machine learning models, in particular language models? In this paper we investigate this question by focusing on a special subset of rational norms: coherence norms. We consider both logical coherence norms as well as coherence norms tied to the strength of belief. To make sense of the latter, we introduce the Minimal Assent Connection (MAC) and propose a new account of credence, which captures the strength of belief in language models. This proposal uniformly assigns strength of belief simply on the basis of model internal next token probabilities. We argue that rational norms tied to coherence do apply to some language models, but not to others. This issue is significant since rationality is closely tied to predicting and explaining behavior, and thus it is connected to considerations about AI safety and alignment, as well as understanding model behavior more generally.
LACIE: Listener-Aware Finetuning for Confidence Calibration in Large Language Models
May 31, 2024


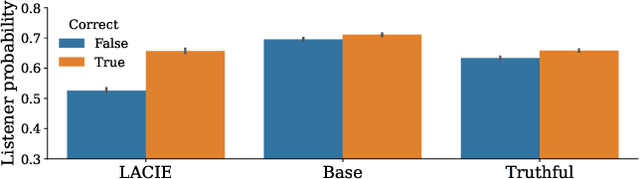
When answering questions, LLMs can convey not only an answer, but a level of confidence about the answer being correct. This includes explicit confidence markers (e.g. giving a numeric score) as well as implicit markers, like an authoritative tone or elaborating with additional knowledge. For LLMs to be trustworthy knowledge sources, the confidence they convey should match their actual expertise; however, most current models tend towards overconfidence. To calibrate both implicit and explicit confidence markers, we introduce a pragmatic, listener-aware finetuning method (LACIE) that models the listener, considering not only whether an answer is right, but whether it will be accepted by a listener. We cast calibration as preference optimization, creating data via a two-agent game, where a speaker model's outputs are judged by a simulated listener. We then finetune three LLMs (Mistral-7B, Llama3-8B, Llama3-70B) with LACIE, and show that the resulting models are better calibrated w.r.t. a simulated listener. Crucially, these trends transfer to human listeners, helping them correctly predict model correctness: we conduct a human evaluation where annotators accept or reject an LLM's answers, finding that training with LACIE results in 47% fewer incorrect answers being accepted while maintaining the same level of acceptance for correct answers. Furthermore, LACIE generalizes to another dataset, resulting in a large increase in truthfulness on TruthfulQA when trained on TriviaQA. Our analysis indicates that LACIE leads to a better confidence separation between correct and incorrect examples. Qualitatively, we find that a LACIE-trained model hedges more and implicitly signals certainty when it is correct by using an authoritative tone or including details. Finally, LACIE finetuning leads to an emergent increase in model abstention (e.g. saying "I don't know") for answers that are likely wrong.