 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNE-PADD: Leveraging Named Entity Knowledge for Robust Partial Audio Deepfake Detection via Attention Aggregation
Sep 04, 2025



Different from traditional sentence-level audio deepfake detection (ADD), partial audio deepfake detection (PADD) requires frame-level positioning of the location of fake speech. While some progress has been made in this area, leveraging semantic information from audio, especially named entities, remains an underexplored aspect. To this end, we propose NE-PADD, a novel method for Partial Audio Deepfake Detection (PADD) that leverages named entity knowledge through two parallel branches: Speech Name Entity Recognition (SpeechNER) and PADD. The approach incorporates two attention aggregation mechanisms: Attention Fusion (AF) for combining attention weights and Attention Transfer (AT) for guiding PADD with named entity semantics using an auxiliary loss. Built on the PartialSpoof-NER dataset, experiments show our method outperforms existing baselines, proving the effectiveness of integrating named entity knowledge in PADD. The code is available at https://github.com/AI-S2-Lab/NE-PADD.
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Aug 27, 2025



Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
UniTalker: Conversational Speech-Visual Synthesis
Aug 06, 2025Conversational Speech Synthesis (CSS) is a key task in the user-agent interaction area, aiming to generate more expressive and empathetic speech for users. However, it is well-known that "listening" and "eye contact" play crucial roles in conveying emotions during real-world interpersonal communication. Existing CSS research is limited to perceiving only text and speech within the dialogue context, which restricts its effectiveness. Moreover, speech-only responses further constrain the interactive experience. To address these limitations, we introduce a Conversational Speech-Visual Synthesis (CSVS) task as an extension of traditional CSS. By leveraging multimodal dialogue context, it provides users with coherent audiovisual responses. To this end, we develop a CSVS system named UniTalker, which is a unified model that seamlessly integrates multimodal perception and multimodal rendering capabilities. Specifically, it leverages a large-scale language model to comprehensively understand multimodal cues in the dialogue context, including speaker, text, speech, and the talking-face animations. After that, it employs multi-task sequence prediction to first infer the target utterance's emotion and then generate empathetic speech and natural talking-face animations. To ensure that the generated speech-visual content remains consistent in terms of emotion, content, and duration, we introduce three key optimizations: 1) Designing a specialized neural landmark codec to tokenize and reconstruct facial expression sequences. 2) Proposing a bimodal speech-visual hard alignment decoding strategy. 3) Applying emotion-guided rendering during the generation stage. Comprehensive objective and subjective experiments demonstrate that our model synthesizes more empathetic speech and provides users with more natural and emotionally consistent talking-face animations.
Scene-aware SAR ship detection guided by unsupervised sea-land segmentation
Jun 15, 2025DL based Synthetic Aperture Radar (SAR) ship detection has tremendous advantages in numerous areas. However, it still faces some problems, such as the lack of prior knowledge, which seriously affects detection accuracy. In order to solve this problem, we propose a scene-aware SAR ship detection method based on unsupervised sea-land segmentation. This method follows a classical two-stage framework and is enhanced by two models: the unsupervised land and sea segmentation module (ULSM) and the land attention suppression module (LASM). ULSM and LASM can adaptively guide the network to reduce attention on land according to the type of scenes (inshore scene and offshore scene) and add prior knowledge (sea land segmentation information) to the network, thereby reducing the network's attention to land directly and enhancing offshore detection performance relatively. This increases the accuracy of ship detection and enhances the interpretability of the model. Specifically, in consideration of the lack of land sea segmentation labels in existing deep learning-based SAR ship detection datasets, ULSM uses an unsupervised approach to classify the input data scene into inshore and offshore types and performs sea-land segmentation for inshore scenes. LASM uses the sea-land segmentation information as prior knowledge to reduce the network's attention to land. We conducted our experiments using the publicly available SSDD dataset, which demonstrated the effectiveness of our network.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025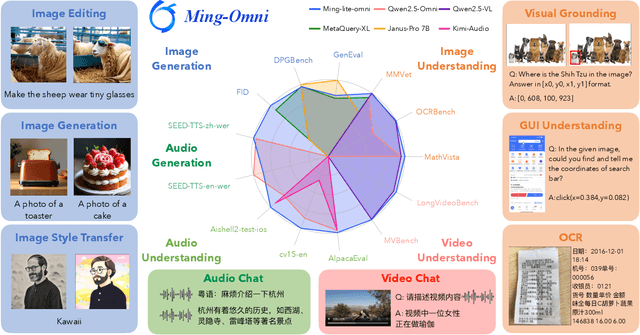
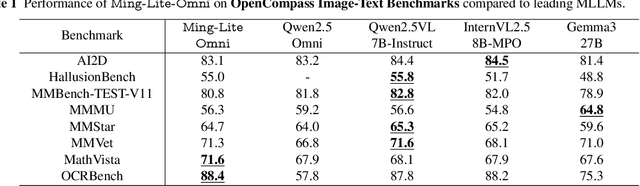
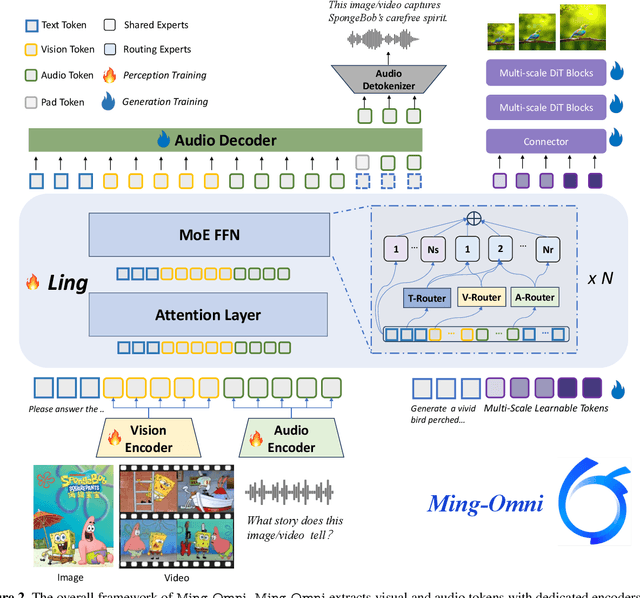
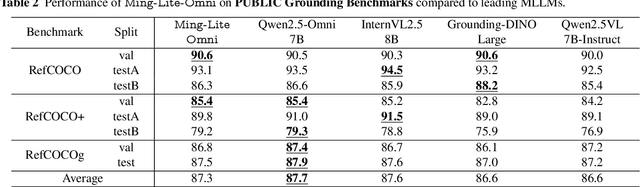
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Towards Emotionally Consistent Text-Based Speech Editing: Introducing EmoCorrector and The ECD-TSE Dataset
May 24, 2025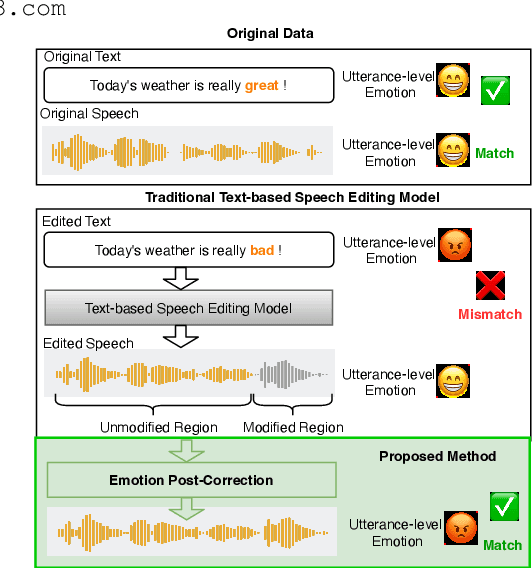


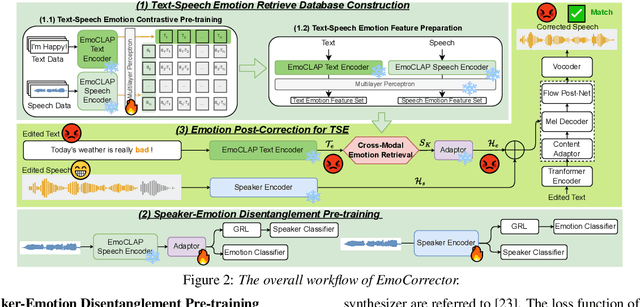
Text-based speech editing (TSE) modifies speech using only text, eliminating re-recording. However, existing TSE methods, mainly focus on the content accuracy and acoustic consistency of synthetic speech segments, and often overlook the emotional shifts or inconsistency issues introduced by text changes. To address this issue, we propose EmoCorrector, a novel post-correction scheme for TSE. EmoCorrector leverages Retrieval-Augmented Generation (RAG) by extracting the edited text's emotional features, retrieving speech samples with matching emotions, and synthesizing speech that aligns with the desired emotion while preserving the speaker's identity and quality. To support the training and evaluation of emotional consistency modeling in TSE, we pioneer the benchmarking Emotion Correction Dataset for TSE (ECD-TSE). The prominent aspect of ECD-TSE is its inclusion of $<$text, speech$>$ paired data featuring diverse text variations and a range of emotional expressions. Subjective and objective experiments and comprehensive analysis on ECD-TSE confirm that EmoCorrector significantly enhances the expression of intended emotion while addressing emotion inconsistency limitations in current TSE methods. Code and audio examples are available at https://github.com/AI-S2-Lab/EmoCorrector.
R1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress
Chain-Talker: Chain Understanding and Rendering for Empathetic Conversational Speech Synthesis
May 19, 2025Conversational Speech Synthesis (CSS) aims to align synthesized speech with the emotional and stylistic context of user-agent interactions to achieve empathy. Current generative CSS models face interpretability limitations due to insufficient emotional perception and redundant discrete speech coding. To address the above issues, we present Chain-Talker, a three-stage framework mimicking human cognition: Emotion Understanding derives context-aware emotion descriptors from dialogue history; Semantic Understanding generates compact semantic codes via serialized prediction; and Empathetic Rendering synthesizes expressive speech by integrating both components. To support emotion modeling, we develop CSS-EmCap, an LLM-driven automated pipeline for generating precise conversational speech emotion captions. Experiments on three benchmark datasets demonstrate that Chain-Talker produces more expressive and empathetic speech than existing methods, with CSS-EmCap contributing to reliable emotion modeling. The code and demos are available at: https://github.com/AI-S2-Lab/Chain-Talker.
Continuous Optimization for Feature Selection with Permutation-Invariant Embedding and Policy-Guided Search
May 16, 2025Feature selection removes redundant features to enhanc performance and computational efficiency in downstream tasks. Existing works often struggle to capture complex feature interactions and adapt to diverse scenarios. Recent advances in this domain have incorporated generative intelligence to address these drawbacks by uncovering intricate relationships between features. However, two key limitations remain: 1) embedding feature subsets in a continuous space is challenging due to permutation sensitivity, as changes in feature order can introduce biases and weaken the embedding learning process; 2) gradient-based search in the embedding space assumes convexity, which is rarely guaranteed, leading to reduced search effectiveness and suboptimal subsets. To address these limitations, we propose a new framework that can: 1) preserve feature subset knowledge in a continuous embedding space while ensuring permutation invariance; 2) effectively explore the embedding space without relying on strong convex assumptions. For the first objective, we develop an encoder-decoder paradigm to preserve feature selection knowledge into a continuous embedding space. This paradigm captures feature interactions through pairwise relationships within the subset, removing the influence of feature order on the embedding. Moreover, an inducing point mechanism is introduced to accelerate pairwise relationship computations. For the second objective, we employ a policy-based reinforcement learning (RL) approach to guide the exploration of the embedding space. The RL agent effectively navigates the space by balancing multiple objectives. By prioritizing high-potential regions adaptively and eliminating the reliance on convexity assumptions, the RL agent effectively reduces the risk of converging to local optima. Extensive experiments demonstrate the effectiveness, efficiency, robustness and explicitness of our model.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025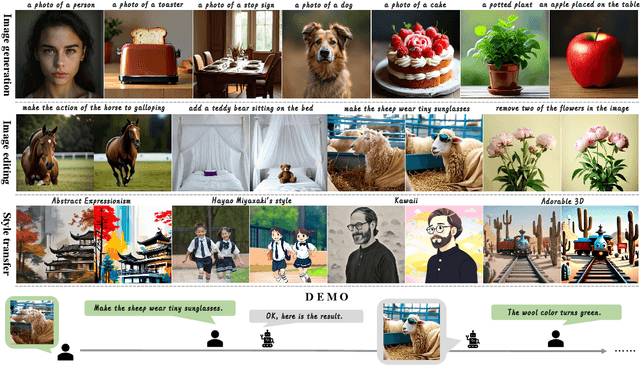

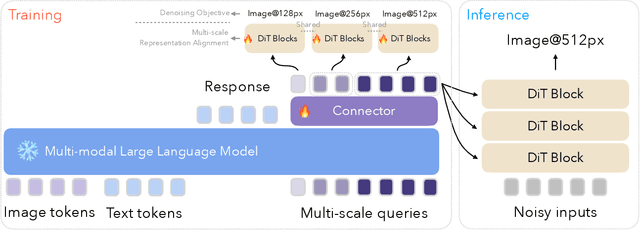
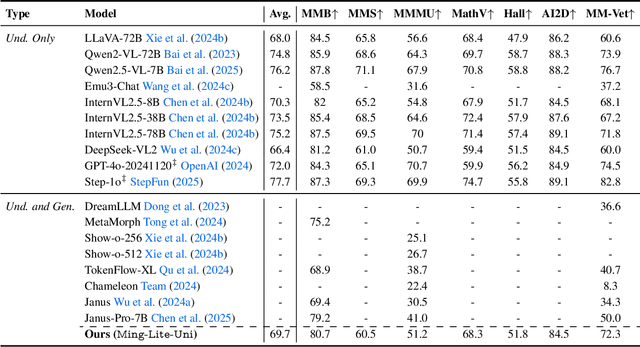
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.