 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Voice: Enabling Everyone to Speak 30 Languages via Zero-Shot Cross-Lingual Voice Cloning
May 07, 2026In this paper, we present X-Voice, a 0.4B multilingual zero-shot voice cloning model that clones arbitrary voices and enables everyone to speak 30 languages. X-Voice is trained on a 420K-hour multilingual corpus using the International Phonetic Alphabet (IPA) as a unified representation. To eliminate the reliance on prompt text without complex preprocessing like forced alignment, we design a two-stage training paradigm. In Stage 1, we establish X-Voice$_{\text{s1}}$ through standard conditional flow-matching training and use it to synthesize 10K hours of speaker-consistent segments as audio prompts. In Stage 2, we fine-tune on these audio pairs with prompt text masked to derive X-Voice$_{\text{s2}}$, which enables zero-shot voice cloning without requiring transcripts of audio prompts. Architecturally, we extend F5-TTS by implementing a dual-level injection of language identifiers and decoupling and scheduling of Classifier-Free Guidance to facilitate multilingual speech synthesis. Subjective and objective evaluation results demonstrate that X-Voice outperforms existing flow-matching based multilingual systems like LEMAS-TTS and achieves zero-shot cross-lingual cloning capabilities comparable to billion-scale models such as Qwen3-TTS. To facilitate research transparency and community advancement, we open-source all related resources.
Who is Speaking or Who is Depressed? A Controlled Study of Speaker Leakage in Speech-Based Depression Detection
Apr 15, 2026This study investigates whether speech-based depression detection models learn depression-related acoustic biomarkers or instead rely on speaker identity cues. Using the DAIC-WOZ dataset, we propose a data-splitting strategy that controls speaker overlap between training and test sets while keeping the training size constant, and evaluate three models of varying complexity. Results show that speaker overlap significantly boosts performance, whereas accuracy drops sharply on unseen speakers. Even with a Domain-Adversarial Neural Network, a substantial performance gap remains. These findings indicate that depression-related features extracted by current speech models are highly entangled with speaker identity. Conventional evaluation protocols may therefore overestimate generalization and clinical utility, highlighting the need for strictly speaker-independent evaluation.
ProSDD: Learning Prosodic Representations for Speech Deepfake Detection against Expressive and Emotional Attacks
Apr 14, 2026Speech deepfake detection (SDD) systems perform well on standard benchmarks datasets but often fail to generalize to expressive and emotional spoofing attacks. Many methods rely on spoof-heavy training data, learning dataset-specific artifacts rather than transferable cues of natural speech. In contrast, humans internalize variability in real speech and detect fakes as deviations from it. We introduce ProSDD, a two-stage framework that enriches model embeddings through supervised masked prediction of speaker-conditioned prosodic variation based on pitch, voice activity, and energy. Stage I learns prosodic variability from real speech, and Stage II jointly optimizes this objective with spoof classification. ProSDD consistently outperforms baselines under both ASVspoof 2019 and 2024 training, reducing ASVspoof 2024 EER from 25.43% to 16.14% (2019-trained) and from 39.62% to 7.38% (2024-trained), while achieving 50% relative reductions on EmoFake and EmoSpoof-TTS.
Neuron-Level Emotion Control in Speech-Generative Large Audio-Language Models
Mar 18, 2026Large audio-language models (LALMs) can produce expressive speech, yet reliable emotion control remains elusive: conversions often miss the target affect and may degrade linguistic fidelity through refusals, hallucinations, or paraphrase. We present, to our knowledge, the first neuron-level study of emotion control in speech-generative LALMs and demonstrate that compact emotion-sensitive neurons (ESNs) are causally actionable, enabling training-free emotion steering at inference time. ESNs are identified via success-filtered activation aggregation enforcing both emotion realization and content preservation. Across three LALMs (Qwen2.5-Omni-7B, MiniCPM-o 4.5, Kimi-Audio), ESN interventions yield emotion-specific gains that generalize to unseen speakers and are supported by automatic and human evaluation. Controllability depends on selector design, mask sparsity, filtering, and intervention strength. Our results establish a mechanistic framework for training-free emotion control in speech generation.
Universal Speech Content Factorization
Mar 09, 2026We propose Universal Speech Content Factorization (USCF), a simple and invertible linear method for extracting a low-rank speech representation in which speaker timbre is suppressed while phonetic content is preserved. USCF extends Speech Content Factorization, a closed-set voice conversion (VC) method, to an open-set setting by learning a universal speech-to-content mapping via least-squares optimization and deriving speaker-specific transformations from only a few seconds of target speech. We show through embedding analysis that USCF effectively removes speaker-dependent variation. As a zero-shot VC system, USCF achieves competitive intelligibility, naturalness, and speaker similarity compared to methods that require substantially more target-speaker data or additional neural training. Finally, we demonstrate that as a training-efficient timbre-disentangled speech feature, USCF features can serve as the acoustic representation for training timbre-prompted text-to-speech models. Speech samples and code are publicly available.
Discovering and Causally Validating Emotion-Sensitive Neurons in Large Audio-Language Models
Jan 06, 2026Emotion is a central dimension of spoken communication, yet, we still lack a mechanistic account of how modern large audio-language models (LALMs) encode it internally. We present the first neuron-level interpretability study of emotion-sensitive neurons (ESNs) in LALMs and provide causal evidence that such units exist in Qwen2.5-Omni, Kimi-Audio, and Audio Flamingo 3. Across these three widely used open-source models, we compare frequency-, entropy-, magnitude-, and contrast-based neuron selectors on multiple emotion recognition benchmarks. Using inference-time interventions, we reveal a consistent emotion-specific signature: ablating neurons selected for a given emotion disproportionately degrades recognition of that emotion while largely preserving other classes, whereas gain-based amplification steers predictions toward the target emotion. These effects arise with modest identification data and scale systematically with intervention strength. We further observe that ESNs exhibit non-uniform layer-wise clustering with partial cross-dataset transfer. Taken together, our results offer a causal, neuron-level account of emotion decisions in LALMs and highlight targeted neuron interventions as an actionable handle for controllable affective behaviors.
NE-PADD: Leveraging Named Entity Knowledge for Robust Partial Audio Deepfake Detection via Attention Aggregation
Sep 04, 2025



Different from traditional sentence-level audio deepfake detection (ADD), partial audio deepfake detection (PADD) requires frame-level positioning of the location of fake speech. While some progress has been made in this area, leveraging semantic information from audio, especially named entities, remains an underexplored aspect. To this end, we propose NE-PADD, a novel method for Partial Audio Deepfake Detection (PADD) that leverages named entity knowledge through two parallel branches: Speech Name Entity Recognition (SpeechNER) and PADD. The approach incorporates two attention aggregation mechanisms: Attention Fusion (AF) for combining attention weights and Attention Transfer (AT) for guiding PADD with named entity semantics using an auxiliary loss. Built on the PartialSpoof-NER dataset, experiments show our method outperforms existing baselines, proving the effectiveness of integrating named entity knowledge in PADD. The code is available at https://github.com/AI-S2-Lab/NE-PADD.
Can Emotion Fool Anti-spoofing?
May 29, 2025



Traditional anti-spoofing focuses on models and datasets built on synthetic speech with mostly neutral state, neglecting diverse emotional variations. As a result, their robustness against high-quality, emotionally expressive synthetic speech is uncertain. We address this by introducing EmoSpoof-TTS, a corpus of emotional text-to-speech samples. Our analysis shows existing anti-spoofing models struggle with emotional synthetic speech, exposing risks of emotion-targeted attacks. Even trained on emotional data, the models underperform due to limited focus on emotional aspect and show performance disparities across emotions. This highlights the need for emotion-focused anti-spoofing paradigm in both dataset and methodology. We propose GEM, a gated ensemble of emotion-specialized models with a speech emotion recognition gating network. GEM performs effectively across all emotions and neutral state, improving defenses against spoofing attacks. We release the EmoSpoof-TTS Dataset: https://emospoof-tts.github.io/Dataset/
EmotionRankCLAP: Bridging Natural Language Speaking Styles and Ordinal Speech Emotion via Rank-N-Contrast
May 29, 2025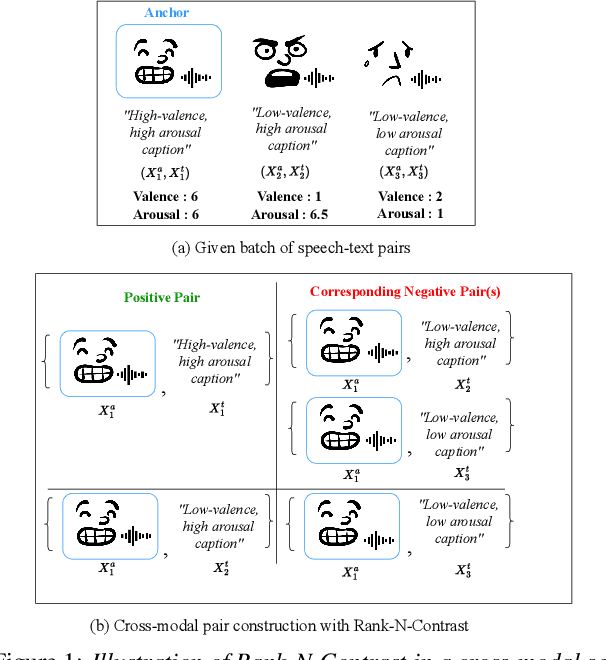


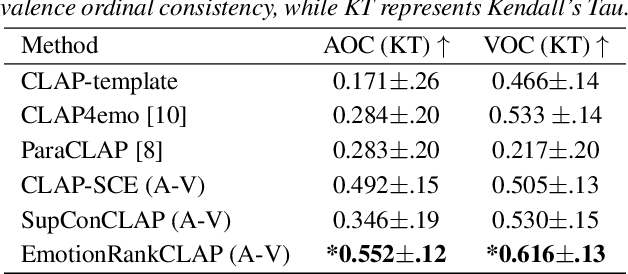
Current emotion-based contrastive language-audio pretraining (CLAP) methods typically learn by na\"ively aligning audio samples with corresponding text prompts. Consequently, this approach fails to capture the ordinal nature of emotions, hindering inter-emotion understanding and often resulting in a wide modality gap between the audio and text embeddings due to insufficient alignment. To handle these drawbacks, we introduce EmotionRankCLAP, a supervised contrastive learning approach that uses dimensional attributes of emotional speech and natural language prompts to jointly capture fine-grained emotion variations and improve cross-modal alignment. Our approach utilizes a Rank-N-Contrast objective to learn ordered relationships by contrasting samples based on their rankings in the valence-arousal space. EmotionRankCLAP outperforms existing emotion-CLAP methods in modeling emotion ordinality across modalities, measured via a cross-modal retrieval task.
Towards Emotionally Consistent Text-Based Speech Editing: Introducing EmoCorrector and The ECD-TSE Dataset
May 24, 2025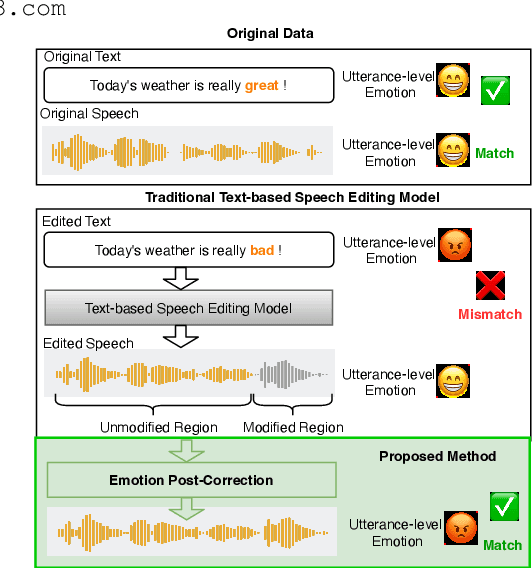


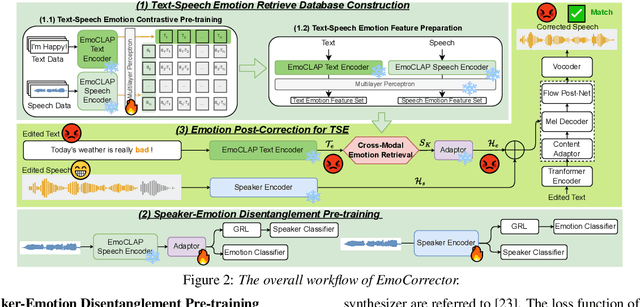
Text-based speech editing (TSE) modifies speech using only text, eliminating re-recording. However, existing TSE methods, mainly focus on the content accuracy and acoustic consistency of synthetic speech segments, and often overlook the emotional shifts or inconsistency issues introduced by text changes. To address this issue, we propose EmoCorrector, a novel post-correction scheme for TSE. EmoCorrector leverages Retrieval-Augmented Generation (RAG) by extracting the edited text's emotional features, retrieving speech samples with matching emotions, and synthesizing speech that aligns with the desired emotion while preserving the speaker's identity and quality. To support the training and evaluation of emotional consistency modeling in TSE, we pioneer the benchmarking Emotion Correction Dataset for TSE (ECD-TSE). The prominent aspect of ECD-TSE is its inclusion of $<$text, speech$>$ paired data featuring diverse text variations and a range of emotional expressions. Subjective and objective experiments and comprehensive analysis on ECD-TSE confirm that EmoCorrector significantly enhances the expression of intended emotion while addressing emotion inconsistency limitations in current TSE methods. Code and audio examples are available at https://github.com/AI-S2-Lab/EmoCorrector.