 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Emotionally Consistent Text-Based Speech Editing: Introducing EmoCorrector and The ECD-TSE Dataset
May 24, 2025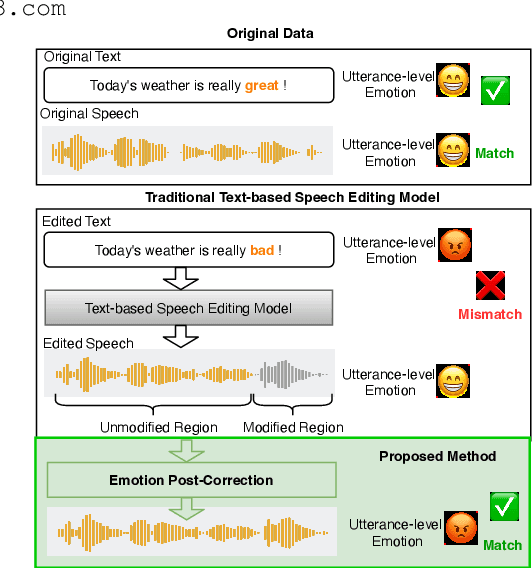


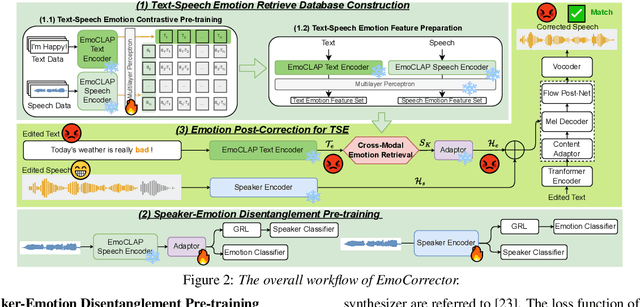
Text-based speech editing (TSE) modifies speech using only text, eliminating re-recording. However, existing TSE methods, mainly focus on the content accuracy and acoustic consistency of synthetic speech segments, and often overlook the emotional shifts or inconsistency issues introduced by text changes. To address this issue, we propose EmoCorrector, a novel post-correction scheme for TSE. EmoCorrector leverages Retrieval-Augmented Generation (RAG) by extracting the edited text's emotional features, retrieving speech samples with matching emotions, and synthesizing speech that aligns with the desired emotion while preserving the speaker's identity and quality. To support the training and evaluation of emotional consistency modeling in TSE, we pioneer the benchmarking Emotion Correction Dataset for TSE (ECD-TSE). The prominent aspect of ECD-TSE is its inclusion of $<$text, speech$>$ paired data featuring diverse text variations and a range of emotional expressions. Subjective and objective experiments and comprehensive analysis on ECD-TSE confirm that EmoCorrector significantly enhances the expression of intended emotion while addressing emotion inconsistency limitations in current TSE methods. Code and audio examples are available at https://github.com/AI-S2-Lab/EmoCorrector.
FluentEditor: Text-based Speech Editing by Considering Acoustic and Prosody Consistency
Sep 22, 2023



Text-based speech editing (TSE) techniques are designed to enable users to edit the output audio by modifying the input text transcript instead of the audio itself. Despite much progress in neural network-based TSE techniques, the current techniques have focused on reducing the difference between the generated speech segment and the reference target in the editing region, ignoring its local and global fluency in the context and original utterance. To maintain the speech fluency, we propose a fluency speech editing model, termed \textit{FluentEditor}, by considering fluency-aware training criterion in the TSE training. Specifically, the \textit{acoustic consistency constraint} aims to smooth the transition between the edited region and its neighboring acoustic segments consistent with the ground truth, while the \textit{prosody consistency constraint} seeks to ensure that the prosody attributes within the edited regions remain consistent with the overall style of the original utterance. The subjective and objective experimental results on VCTK demonstrate that our \textit{FluentEditor} outperforms all advanced baselines in terms of naturalness and fluency. The audio samples and code are available at \url{https://github.com/Ai-S2-Lab/FluentEditor}.