 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloDrive: Holistic 2D-3D Multi-Modal Street Scene Generation for Autonomous Driving
Dec 03, 2024



Generative models have significantly improved the generation and prediction quality on either camera images or LiDAR point clouds for autonomous driving. However, a real-world autonomous driving system uses multiple kinds of input modality, usually cameras and LiDARs, where they contain complementary information for generation, while existing generation methods ignore this crucial feature, resulting in the generated results only covering separate 2D or 3D information. In order to fill the gap in 2D-3D multi-modal joint generation for autonomous driving, in this paper, we propose our framework, \emph{HoloDrive}, to jointly generate the camera images and LiDAR point clouds. We employ BEV-to-Camera and Camera-to-BEV transform modules between heterogeneous generative models, and introduce a depth prediction branch in the 2D generative model to disambiguate the un-projecting from image space to BEV space, then extend the method to predict the future by adding temporal structure and carefully designed progressive training. Further, we conduct experiments on single frame generation and world model benchmarks, and demonstrate our method leads to significant performance gains over SOTA methods in terms of generation metrics.
Comprehensive Performance Evaluation of YOLOv11, YOLOv10, YOLOv9, YOLOv8 and YOLOv5 on Object Detection of Power Equipment
Nov 28, 2024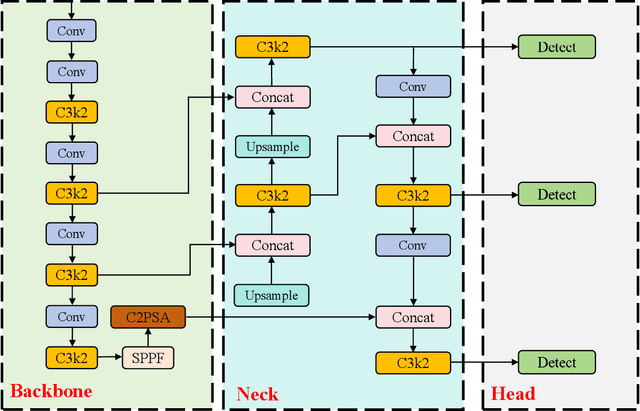


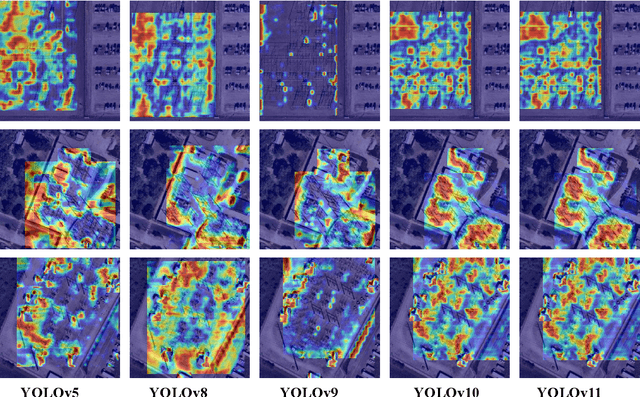
With the rapid development of global industrial production, the demand for reliability in power equipment has been continuously increasing. Ensuring the stability of power system operations requires accurate methods to detect potential faults in power equipment, thereby guaranteeing the normal supply of electrical energy. In this article, the performance of YOLOv5, YOLOv8, YOLOv9, YOLOv10, and the state-of-the-art YOLOv11 methods was comprehensively evaluated for power equipment object detection. Experimental results demonstrate that the mean average precision (mAP) on a public dataset for power equipment was 54.4%, 55.5%, 43.8%, 48.0%, and 57.2%, respectively, with the YOLOv11 achieving the highest detection performance. Moreover, the YOLOv11 outperformed other methods in terms of recall rate and exhibited superior performance in reducing false detections. In conclusion, the findings indicate that the YOLOv11 model provides a reliable and effective solution for power equipment object detection, representing a promising approach to enhancing the operational reliability of power systems.
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Symmetric Perception and Ordinal Regression for Detecting Scoliosis Natural Image
Nov 24, 2024Scoliosis is one of the most common diseases in adolescents. Traditional screening methods for the scoliosis usually use radiographic examination, which requires certified experts with medical instruments and brings the radiation risk. Considering such requirement and inconvenience, we propose to use natural images of the human back for wide-range scoliosis screening, which is a challenging problem. In this paper, we notice that the human back has a certain degree of symmetry, and asymmetrical human backs are usually caused by spinal lesions. Besides, scoliosis severity levels have ordinal relationships. Taking inspiration from this, we propose a dual-path scoliosis detection network with two main modules: symmetric feature matching module (SFMM) and ordinal regression head (ORH). Specifically, we first adopt a backbone to extract features from both the input image and its horizontally flipped image. Then, we feed the two extracted features into the SFMM to capture symmetric relationships. Finally, we use the ORH to transform the ordinal regression problem into a series of binary classification sub-problems. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods as well as human performance, which provides a promising and economic solution to wide-range scoliosis screening. In particular, our method achieves accuracies of 95.11% and 81.46% in estimation of general severity level and fine-grained severity level of the scoliosis, respectively.
Continual Learning and Lifting of Koopman Dynamics for Linear Control of Legged Robots
Nov 21, 2024The control of legged robots, particularly humanoid and quadruped robots, presents significant challenges due to their high-dimensional and nonlinear dynamics. While linear systems can be effectively controlled using methods like Model Predictive Control (MPC), the control of nonlinear systems remains complex. One promising solution is the Koopman Operator, which approximates nonlinear dynamics with a linear model, enabling the use of proven linear control techniques. However, achieving accurate linearization through data-driven methods is difficult due to issues like approximation error, domain shifts, and the limitations of fixed linear state-space representations. These challenges restrict the scalability of Koopman-based approaches. This paper addresses these challenges by proposing a continual learning algorithm designed to iteratively refine Koopman dynamics for high-dimensional legged robots. The key idea is to progressively expand the dataset and latent space dimension, enabling the learned Koopman dynamics to converge towards accurate approximations of the true system dynamics. Theoretical analysis shows that the linear approximation error of our method converges monotonically. Experimental results demonstrate that our method achieves high control performance on robots like Unitree G1/H1/A1/Go2 and ANYmal D, across various terrains using simple linear MPC controllers. This work is the first to successfully apply linearized Koopman dynamics for locomotion control of high-dimensional legged robots, enabling a scalable model-based control solution.
ManiSkill-ViTac 2025: Challenge on Manipulation Skill Learning With Vision and Tactile Sensing
Nov 19, 2024This article introduces the ManiSkill-ViTac Challenge 2025, which focuses on learning contact-rich manipulation skills using both tactile and visual sensing. Expanding upon the 2024 challenge, ManiSkill-ViTac 2025 includes 3 independent tracks: tactile manipulation, tactile-vision fusion manipulation, and tactile sensor structure design. The challenge aims to push the boundaries of robotic manipulation skills, emphasizing the integration of tactile and visual data to enhance performance in complex, real-world tasks. Participants will be evaluated using standardized metrics across both simulated and real-world environments, spurring innovations in sensor design and significantly advancing the field of vision-tactile fusion in robotics.
Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
Oct 10, 2024As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at https://koala36m.github.io/.
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024



Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Absolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Oct 02, 2024



Enforcing state-wise safety constraints is critical for the application of reinforcement learning (RL) in real-world problems, such as autonomous driving and robot manipulation. However, existing safe RL methods only enforce state-wise constraints in expectation or enforce hard state-wise constraints with strong assumptions. The former does not exclude the probability of safety violations, while the latter is impractical. Our insight is that although it is intractable to guarantee hard state-wise constraints in a model-free setting, we can enforce state-wise safety with high probability while excluding strong assumptions. To accomplish the goal, we propose Absolute State-wise Constrained Policy Optimization (ASCPO), a novel general-purpose policy search algorithm that guarantees high-probability state-wise constraint satisfaction for stochastic systems. We demonstrate the effectiveness of our approach by training neural network policies for extensive robot locomotion tasks, where the agent must adhere to various state-wise safety constraints. Our results show that ASCPO significantly outperforms existing methods in handling state-wise constraints across challenging continuous control tasks, highlighting its potential for real-world applications.
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.