 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Jun 08, 2026Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
DTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025
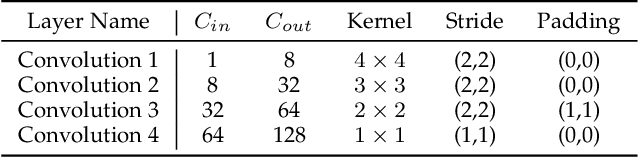


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
Modality-Guided Dynamic Graph Fusion and Temporal Diffusion for Self-Supervised RGB-T Tracking
May 06, 2025To reduce the reliance on large-scale annotations, self-supervised RGB-T tracking approaches have garnered significant attention. However, the omission of the object region by erroneous pseudo-label or the introduction of background noise affects the efficiency of modality fusion, while pseudo-label noise triggered by similar object noise can further affect the tracking performance. In this paper, we propose GDSTrack, a novel approach that introduces dynamic graph fusion and temporal diffusion to address the above challenges in self-supervised RGB-T tracking. GDSTrack dynamically fuses the modalities of neighboring frames, treats them as distractor noise, and leverages the denoising capability of a generative model. Specifically, by constructing an adjacency matrix via an Adjacency Matrix Generator (AMG), the proposed Modality-guided Dynamic Graph Fusion (MDGF) module uses a dynamic adjacency matrix to guide graph attention, focusing on and fusing the object's coherent regions. Temporal Graph-Informed Diffusion (TGID) models MDGF features from neighboring frames as interference, and thus improving robustness against similar-object noise. Extensive experiments conducted on four public RGB-T tracking datasets demonstrate that GDSTrack outperforms the existing state-of-the-art methods. The source code is available at https://github.com/LiShenglana/GDSTrack.
G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
Dec 19, 2024



Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at https://github.com/ztangaj/gveval
Symmetric Perception and Ordinal Regression for Detecting Scoliosis Natural Image
Nov 24, 2024Scoliosis is one of the most common diseases in adolescents. Traditional screening methods for the scoliosis usually use radiographic examination, which requires certified experts with medical instruments and brings the radiation risk. Considering such requirement and inconvenience, we propose to use natural images of the human back for wide-range scoliosis screening, which is a challenging problem. In this paper, we notice that the human back has a certain degree of symmetry, and asymmetrical human backs are usually caused by spinal lesions. Besides, scoliosis severity levels have ordinal relationships. Taking inspiration from this, we propose a dual-path scoliosis detection network with two main modules: symmetric feature matching module (SFMM) and ordinal regression head (ORH). Specifically, we first adopt a backbone to extract features from both the input image and its horizontally flipped image. Then, we feed the two extracted features into the SFMM to capture symmetric relationships. Finally, we use the ORH to transform the ordinal regression problem into a series of binary classification sub-problems. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods as well as human performance, which provides a promising and economic solution to wide-range scoliosis screening. In particular, our method achieves accuracies of 95.11% and 81.46% in estimation of general severity level and fine-grained severity level of the scoliosis, respectively.
SG-LRA: Self-Generating Automatic Scoliosis Cobb Angle Measurement with Low-Rank Approximation
Nov 19, 2024



Automatic Cobb angle measurement from X-ray images is crucial for scoliosis screening and diagnosis. However, most existing regression-based methods and segmentation-based methods struggle with inaccurate spine representations or mask connectivity/fragmentation issues. Besides, landmark-based methods suffer from insufficient training data and annotations. To address these challenges, we propose a novel framework including Self-Generation pipeline and Low-Rank Approximation representation (SG-LRA) for automatic Cobb angle measurement. Specifically, we propose a parameterized spine contour representation based on LRA, which enables eigen-spine decomposition and spine contour reconstruction. We can directly obtain spine contour with only regressed LRA coefficients, which form a more accurate spine representation than rectangular boxes. Also, we combine LRA coefficient regression with anchor box classification to solve inaccurate predictions and mask connectivity issues. Moreover, we develop a data engine with automatic annotation and automatic selection in an iterative manner, which is trained on a private Spinal2023 dataset. With our data engine, we generate the largest scoliosis X-ray dataset named Spinal-AI2024 largely without privacy leaks. Extensive experiments on public AASCE2019, private Spinal2023, and generated Spinal-AI2024 datasets demonstrate that our method achieves state-of-the-art Cobb angle measurement performance. Our code and Spinal-AI2024 dataset are available at https://github.com/Ernestchenchen/SG-LRA and https://github.com/Ernestchenchen/Spinal-AI2024, respectively.
Facial Action Unit Detection by Adaptively Constraining Self-Attention and Causally Deconfounding Sample
Oct 02, 2024Facial action unit (AU) detection remains a challenging task, due to the subtlety, dynamics, and diversity of AUs. Recently, the prevailing techniques of self-attention and causal inference have been introduced to AU detection. However, most existing methods directly learn self-attention guided by AU detection, or employ common patterns for all AUs during causal intervention. The former often captures irrelevant information in a global range, and the latter ignores the specific causal characteristic of each AU. In this paper, we propose a novel AU detection framework called AC2D by adaptively constraining self-attention weight distribution and causally deconfounding the sample confounder. Specifically, we explore the mechanism of self-attention weight distribution, in which the self-attention weight distribution of each AU is regarded as spatial distribution and is adaptively learned under the constraint of location-predefined attention and the guidance of AU detection. Moreover, we propose a causal intervention module for each AU, in which the bias caused by training samples and the interference from irrelevant AUs are both suppressed. Extensive experiments show that our method achieves competitive performance compared to state-of-the-art AU detection approaches on challenging benchmarks, including BP4D, DISFA, GFT, and BP4D+ in constrained scenarios and Aff-Wild2 in unconstrained scenarios. The code is available at https://github.com/ZhiwenShao/AC2D.
SimAda: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Jan 31, 2024



Segment anything model (SAM) has demonstrated excellent generalization capabilities in common vision scenarios, yet lacking an understanding of specialized data. Although numerous works have focused on optimizing SAM for downstream tasks, these task-specific approaches usually limit the generalizability to other downstream tasks. In this paper, we aim to investigate the impact of the general vision modules on finetuning SAM and enable them to generalize across all downstream tasks. We propose a simple unified framework called SimAda for adapting SAM in underperformed scenes. Specifically, our framework abstracts the general modules of different methods into basic design elements, and we design four variants based on a shared theoretical framework. SimAda is simple yet effective, which removes all dataset-specific designs and focuses solely on general optimization, ensuring that SimAda can be applied to all SAM-based and even Transformer-based models. We conduct extensive experiments on nine datasets of six downstream tasks. The results demonstrate that SimAda significantly improves the performance of SAM on multiple downstream tasks and achieves state-of-the-art performance on most of them, without requiring task-specific designs. Code is available at: https://github.com/zongzi13545329/SimAda
CT-Net: Arbitrary-Shaped Text Detection via Contour Transformer
Jul 25, 2023



Contour based scene text detection methods have rapidly developed recently, but still suffer from inaccurate frontend contour initialization, multi-stage error accumulation, or deficient local information aggregation. To tackle these limitations, we propose a novel arbitrary-shaped scene text detection framework named CT-Net by progressive contour regression with contour transformers. Specifically, we first employ a contour initialization module that generates coarse text contours without any post-processing. Then, we adopt contour refinement modules to adaptively refine text contours in an iterative manner, which are beneficial for context information capturing and progressive global contour deformation. Besides, we propose an adaptive training strategy to enable the contour transformers to learn more potential deformation paths, and introduce a re-score mechanism that can effectively suppress false positives. Extensive experiments are conducted on four challenging datasets, which demonstrate the accuracy and efficiency of our CT-Net over state-of-the-art methods. Particularly, CT-Net achieves F-measure of 86.1 at 11.2 frames per second (FPS) and F-measure of 87.8 at 10.1 FPS for CTW1500 and Total-Text datasets, respectively.