 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
Mar 12, 2026Continual Reinforcement Learning (CRL) for Vision-Language-Action (VLA) models is a promising direction toward self-improving embodied agents that can adapt in openended, evolving environments. However, conventional wisdom from continual learning suggests that naive Sequential Fine-Tuning (Seq. FT) leads to catastrophic forgetting, necessitating complex CRL strategies. In this work, we take a step back and conduct a systematic study of CRL for large pretrained VLAs across three models and five challenging lifelong RL benchmarks. We find that, contrary to established belief, simple Seq. FT with low-rank adaptation (LoRA) is remarkably strong: it achieves high plasticity, exhibits little to no forgetting, and retains strong zero-shot generalization, frequently outperforming more sophisticated CRL methods. Through detailed analysis, we show that this robustness arises from a synergy between the large pretrained model, parameter-efficient adaptation, and on-policy RL. Together, these components reshape the stability-plasticity trade-off, making continual adaptation both stable and scalable. Our results position Sequential Fine-Tuning as a powerful method for continual RL with VLAs and provide new insights into lifelong learning in the large model era. Code is available at github.com/UT-Austin-RobIn/continual-vla-rl.
Large-Language-Model-Guided State Estimation for Partially Observable Task and Motion Planning
Mar 04, 2026Robot planning in partially observable environments, where not all objects are known or visible, is a challenging problem, as it requires reasoning under uncertainty through partially observable Markov decision processes. During the execution of a computed plan, a robot may unexpectedly observe task-irrelevant objects, which are typically ignored by naive planners. In this work, we propose incorporating two types of common-sense knowledge: (1) certain objects are more likely to be found in specific locations; and (2) similar objects are likely to be co-located, while dissimilar objects are less likely to be found together. Manually engineering such knowledge is complex, so we explore leveraging the powerful common-sense reasoning capabilities of large language models (LLMs). Our planning and execution framework, CoCo-TAMP, introduces a hierarchical state estimation that uses LLM-guided information to shape the belief over task-relevant objects, enabling efficient solutions to long-horizon task and motion planning problems. In experiments, CoCo-TAMP achieves an average reduction of 62.7 in planning and execution time in simulation, and 72.6 in real-world demonstrations, compared to a baseline that does not incorporate either type of common-sense knowledge.
ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork
May 29, 2025Developing AI agents capable of collaborating with previously unseen partners is a fundamental generalization challenge in multi-agent learning, known as Ad Hoc Teamwork (AHT). Existing AHT approaches typically adopt a two-stage pipeline, where first, a fixed population of teammates is generated with the idea that they should be representative of the teammates that will be seen at deployment time, and second, an AHT agent is trained to collaborate well with agents in the population. To date, the research community has focused on designing separate algorithms for each stage. This separation has led to algorithms that generate teammate pools with limited coverage of possible behaviors, and that ignore whether the generated teammates are easy to learn from for the AHT agent. Furthermore, algorithms for training AHT agents typically treat the set of training teammates as static, thus attempting to generalize to previously unseen partner agents without assuming any control over the distribution of training teammates. In this paper, we present a unified framework for AHT by reformulating the problem as an open-ended learning process between an ad hoc agent and an adversarial teammate generator. We introduce ROTATE, a regret-driven, open-ended training algorithm that alternates between improving the AHT agent and generating teammates that probe its deficiencies. Extensive experiments across diverse AHT environments demonstrate that ROTATE significantly outperforms baselines at generalizing to an unseen set of evaluation teammates, thus establishing a new standard for robust and generalizable teamwork.
Effort Allocation for Deadline-Aware Task and Motion Planning: A Metareasoning Approach
Oct 08, 2024



In robot planning, tasks can often be achieved through multiple options, each consisting of several actions. This work specifically addresses deadline constraints in task and motion planning, aiming to find a plan that can be executed within the deadline despite uncertain planning and execution times. We propose an effort allocation problem, formulated as a Markov decision process (MDP), to find such a plan by leveraging metareasoning perspectives to allocate computational resources among the given options. We formally prove the NP-hardness of the problem by reducing it from the knapsack problem. Both a model-based approach, where transition models are learned from past experience, and a model-free approach, which overcomes the unavailability of prior data acquisition through reinforcement learning, are explored. For the model-based approach, we investigate Monte Carlo tree search (MCTS) to approximately solve the proposed MDP and further design heuristic schemes to tackle NP-hardness, leading to the approximate yet efficient algorithm called DP_Rerun. In experiments, DP_Rerun demonstrates promising performance comparable to MCTS while requiring negligible computation time.
PRESTO: Fast motion planning using diffusion models based on key-configuration environment representation
Sep 24, 2024



We introduce a learning-guided motion planning framework that provides initial seed trajectories using a diffusion model for trajectory optimization. Given a workspace, our method approximates the configuration space (C-space) obstacles through a key-configuration representation that consists of a sparse set of task-related key configurations, and uses this as an input to the diffusion model. The diffusion model integrates regularization terms that encourage collision avoidance and smooth trajectories during training, and trajectory optimization refines the generated seed trajectories to further correct any colliding segments. Our experimental results demonstrate that using high-quality trajectory priors, learned through our C-space-grounded diffusion model, enables efficient generation of collision-free trajectories in narrow-passage environments, outperforming prior learning- and planning-based baselines. Videos and additional materials can be found on the project page: https://kiwi-sherbet.github.io/PRESTO.
Asynchronous Task Plan Refinement for Multi-Robot Task and Motion Planning
Sep 16, 2023This paper explores general multi-robot task and motion planning, where multiple robots in close proximity manipulate objects while satisfying constraints and a given goal. In particular, we formulate the plan refinement problem--which, given a task plan, finds valid assignments of variables corresponding to solution trajectories--as a hybrid constraint satisfaction problem. The proposed algorithm follows several design principles that yield the following features: (1) efficient solution finding due to sequential heuristics and implicit time and roadmap representations, and (2) maximized feasible solution space obtained by introducing minimally necessary coordination-induced constraints and not relying on prevalent simplifications that exist in the literature. The evaluation results demonstrate the planning efficiency of the proposed algorithm, outperforming the synchronous approach in terms of makespan.
Decision-Theoretic Approaches for Robotic Environmental Monitoring -- A Survey
Aug 04, 2023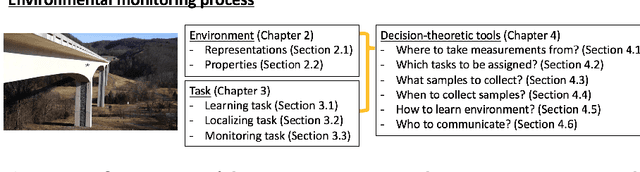



Robotics has dramatically increased our ability to gather data about our environments. This is an opportune time for the robotics and algorithms community to come together to contribute novel solutions to pressing environmental monitoring problems. In order to do so, it is useful to consider a taxonomy of problems and methods in this realm. We present the first comprehensive summary of decision theoretic approaches that are enabling efficient sampling of various kinds of environmental processes. Representations for different kinds of environments are explored, followed by a discussion of tasks of interest such as learning, localization, or monitoring. Finally, various algorithms to carry out these tasks are presented, along with a few illustrative prior results from the community.
Motion Planning (In)feasibility Detection using a Prior Roadmap via Path and Cut Search
May 18, 2023



Motion planning seeks a collision-free path in a configuration space (C-space), representing all possible robot configurations in the environment. As it is challenging to construct a C-space explicitly for a high-dimensional robot, we generally build a graph structure called a roadmap, a discrete approximation of a complex continuous C-space, to reason about connectivity. Checking collision-free connectivity in the roadmap requires expensive edge-evaluation computations, and thus, reducing the number of evaluations has become a significant research objective. However, in practice, we often face infeasible problems: those in which there is no collision-free path in the roadmap between the start and the goal locations. Existing studies often overlook the possibility of infeasibility, becoming highly inefficient by performing many edge evaluations. In this work, we address this oversight in scenarios where a prior roadmap is available; that is, the edges of the roadmap contain the probability of being a collision-free edge learned from past experience. To this end, we propose an algorithm called iterative path and cut finding (IPC) that iteratively searches for a path and a cut in a prior roadmap to detect infeasibility while reducing expensive edge evaluations as much as possible. We further improve the efficiency of IPC by introducing a second algorithm, iterative decomposition and path and cut finding (IDPC), that leverages the fact that cut-finding algorithms partition the roadmap into smaller subgraphs. We analyze the theoretical properties of IPC and IDPC, such as completeness and computational complexity, and evaluate their performance in terms of completion time and the number of edge evaluations in large-scale simulations.
Learning to Correct Mistakes: Backjumping in Long-Horizon Task and Motion Planning
Nov 15, 2022



As robots become increasingly capable of manipulation and long-term autonomy, long-horizon task and motion planning problems are becoming increasingly important. A key challenge in such problems is that early actions in the plan may make future actions infeasible. When reaching a dead-end in the search, most existing planners use backtracking, which exhaustively reevaluates motion-level actions, often resulting in inefficient planning, especially when the search depth is large. In this paper, we propose to learn backjumping heuristics which identify the culprit action directly using supervised learning models to guide the task-level search. Based on evaluations on two different tasks, we find that our method significantly improves planning efficiency compared to backtracking and also generalizes to problems with novel numbers of objects.
Towards Optimal Correlational Object Search
Oct 19, 2021
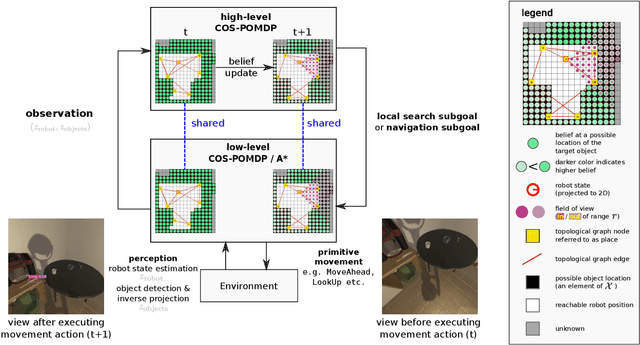


In realistic applications of object search, robots will need to locate target objects in complex environments while coping with unreliable sensors, especially for small or hard-to-detect objects. In such settings, correlational information can be valuable for planning efficiently: when looking for a fork, the robot could start by locating the easier-to-detect refrigerator, since forks would probably be found nearby. Previous approaches to object search with correlational information typically resort to ad-hoc or greedy search strategies. In this paper, we propose the Correlational Object Search POMDP (COS-POMDP), which can be solved to produce search strategies that use correlational information. COS-POMDPs contain a correlation-based observation model that allows us to avoid the exponential blow-up of maintaining a joint belief about all objects, while preserving the optimal solution to this naive, exponential POMDP formulation. We propose a hierarchical planning algorithm to scale up COS-POMDP for practical domains. We conduct experiments using AI2-THOR, a realistic simulator of household environments, as well as YOLOv5, a widely-used object detector. Our results show that, particularly for hard-to-detect objects, such as scrub brush and remote control, our method offers the most robust performance compared to baselines that ignore correlations as well as a greedy, next-best view approach.