 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR: Gaussian Splatting Tracking and Reconstruction of Unknown Objects Based on Appearance and Geometric Complexity
May 17, 2025We present a novel method for 6-DoF object tracking and high-quality 3D reconstruction from monocular RGBD video. Existing methods, while achieving impressive results, often struggle with complex objects, particularly those exhibiting symmetry, intricate geometry or complex appearance. To bridge these gaps, we introduce an adaptive method that combines 3D Gaussian Splatting, hybrid geometry/appearance tracking, and key frame selection to achieve robust tracking and accurate reconstructions across a diverse range of objects. Additionally, we present a benchmark covering these challenging object classes, providing high-quality annotations for evaluating both tracking and reconstruction performance. Our approach demonstrates strong capabilities in recovering high-fidelity object meshes, setting a new standard for single-sensor 3D reconstruction in open-world environments.
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025



Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
Can We Detect Failures Without Failure Data? Uncertainty-Aware Runtime Failure Detection for Imitation Learning Policies
Mar 11, 2025Recent years have witnessed impressive robotic manipulation systems driven by advances in imitation learning and generative modeling, such as diffusion- and flow-based approaches. As robot policy performance increases, so does the complexity and time horizon of achievable tasks, inducing unexpected and diverse failure modes that are difficult to predict a priori. To enable trustworthy policy deployment in safety-critical human environments, reliable runtime failure detection becomes important during policy inference. However, most existing failure detection approaches rely on prior knowledge of failure modes and require failure data during training, which imposes a significant challenge in practicality and scalability. In response to these limitations, we present FAIL-Detect, a modular two-stage approach for failure detection in imitation learning-based robotic manipulation. To accurately identify failures from successful training data alone, we frame the problem as sequential out-of-distribution (OOD) detection. We first distill policy inputs and outputs into scalar signals that correlate with policy failures and capture epistemic uncertainty. FAIL-Detect then employs conformal prediction (CP) as a versatile framework for uncertainty quantification with statistical guarantees. Empirically, we thoroughly investigate both learned and post-hoc scalar signal candidates on diverse robotic manipulation tasks. Our experiments show learned signals to be mostly consistently effective, particularly when using our novel flow-based density estimator. Furthermore, our method detects failures more accurately and faster than state-of-the-art (SOTA) failure detection baselines. These results highlight the potential of FAIL-Detect to enhance the safety and reliability of imitation learning-based robotic systems as they progress toward real-world deployment.
IMLE Policy: Fast and Sample Efficient Visuomotor Policy Learning via Implicit Maximum Likelihood Estimation
Feb 17, 2025



Recent advances in imitation learning, particularly using generative modelling techniques like diffusion, have enabled policies to capture complex multi-modal action distributions. However, these methods often require large datasets and multiple inference steps for action generation, posing challenges in robotics where the cost for data collection is high and computation resources are limited. To address this, we introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38\% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3\% compared to Diffusion Policy, while outperforming single-step Flow Matching. We validate our approach across diverse manipulation tasks in simulated and real-world environments, showcasing its ability to capture complex behaviours under data constraints. Videos and code are provided on our project page: https://imle-policy.github.io/.
Affordance-Centric Policy Learning: Sample Efficient and Generalisable Robot Policy Learning using Affordance-Centric Task Frames
Oct 15, 2024



Affordances are central to robotic manipulation, where most tasks can be simplified to interactions with task-specific regions on objects. By focusing on these key regions, we can abstract away task-irrelevant information, simplifying the learning process, and enhancing generalisation. In this paper, we propose an affordance-centric policy-learning approach that centres and appropriately \textit{orients} a \textit{task frame} on these affordance regions allowing us to achieve both \textbf{intra-category invariance} -- where policies can generalise across different instances within the same object category -- and \textbf{spatial invariance} -- which enables consistent performance regardless of object placement in the environment. We propose a method to leverage existing generalist large vision models to extract and track these affordance frames, and demonstrate that our approach can learn manipulation tasks using behaviour cloning from as little as 10 demonstrations, with equivalent generalisation to an image-based policy trained on 305 demonstrations. We provide video demonstrations on our project site: https://affordance-policy.github.io.
DiffusionNOCS: Managing Symmetry and Uncertainty in Sim2Real Multi-Modal Category-level Pose Estimation
Feb 20, 2024



This paper addresses the challenging problem of category-level pose estimation. Current state-of-the-art methods for this task face challenges when dealing with symmetric objects and when attempting to generalize to new environments solely through synthetic data training. In this work, we address these challenges by proposing a probabilistic model that relies on diffusion to estimate dense canonical maps crucial for recovering partial object shapes as well as establishing correspondences essential for pose estimation. Furthermore, we introduce critical components to enhance performance by leveraging the strength of the diffusion models with multi-modal input representations. We demonstrate the effectiveness of our method by testing it on a range of real datasets. Despite being trained solely on our generated synthetic data, our approach achieves state-of-the-art performance and unprecedented generalization qualities, outperforming baselines, even those specifically trained on the target domain.
Gravity-aware Grasp Generation with Implicit Grasp Mode Selection for Underactuated Hands
Dec 19, 2023



To overcome the mechanical limitation of parallel-jaw grippers, in this paper, we present a gravity-aware grasp generation that supports both precision grasp and power grasp of underactuated hands. We propose a novel approach to generate a large-scale dataset with a gravity-rejection score and experimentally confirm that the combination of that score and classical success/fail binary classification is powerful: the former encourages stable grasps, such as power grasps or grasping the center of mass, while the latter rejects invalid grasps, such as colliding with other objects or attempting to grasp parts that are too large for the gripper. We also propose a rotation representation that is continuous on SO(3) and considers the grasp's physical meaning. Our simulation and real robot evaluation experiments demonstrate significant improvements from the baseline works, especially for heavy objects.
GS-Pose: Category-Level Object Pose Estimation via Geometric and Semantic Correspondence
Nov 23, 2023



Category-level pose estimation is a challenging task with many potential applications in computer vision and robotics. Recently, deep-learning-based approaches have made great progress, but are typically hindered by the need for large datasets of either pose-labelled real images or carefully tuned photorealistic simulators. This can be avoided by using only geometry inputs such as depth images to reduce the domain-gap but these approaches suffer from a lack of semantic information, which can be vital in the pose estimation problem. To resolve this conflict, we propose to utilize both geometric and semantic features obtained from a pre-trained foundation model.Our approach projects 2D features from this foundation model into 3D for a single object model per category, and then performs matching against this for new single view observations of unseen object instances with a trained matching network. This requires significantly less data to train than prior methods since the semantic features are robust to object texture and appearance. We demonstrate this with a rich evaluation, showing improved performance over prior methods with a fraction of the data required.
Learning Fabric Manipulation in the Real World with Human Videos
Nov 12, 2022



Fabric manipulation is a long-standing challenge in robotics due to the enormous state space and complex dynamics. Learning approaches stand out as promising for this domain as they allow us to learn behaviours directly from data. Most prior methods however rely heavily on simulation, which is still limited by the large sim-to-real gap of deformable objects or rely on large datasets. A promising alternative is to learn fabric manipulation directly from watching humans perform the task. In this work, we explore how demonstrations for fabric manipulation tasks can be collected directly by humans, providing an extremely natural and fast data collection pipeline. Then, using only a handful of such demonstrations, we show how a pick-and-place policy can be learned and deployed on a real robot, without any robot data collection at all. We demonstrate our approach on a fabric folding task, showing that our policy can reliably reach folded states from crumpled initial configurations. Videos are available at: https://sites.google.com/view/foldingbyhand
Learning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

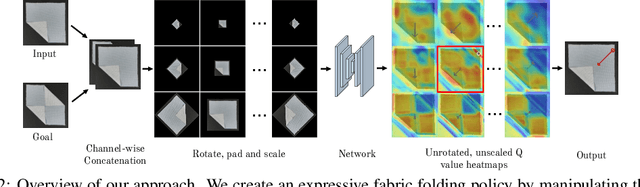
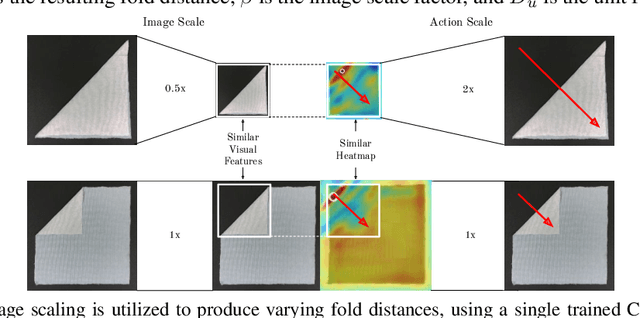
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold