 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphNet: A Large-Scale Video Benchmark for Ophthalmic Surgical Workflow Understanding
Jun 12, 2024



Surgical scene perception via videos are critical for advancing robotic surgery, telesurgery, and AI-assisted surgery, particularly in ophthalmology. However, the scarcity of diverse and richly annotated video datasets has hindered the development of intelligent systems for surgical workflow analysis. Existing datasets for surgical workflow analysis, which typically face challenges such as small scale, a lack of diversity in surgery and phase categories, and the absence of time-localized annotations, limit the requirements for action understanding and model generalization validation in complex and diverse real-world surgical scenarios. To address this gap, we introduce OphNet, a large-scale, expert-annotated video benchmark for ophthalmic surgical workflow understanding. OphNet features: 1) A diverse collection of 2,278 surgical videos spanning 66 types of cataract, glaucoma, and corneal surgeries, with detailed annotations for 102 unique surgical phases and 150 granular operations; 2) It offers sequential and hierarchical annotations for each surgery, phase, and operation, enabling comprehensive understanding and improved interpretability; 3) Moreover, OphNet provides time-localized annotations, facilitating temporal localization and prediction tasks within surgical workflows. With approximately 205 hours of surgical videos, OphNet is about 20 times larger than the largest existing surgical workflow analysis benchmark. Our dataset and code have been made available at: \url{https://github.com/minghu0830/OphNet-benchmark}.
ROSO: Improving Robotic Policy Inference via Synthetic Observations
Nov 29, 2023



In this paper, we propose the use of generative artificial intelligence (AI) to improve zero-shot performance of a pre-trained policy by altering observations during inference. Modern robotic systems, powered by advanced neural networks, have demonstrated remarkable capabilities on pre-trained tasks. However, generalizing and adapting to new objects and environments is challenging, and fine-tuning visuomotor policies is time-consuming. To overcome these issues we propose Robotic Policy Inference via Synthetic Observations (ROSO). ROSO uses stable diffusion to pre-process a robot's observation of novel objects during inference time to fit within its distribution of observations of the pre-trained policies. This novel paradigm allows us to transfer learned knowledge from known tasks to previously unseen scenarios, enhancing the robot's adaptability without requiring lengthy fine-tuning. Our experiments show that incorporating generative AI into robotic inference significantly improves successful outcomes, finishing up to 57% of tasks otherwise unsuccessful with the pre-trained policy.
An Architecture for Reactive Mobile Manipulation On-The-Move
Dec 14, 2022



We present a generalised architecture for reactive mobile manipulation while a robot's base is in motion toward the next objective in a high-level task. By performing tasks on-the-move, overall cycle time is reduced compared to methods where the base pauses during manipulation. Reactive control of the manipulator enables grasping objects with unpredictable motion while improving robustness against perception errors, environmental disturbances, and inaccurate robot control compared to open-loop, trajectory-based planning approaches. We present an example implementation of the architecture and investigate the performance on a series of pick and place tasks with both static and dynamic objects and compare the performance to baseline methods. Our method demonstrated a real-world success rate of over 99%, failing in only a single trial from 120 attempts with a physical robot system. The architecture is further demonstrated on other mobile manipulator platforms in simulation. Our approach reduces task time by up to 48%, while also improving reliability, gracefulness, and predictability compared to existing architectures for mobile manipulation. See https://benburgesslimerick.github.io/ManipulationOnTheMove for supplementary materials.
Integrating High-Resolution Tactile Sensing into Grasp Stability Prediction
Jun 12, 2022

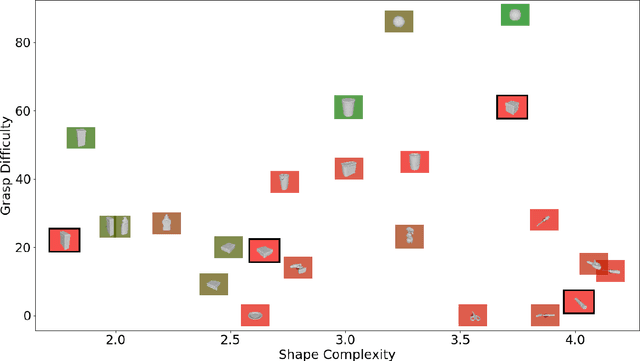
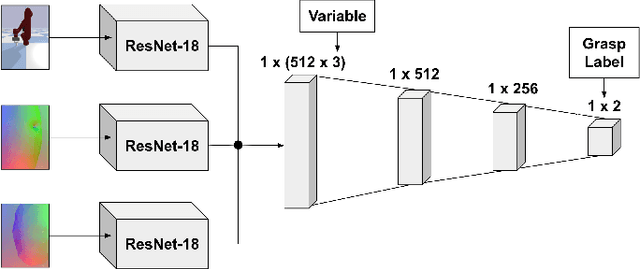
We investigate how high-resolution tactile sensors can be utilized in combination with vision and depth sensing, to improve grasp stability prediction. Recent advances in simulating high-resolution tactile sensing, in particular the TACTO simulator, enabled us to evaluate how neural networks can be trained with a combination of sensing modalities. With the large amounts of data needed to train large neural networks, robotic simulators provide a fast way to automate the data collection process. We expand on the existing work through an ablation study and an increased set of objects taken from the YCB benchmark set. Our results indicate that while the combination of vision, depth, and tactile sensing provides the best prediction results on known objects, the network fails to generalize to unknown objects. Our work also addresses existing issues with robotic grasping in tactile simulation and how to overcome them.
Eyes on the Prize: Improved Perception for Robust Dynamic Grasping
Apr 29, 2022

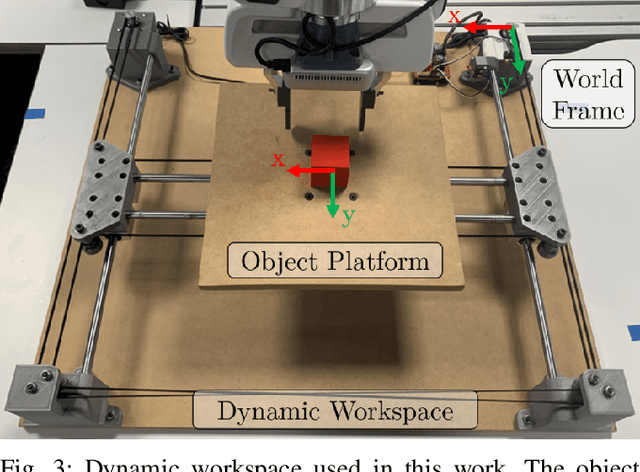
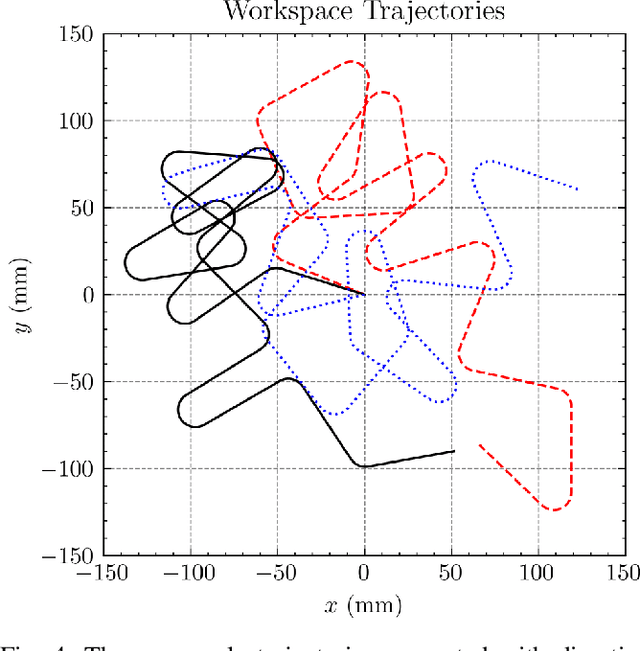
This paper is concerned with perception challenges for robust grasping in the presence of clutter and unpredictable relative motion between robot and object. Traditional perception systems developed for static grasping are unable to provide feedback during the final phase of a grasp due to sensor minimum range, occlusion, and a limited field of view. A multi-camera eye-in-hand perception system is presented that has advantages over commonly used camera configurations. We quantitatively evaluate the performance on a real robot with an image-based visual servoing grasp controller and show a significantly improved success rate on a dynamic grasping task. A fully reproducible open-source testing system is described to encourage benchmarking of dynamic grasping system performance.
Passing Through Narrow Gaps with Deep Reinforcement Learning
Mar 06, 2021
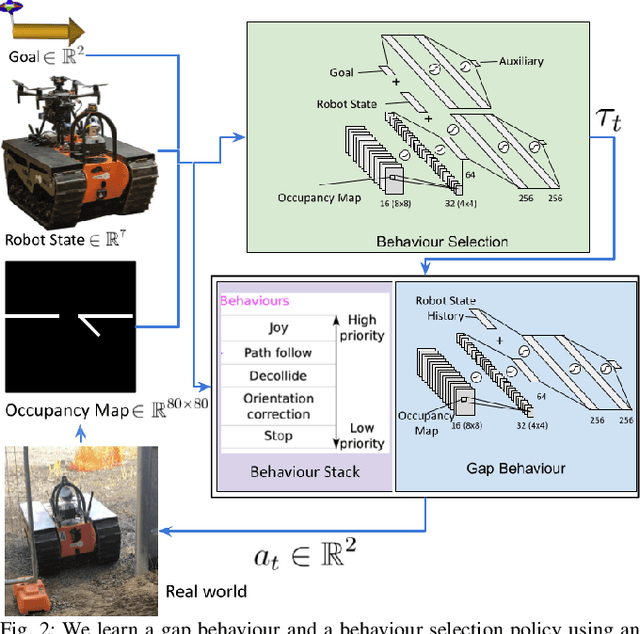

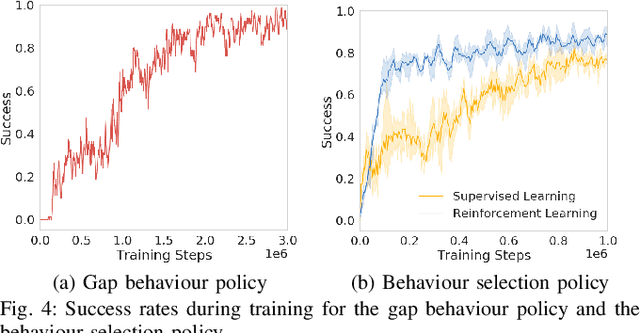
The DARPA subterranean challenge requires teams of robots to traverse difficult and diverse underground environments. Traversing small gaps is one of the challenging scenarios that robots encounter. Imperfect sensor information makes it difficult for classical navigation methods, where behaviours require significant manual fine tuning. In this paper we present a deep reinforcement learning method for autonomously navigating through small gaps, where contact between the robot and the gap may be required. We first learn a gap behaviour policy to get through small gaps (only centimeters wider than the robot). We then learn a goal-conditioned behaviour selection policy that determines when to activate the gap behaviour policy. We train our policies in simulation and demonstrate their effectiveness with a large tracked robot in simulation and on the real platform. In simulation experiments, our approach achieves 93% success rate when the gap behaviour is activated manually by an operator, and 67% with autonomous activation using the behaviour selection policy. In real robot experiments, our approach achieves a success rate of 73% with manual activation, and 40% with autonomous behaviour selection. While we show the feasibility of our approach in simulation, the difference in performance between simulated and real world scenarios highlight the difficulty of direct sim-to-real transfer for deep reinforcement learning policies. In both the simulated and real world environments alternative methods were unable to traverse the gap.
Learning Setup Policies: Reliable Transition Between Locomotion Behaviours
Jan 23, 2021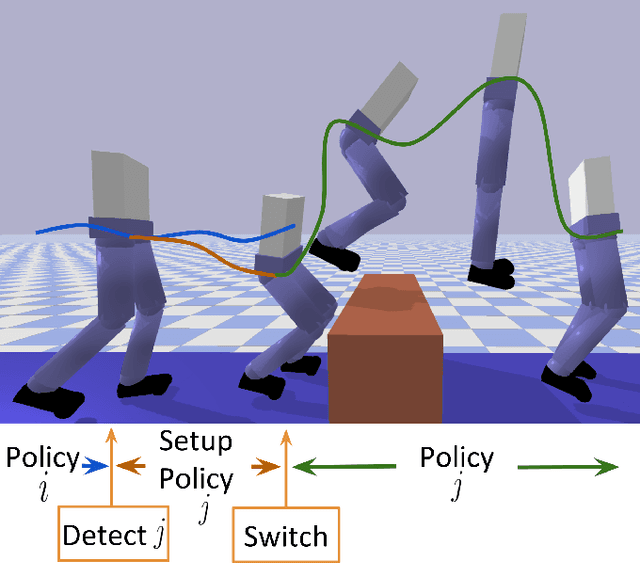
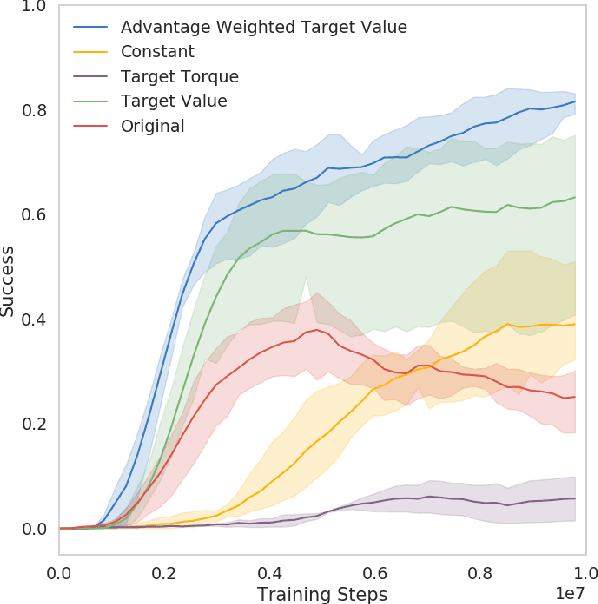

Dynamic platforms that operate over manyunique terrain conditions typically require multiple controllers.To transition safely between controllers, there must be anoverlap of states between adjacent controllers. We developa novel method for training Setup Policies that bridge thetrajectories between pre-trained Deep Reinforcement Learning(DRL) policies. We demonstrate our method with a simulatedbiped traversing a difficult jump terrain, where a single policyfails to learn the task, and switching between pre-trainedpolicies without Setup Policies also fails. We perform anablation of key components of our system, and show thatour method outperforms others that learn transition policies.We demonstrate our method with several difficult and diverseterrain types, and show that we can use Setup Policies as partof a modular control suite to successfully traverse a sequence ofcomplex terrains. We show that using Setup Policies improvesthe success rate for traversing a single difficult jump terrain(from 1.5%success rate without Setup Policies to 82%), and asequence of various terrains (from 6.5%without Setup Policiesto 29.1%).
Learning When to Switch: Composing Controllers to Traverse a Sequence of Terrain Artifacts
Nov 01, 2020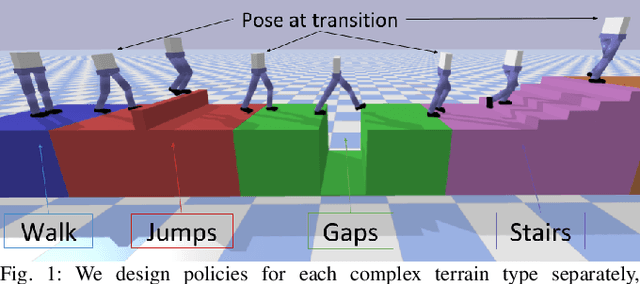
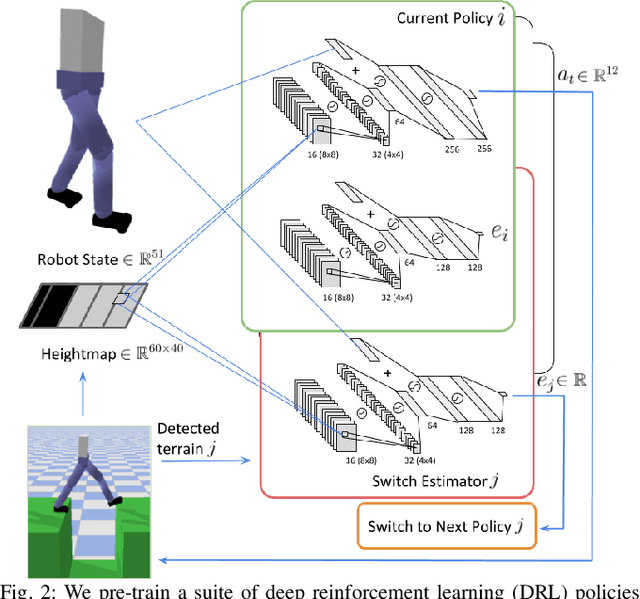
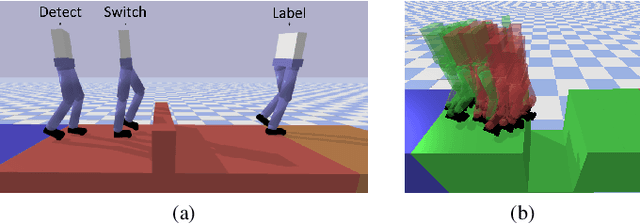
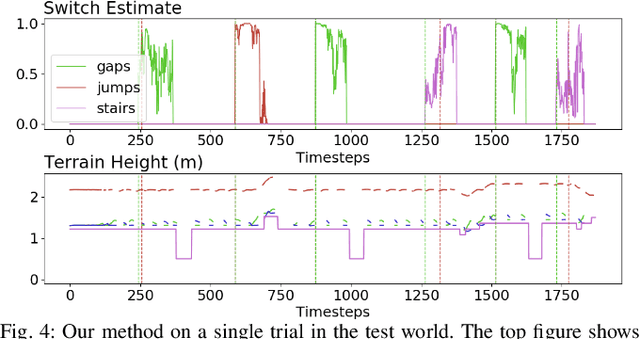
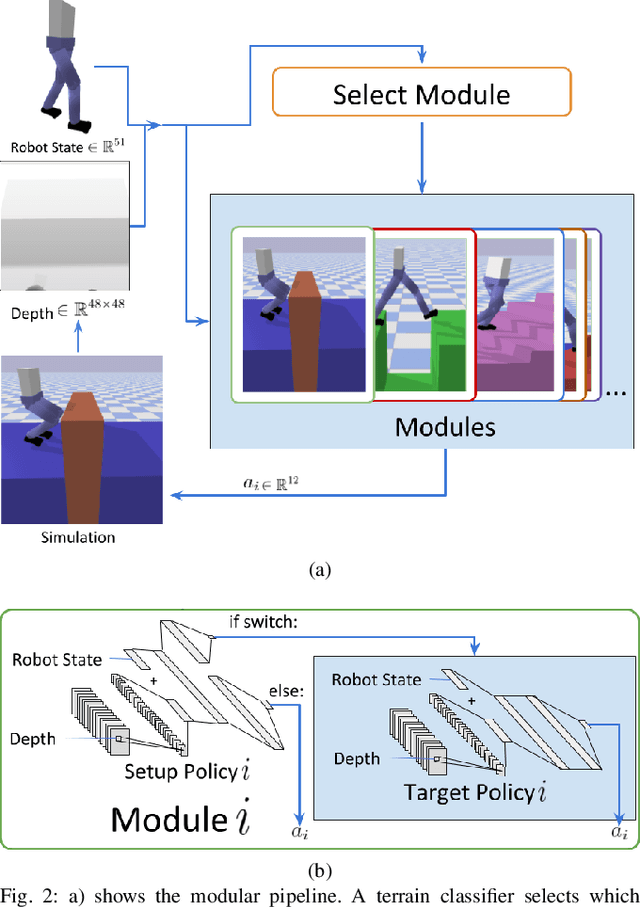
Legged robots often use separate control policies that are highly engineered for traversing difficult terrain such as stairs, gaps, and steps, where switching between policies is only possible when the robot is in a region that is common to adjacent controllers. Deep Reinforcement Learning (DRL) is a promising alternative to hand-crafted control design, though typically requires the full set of test conditions to be known before training. DRL policies can result in complex (often unrealistic) behaviours that have few or no overlapping regions between adjacent policies, making it difficult to switch behaviours. In this work we develop multiple DRL policies with Curriculum Learning (CL), each that can traverse a single respective terrain condition, while ensuring an overlap between policies. We then train a network for each destination policy that estimates the likelihood of successfully switching from any other policy. We evaluate our switching method on a previously unseen combination of terrain artifacts and show that it performs better than heuristic methods. While our method is trained on individual terrain types, it performs comparably to a Deep Q Network trained on the full set of terrain conditions. This approach allows the development of separate policies in constrained conditions with embedded prior knowledge about each behaviour, that is scalable to any number of behaviours, and prepares DRL methods for applications in the real world
Learning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

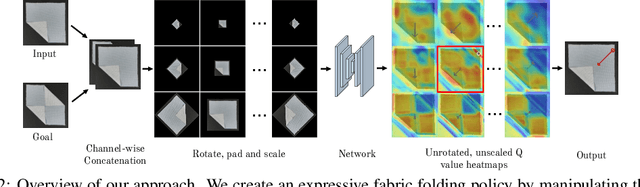
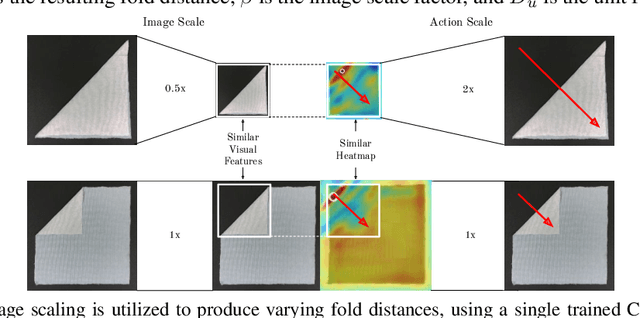
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold
Traversing the Reality Gap via Simulator Tuning
Mar 03, 2020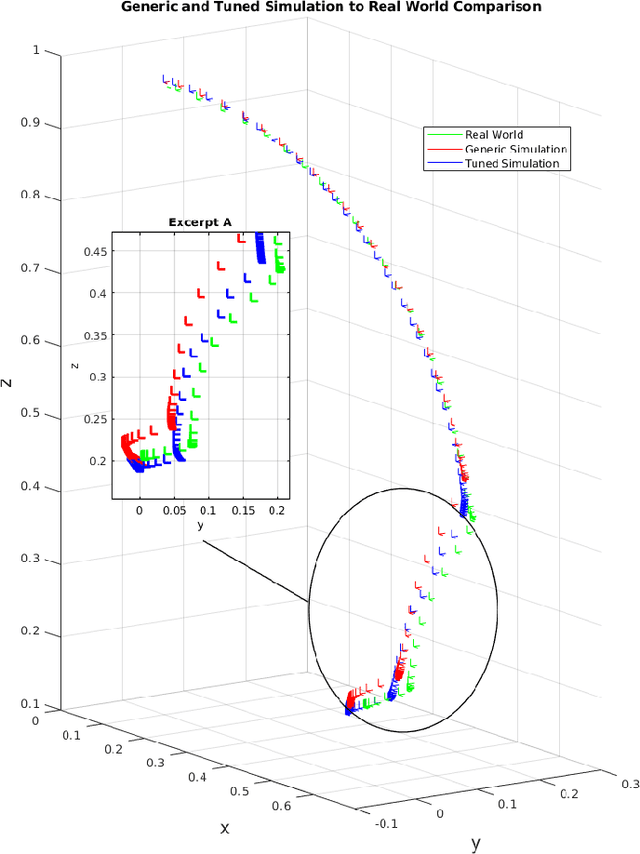
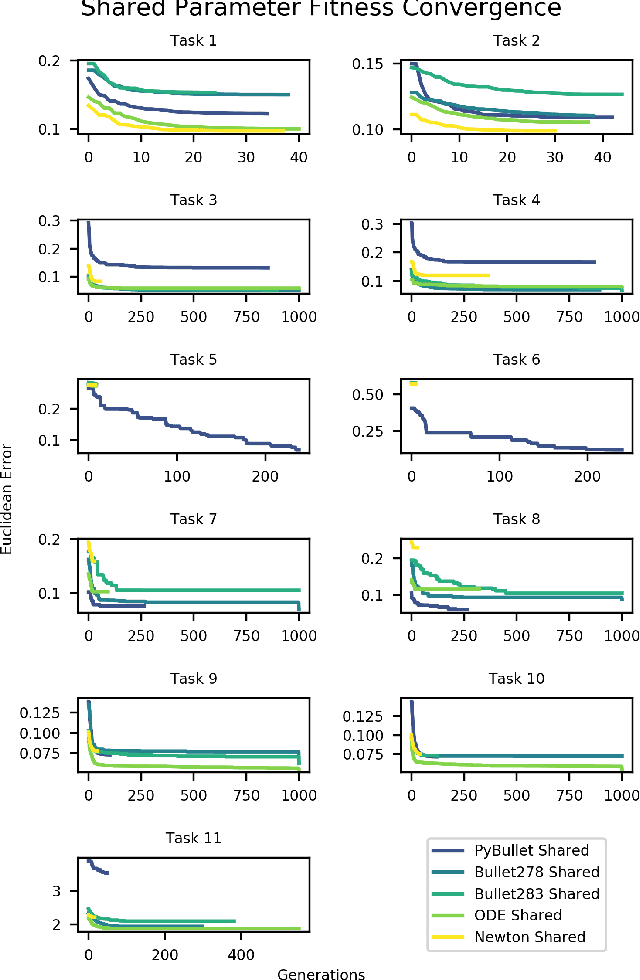
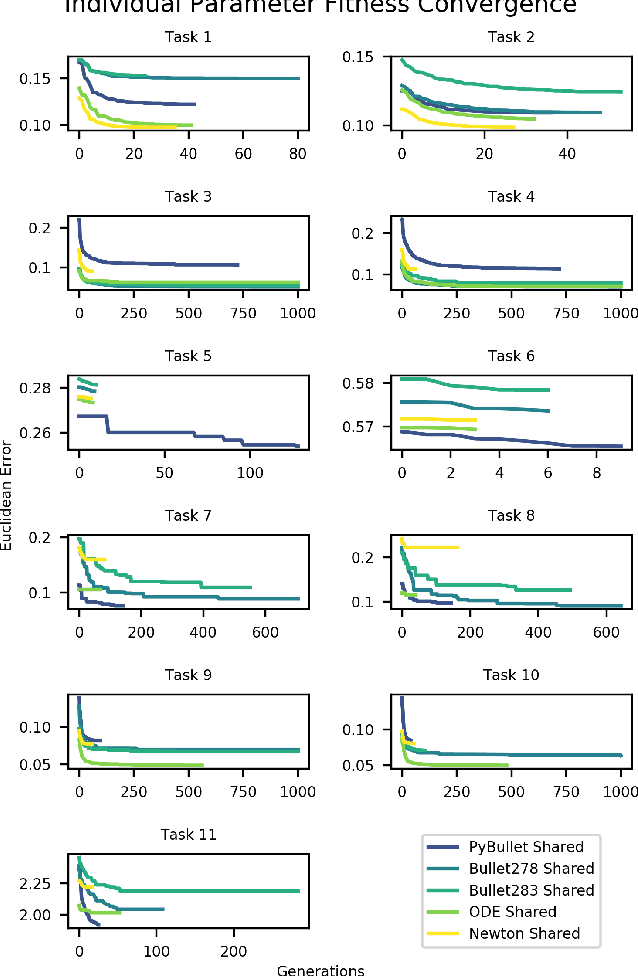
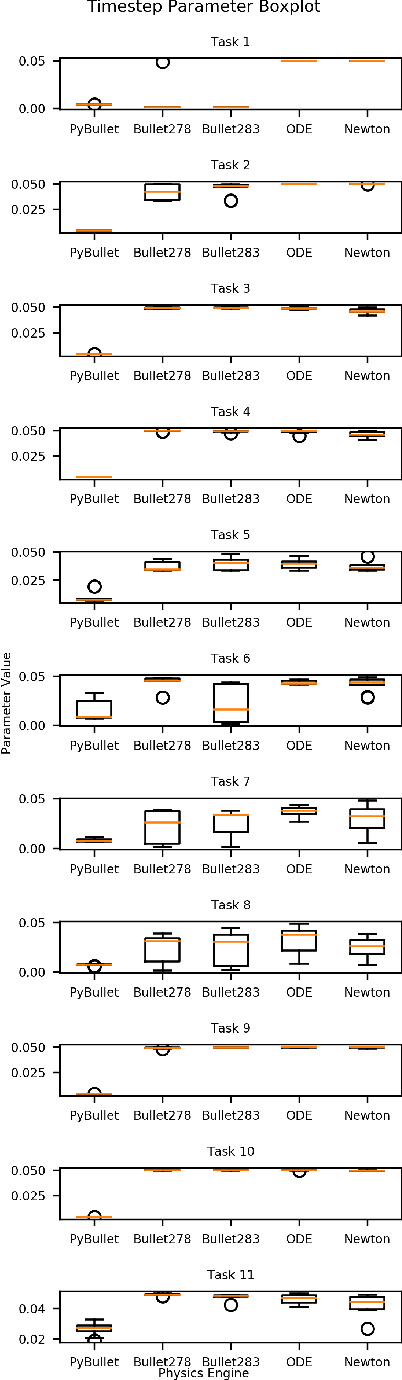
The large demand for simulated data has made the reality gap a problem on the forefront of robotics. We propose a method to traverse the gap by tuning available simulation parameters. Through the optimisation of physics engine parameters, we show that we are able to narrow the gap between simulated solutions and a real world dataset, and thus allow more ready transfer of leaned behaviours between the two. We subsequently gain understanding as to the importance of specific simulator parameters, which is of broad interest to the robotic machine learning community. We find that even optimised for different tasks that different physics engine perform better in certain scenarios and that friction and maximum actuator velocity are tightly bounded parameters that greatly impact the transference of simulated solutions.