 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Depth Map Super-Resolution and Restoration: AIM 2024 Challenge Results
Sep 24, 2024The increasing demand for augmented reality (AR) and virtual reality (VR) applications highlights the need for efficient depth information processing. Depth maps, essential for rendering realistic scenes and supporting advanced functionalities, are typically large and challenging to stream efficiently due to their size. This challenge introduces a focus on developing innovative depth upsampling techniques to reconstruct high-quality depth maps from compressed data. These techniques are crucial for overcoming the limitations posed by depth compression, which often degrades quality, loses scene details and introduces artifacts. By enhancing depth upsampling methods, this challenge aims to improve the efficiency and quality of depth map reconstruction. Our goal is to advance the state-of-the-art in depth processing technologies, thereby enhancing the overall user experience in AR and VR applications.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024



Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
PIV3CAMS: a multi-camera dataset for multiple computer vision problems and its application to novel view-point synthesis
Jul 26, 2024
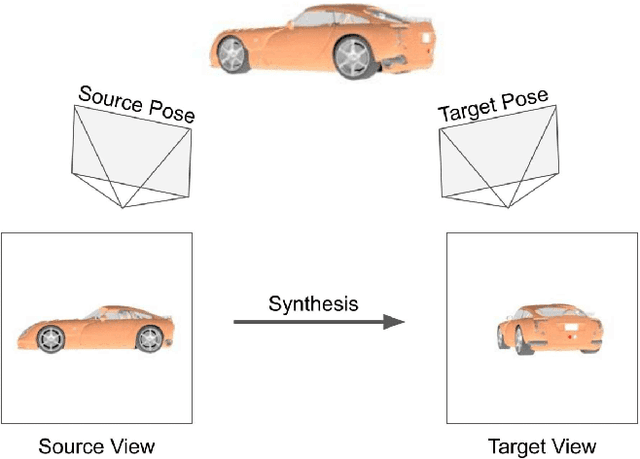


The modern approaches for computer vision tasks significantly rely on machine learning, which requires a large number of quality images. While there is a plethora of image datasets with a single type of images, there is a lack of datasets collected from multiple cameras. In this thesis, we introduce Paired Image and Video data from three CAMeraS, namely PIV3CAMS, aimed at multiple computer vision tasks. The PIV3CAMS dataset consists of 8385 pairs of images and 82 pairs of videos taken from three different cameras: Canon D5 Mark IV, Huawei P20, and ZED stereo camera. The dataset includes various indoor and outdoor scenes from different locations in Zurich (Switzerland) and Cheonan (South Korea). Some of the computer vision applications that can benefit from the PIV3CAMS dataset are image/video enhancement, view interpolation, image matching, and much more. We provide a careful explanation of the data collection process and detailed analysis of the data. The second part of this thesis studies the usage of depth information in the view synthesizing task. In addition to the regeneration of a current state-of-the-art algorithm, we investigate several proposed alternative models that integrate depth information geometrically. Through extensive experiments, we show that the effect of depth is crucial in small view changes. Finally, we apply our model to the introduced PIV3CAMS dataset to synthesize novel target views as an example application of PIV3CAMS.
Any Image Restoration with Efficient Automatic Degradation Adaptation
Jul 18, 2024



With the emergence of mobile devices, there is a growing demand for an efficient model to restore any degraded image for better perceptual quality. However, existing models often require specific learning modules tailored for each degradation, resulting in complex architectures and high computation costs. Different from previous work, in this paper, we propose a unified manner to achieve joint embedding by leveraging the inherent similarities across various degradations for efficient and comprehensive restoration. Specifically, we first dig into the sub-latent space of each input to analyze the key components and reweight their contributions in a gated manner. The intrinsic awareness is further integrated with contextualized attention in an X-shaped scheme, maximizing local-global intertwining. Extensive comparison on benchmarking all-in-one restoration setting validates our efficiency and effectiveness, i.e., our network sets new SOTA records while reducing model complexity by approximately -82% in trainable parameters and -85\% in FLOPs. Our code will be made publicly available at:https://github.com/Amazingren/AnyIR.
Stereo Risk: A Continuous Modeling Approach to Stereo Matching
Jul 03, 2024We introduce Stereo Risk, a new deep-learning approach to solve the classical stereo-matching problem in computer vision. As it is well-known that stereo matching boils down to a per-pixel disparity estimation problem, the popular state-of-the-art stereo-matching approaches widely rely on regressing the scene disparity values, yet via discretization of scene disparity values. Such discretization often fails to capture the nuanced, continuous nature of scene depth. Stereo Risk departs from the conventional discretization approach by formulating the scene disparity as an optimal solution to a continuous risk minimization problem, hence the name "stereo risk". We demonstrate that $L^1$ minimization of the proposed continuous risk function enhances stereo-matching performance for deep networks, particularly for disparities with multi-modal probability distributions. Furthermore, to enable the end-to-end network training of the non-differentiable $L^1$ risk optimization, we exploited the implicit function theorem, ensuring a fully differentiable network. A comprehensive analysis demonstrates our method's theoretical soundness and superior performance over the state-of-the-art methods across various benchmark datasets, including KITTI 2012, KITTI 2015, ETH3D, SceneFlow, and Middlebury 2014.
Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models?
Jun 20, 2024



Large vision-language models (LVLMs) have recently dramatically pushed the state of the art in image captioning and many image understanding tasks (e.g., visual question answering). LVLMs, however, often \textit{hallucinate} and produce captions that mention concepts that cannot be found in the image. These hallucinations erode the trustworthiness of LVLMs and are arguably among the main obstacles to their ubiquitous adoption. Recent work suggests that addition of grounding objectives -- those that explicitly align image regions or objects to text spans -- reduces the amount of LVLM hallucination. Although intuitive, this claim is not empirically justified as the reduction effects have been established, we argue, with flawed evaluation protocols that (i) rely on data (i.e., MSCOCO) that has been extensively used in LVLM training and (ii) measure hallucination via question answering rather than open-ended caption generation. In this work, in contrast, we offer the first systematic analysis of the effect of fine-grained object grounding on LVLM hallucination under an evaluation protocol that more realistically captures LVLM hallucination in open generation. Our extensive experiments over three backbone LLMs reveal that grounding objectives have little to no effect on object hallucination in open caption generation.
African or European Swallow? Benchmarking Large Vision-Language Models for Fine-Grained Object Classification
Jun 20, 2024Recent Large Vision-Language Models (LVLMs) demonstrate impressive abilities on numerous image understanding and reasoning tasks. The task of fine-grained object classification (e.g., distinction between \textit{animal species}), however, has been probed insufficiently, despite its downstream importance. We fill this evaluation gap by creating \texttt{FOCI} (\textbf{F}ine-grained \textbf{O}bject \textbf{C}lass\textbf{I}fication), a difficult multiple-choice benchmark for fine-grained object classification, from existing object classification datasets: (1) multiple-choice avoids ambiguous answers associated with casting classification as open-ended QA task; (2) we retain classification difficulty by mining negative labels with a CLIP model. \texttt{FOCI}\xspace complements five popular classification datasets with four domain-specific subsets from ImageNet-21k. We benchmark 12 public LVLMs on \texttt{FOCI} and show that it tests for a \textit{complementary skill} to established image understanding and reasoning benchmarks. Crucially, CLIP models exhibit dramatically better performance than LVLMs. Since the image encoders of LVLMs come from these CLIP models, this points to inadequate alignment for fine-grained object distinction between the encoder and the LLM and warrants (pre)training data with more fine-grained annotation. We release our code at \url{https://github.com/gregor-ge/FOCI-Benchmark}.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024



This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Dataset Growth
May 28, 2024



Deep learning benefits from the growing abundance of available data. Meanwhile, efficiently dealing with the growing data scale has become a challenge. Data publicly available are from different sources with various qualities, and it is impractical to do manual cleaning against noise and redundancy given today's data scale. There are existing techniques for cleaning/selecting the collected data. However, these methods are mainly proposed for offline settings that target one of the cleanness and redundancy problems. In practice, data are growing exponentially with both problems. This leads to repeated data curation with sub-optimal efficiency. To tackle this challenge, we propose InfoGrowth, an efficient online algorithm for data cleaning and selection, resulting in a growing dataset that keeps up to date with awareness of cleanliness and diversity. InfoGrowth can improve data quality/efficiency on both single-modal and multi-modal tasks, with an efficient and scalable design. Its framework makes it practical for real-world data engines.
Towards a Generalist and Blind RGB-X Tracker
May 28, 2024With the emergence of a single large model capable of successfully solving a multitude of tasks in NLP, there has been growing research interest in achieving similar goals in computer vision. On the one hand, most of these generic models, referred to as generalist vision models, aim at producing unified outputs serving different tasks. On the other hand, some existing models aim to combine different input types (aka data modalities), which are then processed by a single large model. Yet, this step of combination remains specialized, which falls short of serving the initial ambition. In this paper, we showcase that such specialization (during unification) is unnecessary, in the context of RGB-X video object tracking. Our single model tracker, termed XTrack, can remain blind to any modality X during inference time. Our tracker employs a mixture of modal experts comprising those dedicated to shared commonality and others capable of flexibly performing reasoning conditioned on input modality. Such a design ensures the unification of input modalities towards a common latent space, without weakening the modality-specific information representation. With this idea, our training process is extremely simple, integrating multi-label classification loss with a routing function, thereby effectively aligning and unifying all modalities together, even from only paired data. Thus, during inference, we can adopt any modality without relying on the inductive bias of the modal prior and achieve generalist performance. Without any bells and whistles, our generalist and blind tracker can achieve competitive performance compared to well-established modal-specific models on 5 benchmarks across 3 auxiliary modalities, covering commonly used depth, thermal, and event data.