 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLivingWorld: Interactive 4D World Generation with Environmental Dynamics
Apr 02, 2026We introduce LivingWorld, an interactive framework for generating 4D worlds with environmental dynamics from a single image. While recent advances in 3D scene generation enable large-scale environment creation, most approaches focus primarily on reconstructing static geometry, leaving scene-scale environmental dynamics such as clouds, water, or smoke largely unexplored. Modeling such dynamics is challenging because motion must remain coherent across an expanding scene while supporting low-latency user feedback. LivingWorld addresses this challenge by progressively constructing a globally coherent motion field as the scene expands. To maintain global consistency during expansion, we introduce a geometry-aware alignment module that resolves directional and scale ambiguities across views. We further represent motion using a compact hash-based motion field, enabling efficient querying and stable propagation of dynamics throughout the scene. This representation also supports bidirectional motion propagation during rendering, producing long and temporally coherent 4D sequences without relying on expensive video-based refinement. On a single RTX 5090 GPU, generating each new scene expansion step requires 9 seconds, followed by 3 seconds for motion alignment and motion field updates, enabling interactive 4D world generation with globally coherent environmental dynamics. Video demonstrations are available at cvsp-lab.github.io/LivingWorld.
PIV3CAMS: a multi-camera dataset for multiple computer vision problems and its application to novel view-point synthesis
Jul 26, 2024
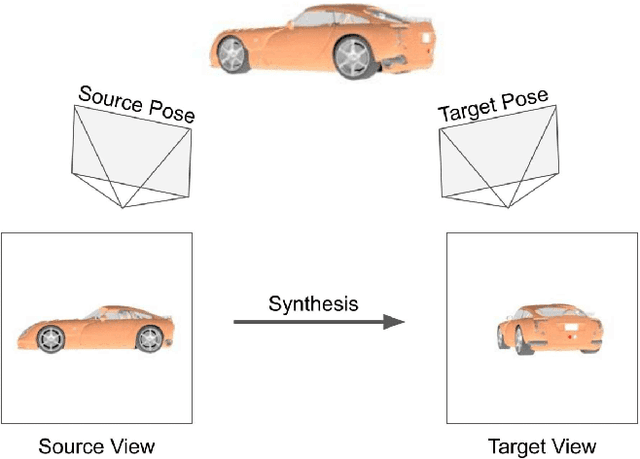


The modern approaches for computer vision tasks significantly rely on machine learning, which requires a large number of quality images. While there is a plethora of image datasets with a single type of images, there is a lack of datasets collected from multiple cameras. In this thesis, we introduce Paired Image and Video data from three CAMeraS, namely PIV3CAMS, aimed at multiple computer vision tasks. The PIV3CAMS dataset consists of 8385 pairs of images and 82 pairs of videos taken from three different cameras: Canon D5 Mark IV, Huawei P20, and ZED stereo camera. The dataset includes various indoor and outdoor scenes from different locations in Zurich (Switzerland) and Cheonan (South Korea). Some of the computer vision applications that can benefit from the PIV3CAMS dataset are image/video enhancement, view interpolation, image matching, and much more. We provide a careful explanation of the data collection process and detailed analysis of the data. The second part of this thesis studies the usage of depth information in the view synthesizing task. In addition to the regeneration of a current state-of-the-art algorithm, we investigate several proposed alternative models that integrate depth information geometrically. Through extensive experiments, we show that the effect of depth is crucial in small view changes. Finally, we apply our model to the introduced PIV3CAMS dataset to synthesize novel target views as an example application of PIV3CAMS.