 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightMBERT: A Simple Yet Effective Method for Multilingual BERT Distillation
Mar 11, 2021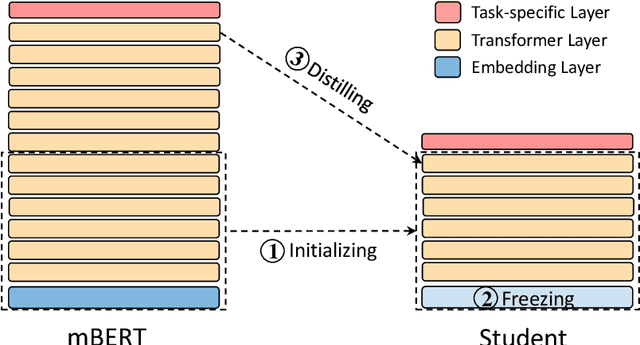
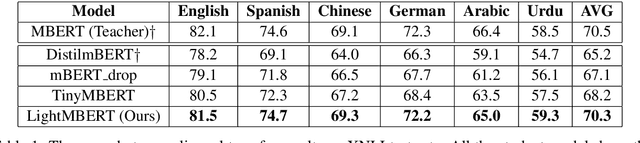
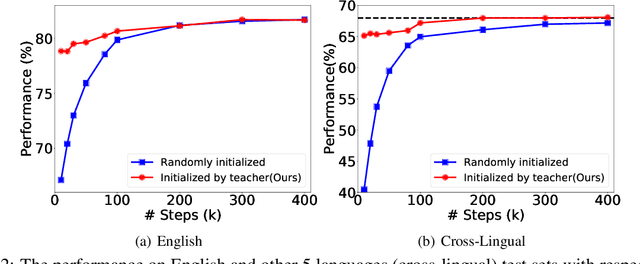

The multilingual pre-trained language models (e.g, mBERT, XLM and XLM-R) have shown impressive performance on cross-lingual natural language understanding tasks. However, these models are computationally intensive and difficult to be deployed on resource-restricted devices. In this paper, we propose a simple yet effective distillation method (LightMBERT) for transferring the cross-lingual generalization ability of the multilingual BERT to a small student model. The experiment results empirically demonstrate the efficiency and effectiveness of LightMBERT, which is significantly better than the baselines and performs comparable to the teacher mBERT.
Training Multilingual Pre-trained Language Model with Byte-level Subwords
Jan 23, 2021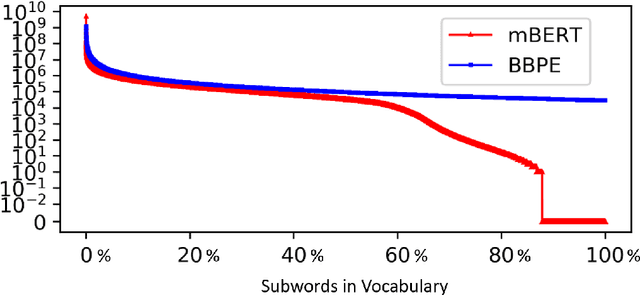
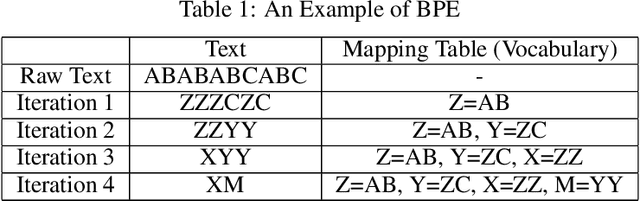

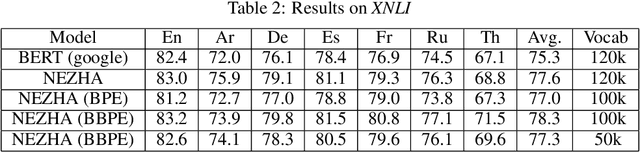
The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora. One of the fundamental components in pre-trained language models is the vocabulary, especially for training multilingual models on many different languages. In the technical report, we present our practices on training multilingual pre-trained language models with BBPE: Byte-Level BPE (i.e., Byte Pair Encoding). In the experiment, we adopted the architecture of NEZHA as the underlying pre-trained language model and the results show that NEZHA trained with byte-level subwords consistently outperforms Google multilingual BERT and vanilla NEZHA by a notable margin in several multilingual NLU tasks. We release the source code of our byte-level vocabulary building tools and the multilingual pre-trained language models.
Revisiting Robust Neural Machine Translation: A Transformer Case Study
Dec 31, 2020


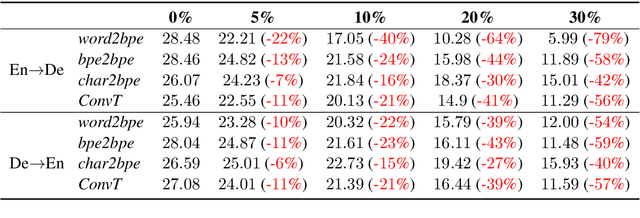
Transformers (Vaswani et al., 2017) have brought a remarkable improvement in the performance of neural machine translation (NMT) systems, but they could be surprisingly vulnerable to noise. Accordingly, we tried to investigate how noise breaks Transformers and if there exist solutions to deal with such issues. There is a large body of work in the NMT literature on analyzing the behaviour of conventional models for the problem of noise but it seems Transformers are understudied in this context. Therefore, we introduce a novel data-driven technique to incorporate noise during training. This idea is comparable to the well-known fine-tuning strategy. Moreover, we propose two new extensions to the original Transformer, that modify the neural architecture as well as the training process to handle noise. We evaluated our techniques to translate the English--German pair in both directions. Experimental results show that our models have a higher tolerance to noise. More specifically, they perform with no deterioration where up to 10% of entire test words are infected by noise.
BinaryBERT: Pushing the Limit of BERT Quantization
Dec 31, 2020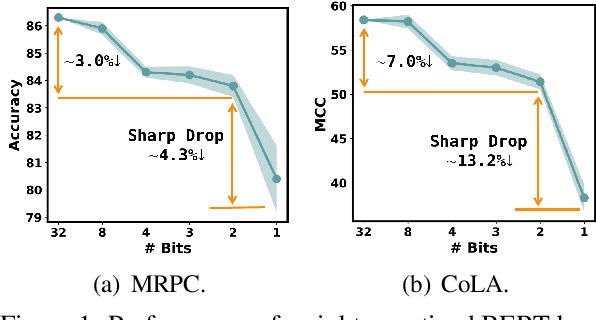
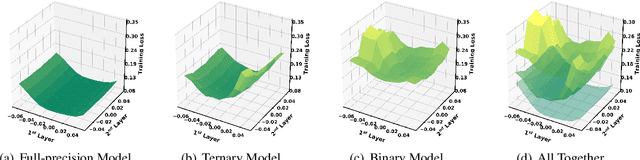
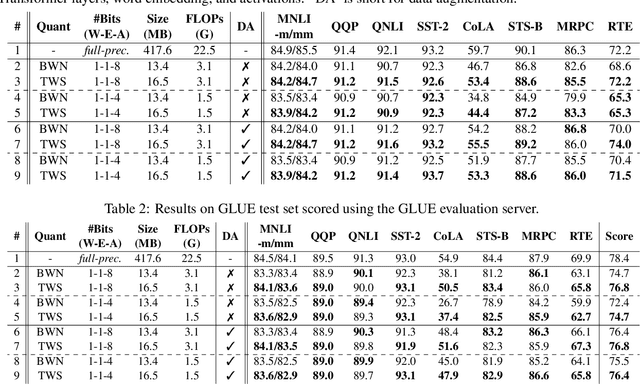
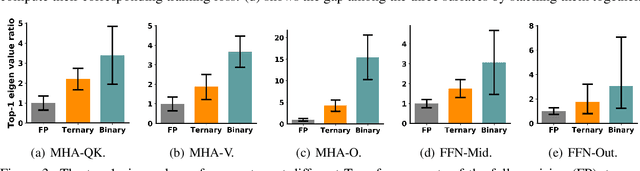
The rapid development of large pre-trained language models has greatly increased the demand for model compression techniques, among which quantization is a popular solution. In this paper, we propose BinaryBERT, which pushes BERT quantization to the limit with weight binarization. We find that a binary BERT is hard to be trained directly than a ternary counterpart due to its complex and irregular loss landscapes. Therefore, we propose ternary weight splitting, which initializes the binary model by equivalent splitting from a half-sized ternary network. The binary model thus inherits the good performance of the ternary model, and can be further enhanced by fine-tuning the new architecture after splitting. Empirical results show that BinaryBERT has negligible performance drop compared to the full-precision BERT-base while being $24\times$ smaller, achieving the state-of-the-art results on GLUE and SQuAD benchmarks.
Better Robustness by More Coverage: Adversarial Training with Mixup Augmentation for Robust Fine-tuning
Dec 31, 2020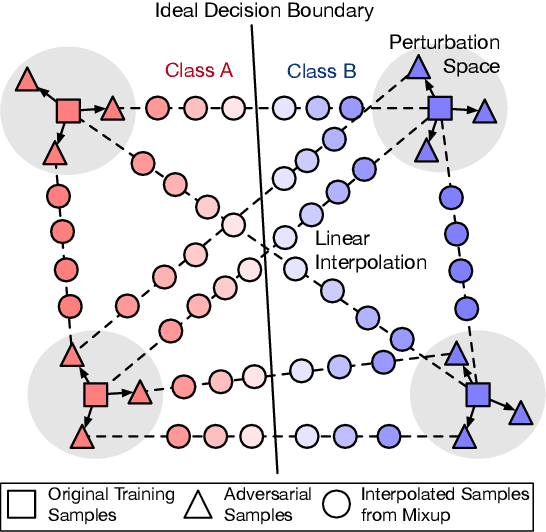
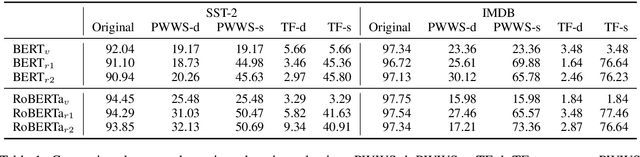
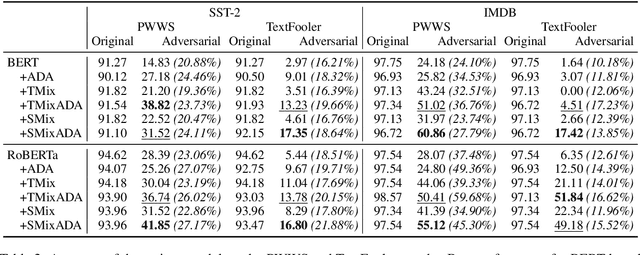
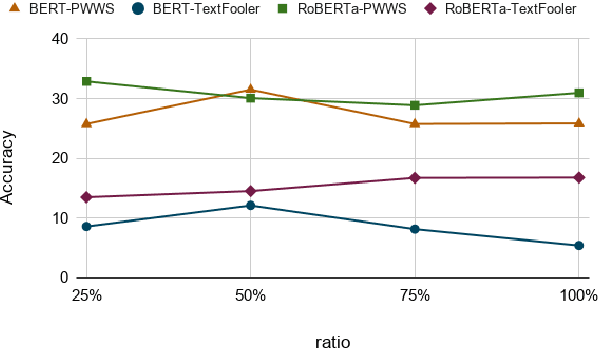
Pre-trained language models (PLMs) fail miserably on adversarial attacks. To improve the robustness, adversarial data augmentation (ADA) has been widely adopted, which attempts to cover more search space of adversarial attacks by adding the adversarial examples during training. However, the number of adversarial examples added by ADA is extremely insufficient due to the enormously large search space. In this work, we propose a simple and effective method to cover much larger proportion of the attack search space, called Adversarial Data Augmentation with Mixup (MixADA). Specifically, MixADA linearly interpolates the representations of pairs of training examples to form new virtual samples, which are more abundant and diverse than the discrete adversarial examples used in conventional ADA. Moreover, to evaluate the robustness of different models fairly, we adopt a challenging setup, which dynamically generates new adversarial examples for each model. In the text classification experiments of BERT and RoBERTa, MixADA achieves significant robustness gains under two strong adversarial attacks and alleviates the performance degradation of ADA on the original data. Our source codes will be released to support further explorations.
HopRetriever: Retrieve Hops over Wikipedia to Answer Complex Questions
Dec 31, 2020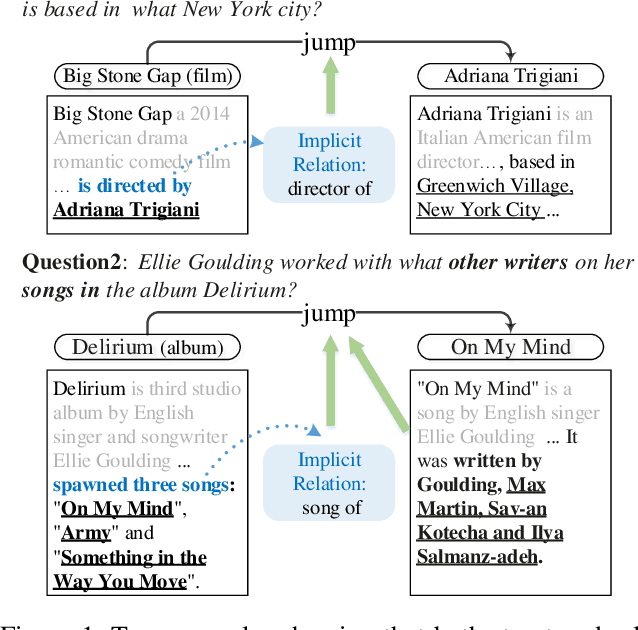

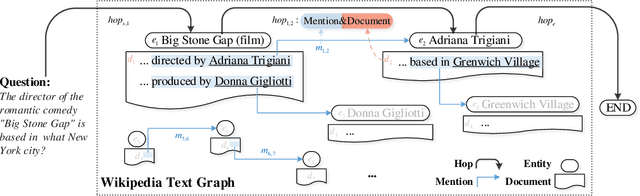

Collecting supporting evidence from large corpora of text (e.g., Wikipedia) is of great challenge for open-domain Question Answering (QA). Especially, for multi-hop open-domain QA, scattered evidence pieces are required to be gathered together to support the answer extraction. In this paper, we propose a new retrieval target, hop, to collect the hidden reasoning evidence from Wikipedia for complex question answering. Specifically, the hop in this paper is defined as the combination of a hyperlink and the corresponding outbound link document. The hyperlink is encoded as the mention embedding which models the structured knowledge of how the outbound link entity is mentioned in the textual context, and the corresponding outbound link document is encoded as the document embedding representing the unstructured knowledge within it. Accordingly, we build HopRetriever which retrieves hops over Wikipedia to answer complex questions. Experiments on the HotpotQA dataset demonstrate that HopRetriever outperforms previously published evidence retrieval methods by large margins. Moreover, our approach also yields quantifiable interpretations of the evidence collection process.
ALP-KD: Attention-Based Layer Projection for Knowledge Distillation
Dec 27, 2020
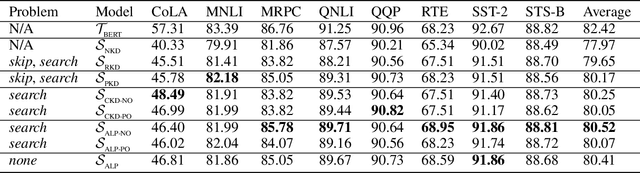
Knowledge distillation is considered as a training and compression strategy in which two neural networks, namely a teacher and a student, are coupled together during training. The teacher network is supposed to be a trustworthy predictor and the student tries to mimic its predictions. Usually, a student with a lighter architecture is selected so we can achieve compression and yet deliver high-quality results. In such a setting, distillation only happens for final predictions whereas the student could also benefit from teacher's supervision for internal components. Motivated by this, we studied the problem of distillation for intermediate layers. Since there might not be a one-to-one alignment between student and teacher layers, existing techniques skip some teacher layers and only distill from a subset of them. This shortcoming directly impacts quality, so we instead propose a combinatorial technique which relies on attention. Our model fuses teacher-side information and takes each layer's significance into consideration, then performs distillation between combined teacher layers and those of the student. Using our technique, we distilled a 12-layer BERT (Devlin et al. 2019) into 6-, 4-, and 2-layer counterparts and evaluated them on GLUE tasks (Wang et al. 2018). Experimental results show that our combinatorial approach is able to outperform other existing techniques.
Improving Task-Agnostic BERT Distillation with Layer Mapping Search
Dec 11, 2020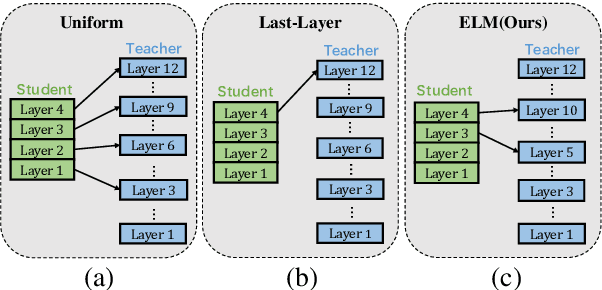

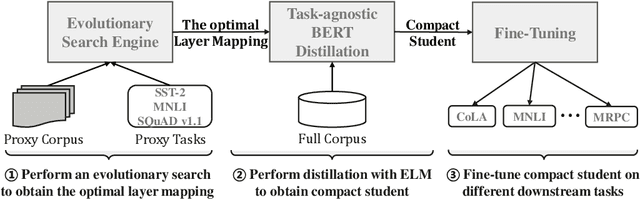
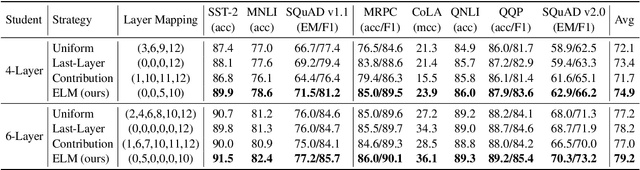
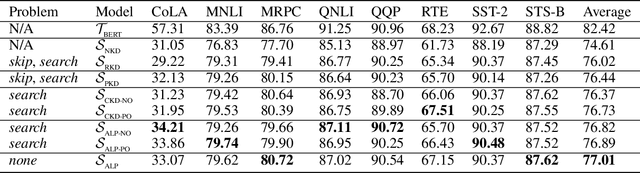
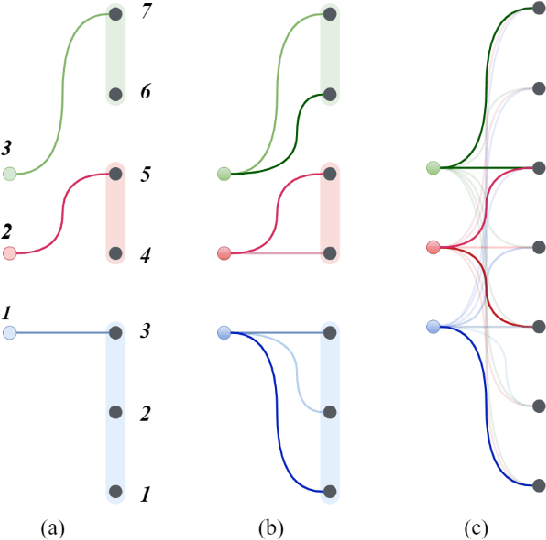
Knowledge distillation (KD) which transfers the knowledge from a large teacher model to a small student model, has been widely used to compress the BERT model recently. Besides the supervision in the output in the original KD, recent works show that layer-level supervision is crucial to the performance of the student BERT model. However, previous works designed the layer mapping strategy heuristically (e.g., uniform or last-layer), which can lead to inferior performance. In this paper, we propose to use the genetic algorithm (GA) to search for the optimal layer mapping automatically. To accelerate the search process, we further propose a proxy setting where a small portion of the training corpus are sampled for distillation, and three representative tasks are chosen for evaluation. After obtaining the optimal layer mapping, we perform the task-agnostic BERT distillation with it on the whole corpus to build a compact student model, which can be directly fine-tuned on downstream tasks. Comprehensive experiments on the evaluation benchmarks demonstrate that 1) layer mapping strategy has a significant effect on task-agnostic BERT distillation and different layer mappings can result in quite different performances; 2) the optimal layer mapping strategy from the proposed search process consistently outperforms the other heuristic ones; 3) with the optimal layer mapping, our student model achieves state-of-the-art performance on the GLUE tasks.
Document Graph for Neural Machine Translation
Dec 08, 2020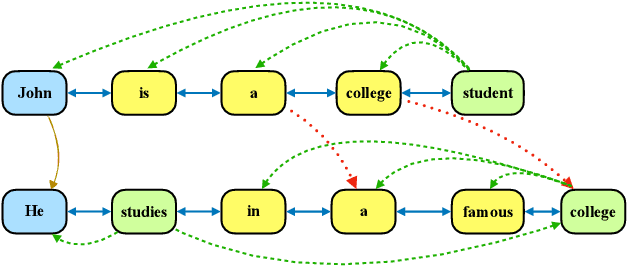
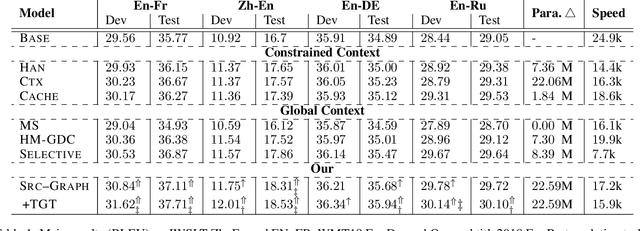
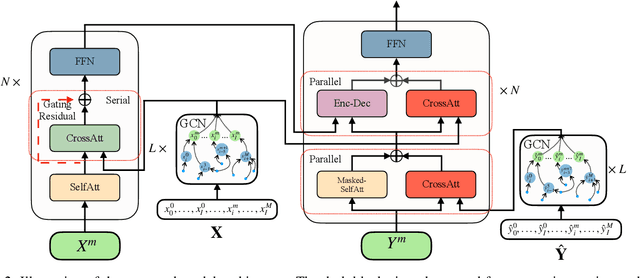
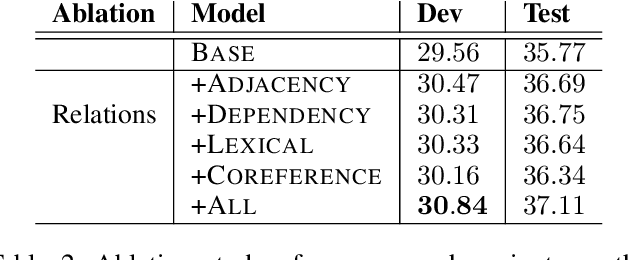
Previous works have shown that contextual information can improve the performance of neural machine translation (NMT). However, most existing document-level NMT methods failed to leverage contexts beyond a few set of previous sentences. How to make use of the whole document as global contexts is still a challenge. To address this issue, we hypothesize that a document can be represented as a graph that connects relevant contexts regardless of their distances. We employ several types of relations, including adjacency, syntactic dependency, lexical consistency, and coreference, to construct the document graph. Then, we incorporate both source and target graphs into the conventional Transformer architecture with graph convolutional networks. Experiments on various NMT benchmarks, including IWSLT English-French, Chinese-English, WMT English-German and Opensubtitle English-Russian, demonstrate that using document graphs can significantly improve the translation quality.
PPKE: Knowledge Representation Learning by Path-based Pre-training
Dec 07, 2020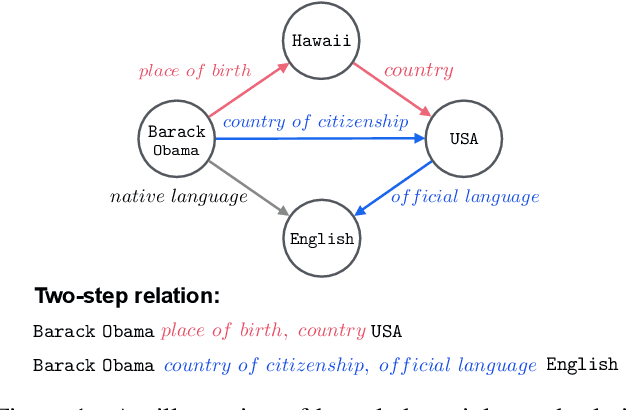

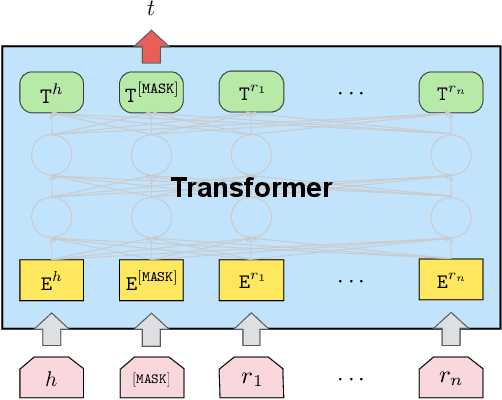
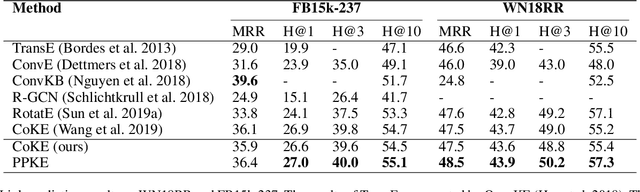
Entities may have complex interactions in a knowledge graph (KG), such as multi-step relationships, which can be viewed as graph contextual information of the entities. Traditional knowledge representation learning (KRL) methods usually treat a single triple as a training unit, and neglect most of the graph contextual information exists in the topological structure of KGs. In this study, we propose a Path-based Pre-training model to learn Knowledge Embeddings, called PPKE, which aims to integrate more graph contextual information between entities into the KRL model. Experiments demonstrate that our model achieves state-of-the-art results on several benchmark datasets for link prediction and relation prediction tasks, indicating that our model provides a feasible way to take advantage of graph contextual information in KGs.