 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Order Effect: Investigating Prompt Sensitivity in Closed-Source LLMs
Feb 06, 2025



As large language models (LLMs) become integral to diverse applications, ensuring their reliability under varying input conditions is crucial. One key issue affecting this reliability is order sensitivity, wherein slight variations in input arrangement can lead to inconsistent or biased outputs. Although recent advances have reduced this sensitivity, the problem remains unresolved. This paper investigates the extent of order sensitivity in closed-source LLMs by conducting experiments across multiple tasks, including paraphrasing, relevance judgment, and multiple-choice questions. Our results show that input order significantly affects performance across tasks, with shuffled inputs leading to measurable declines in output accuracy. Few-shot prompting demonstrates mixed effectiveness and offers partial mitigation, however, fails to fully resolve the problem. These findings highlight persistent risks, particularly in high-stakes applications, and point to the need for more robust LLMs or improved input-handling techniques in future development.
What is Lost in Knowledge Distillation?
Nov 07, 2023



Deep neural networks (DNNs) have improved NLP tasks significantly, but training and maintaining such networks could be costly. Model compression techniques, such as, knowledge distillation (KD), have been proposed to address the issue; however, the compression process could be lossy. Motivated by this, our work investigates how a distilled student model differs from its teacher, if the distillation process causes any information losses, and if the loss follows a specific pattern. Our experiments aim to shed light on the type of tasks might be less or more sensitive to KD by reporting data points on the contribution of different factors, such as the number of layers or attention heads. Results such as ours could be utilized when determining effective and efficient configurations to achieve optimal information transfers between larger (teacher) and smaller (student) models.
Training Mixed-Domain Translation Models via Federated Learning
May 03, 2022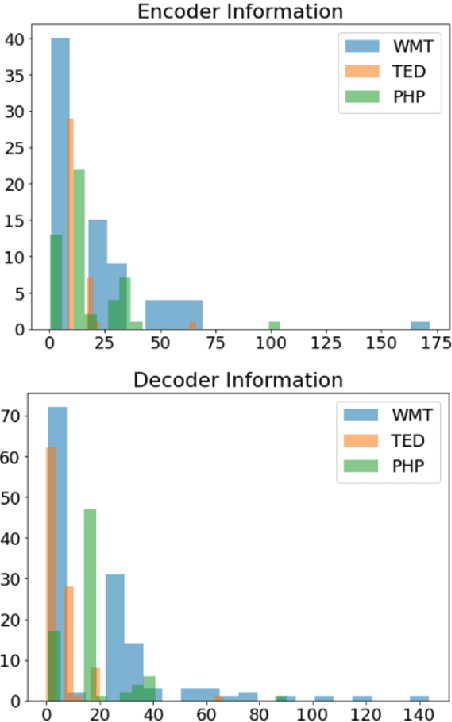
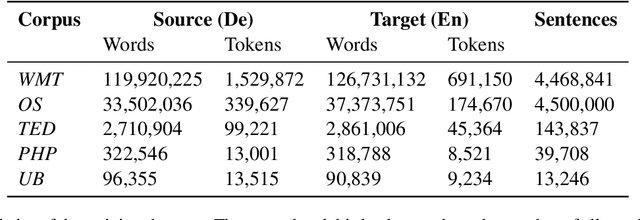
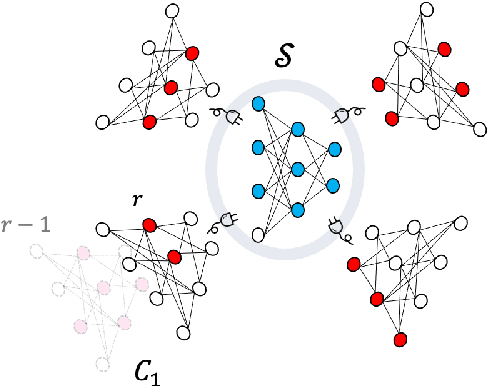
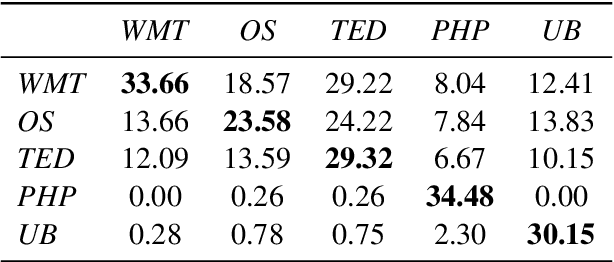
Training mixed-domain translation models is a complex task that demands tailored architectures and costly data preparation techniques. In this work, we leverage federated learning (FL) in order to tackle the problem. Our investigation demonstrates that with slight modifications in the training process, neural machine translation (NMT) engines can be easily adapted when an FL-based aggregation is applied to fuse different domains. Experimental results also show that engines built via FL are able to perform on par with state-of-the-art baselines that rely on centralized training techniques. We evaluate our hypothesis in the presence of five datasets with different sizes, from different domains, to translate from German into English and discuss how FL and NMT can mutually benefit from each other. In addition to providing benchmarking results on the union of FL and NMT, we also propose a novel technique to dynamically control the communication bandwidth by selecting impactful parameters during FL updates. This is a significant achievement considering the large size of NMT engines that need to be exchanged between FL parties.
Dynamic Position Encoding for Transformers
Apr 18, 2022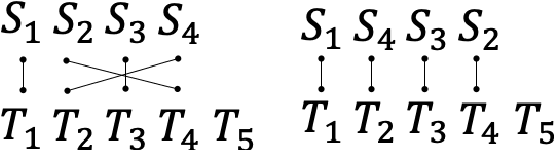
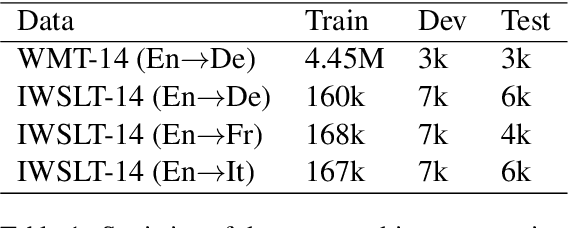
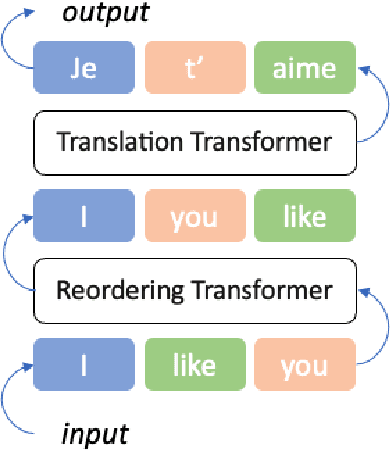

Recurrent models have been dominating the field of neural machine translation (NMT) for the past few years. Transformers \citep{vaswani2017attention}, have radically changed it by proposing a novel architecture that relies on a feed-forward backbone and self-attention mechanism. Although Transformers are powerful, they could fail to properly encode sequential/positional information due to their non-recurrent nature. To solve this problem, position embeddings are defined exclusively for each time step to enrich word information. However, such embeddings are fixed after training regardless of the task and the word ordering system of the source or target language. In this paper, we propose a novel architecture with new position embeddings depending on the input text to address this shortcoming by taking the order of target words into consideration. Instead of using predefined position embeddings, our solution \textit{generates} new embeddings to refine each word's position information. Since we do not dictate the position of source tokens and learn them in an end-to-end fashion, we refer to our method as \textit{dynamic} position encoding (DPE). We evaluated the impact of our model on multiple datasets to translate from English into German, French, and Italian and observed meaningful improvements in comparison to the original Transformer.
Communication-Efficient Federated Learning for Neural Machine Translation
Dec 12, 2021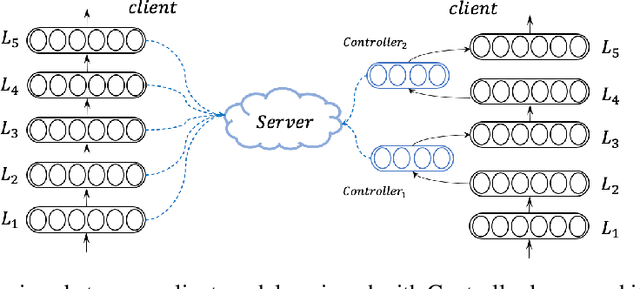
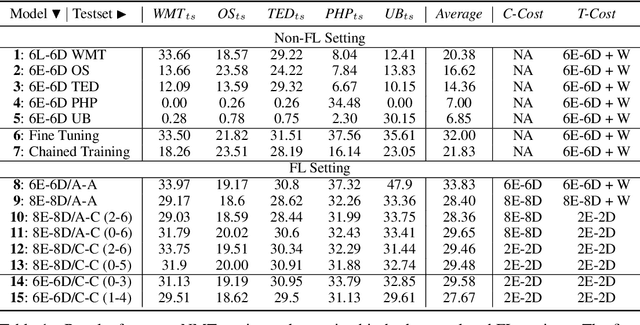
Training neural machine translation (NMT) models in federated learning (FL) settings could be inefficient both computationally and communication-wise, due to the large size of translation engines as well as the multiple rounds of updates required to train clients and a central server. In this paper, we explore how to efficiently build NMT models in an FL setup by proposing a novel solution. In order to reduce the communication overhead, out of all neural layers we only exchange what we term "Controller" layers. Controllers are a small number of additional neural components connected to our pre-trained architectures. These new components are placed in between original layers. They act as liaisons to communicate with the central server and learn minimal information that is sufficient enough to update clients. We evaluated the performance of our models on five datasets from different domains to translate from German into English. We noted that the models equipped with Controllers preform on par with those trained in a central and non-FL setting. In addition, we observed a substantial reduction in the communication traffic of the FL pipeline, which is a direct consequence of using Controllers. Based on our experiments, Controller-based models are ~6 times less expensive than their other peers. This reduction is significantly important when we consider the number of parameters in large models and it becomes even more critical when such parameters need to be exchanged for multiple rounds in FL settings.
Not Far Away, Not So Close: Sample Efficient Nearest Neighbour Data Augmentation via MiniMax
Jun 02, 2021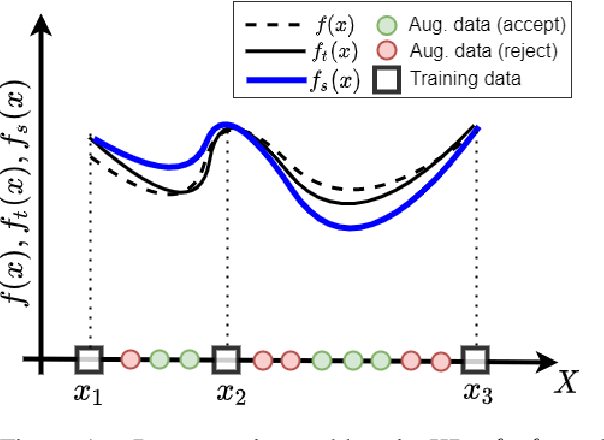
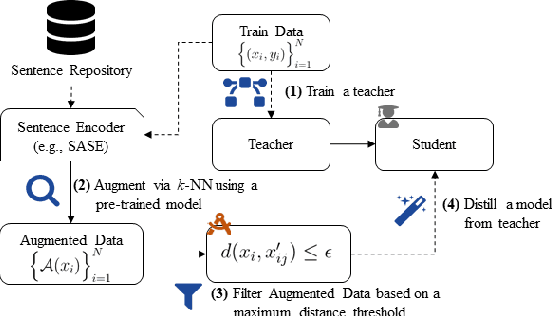

In Natural Language Processing (NLP), finding data augmentation techniques that can produce high-quality human-interpretable examples has always been challenging. Recently, leveraging kNN such that augmented examples are retrieved from large repositories of unlabelled sentences has made a step toward interpretable augmentation. Inspired by this paradigm, we introduce Minimax-kNN, a sample efficient data augmentation strategy tailored for Knowledge Distillation (KD). We exploit a semi-supervised approach based on KD to train a model on augmented data. In contrast to existing kNN augmentation techniques that blindly incorporate all samples, our method dynamically selects a subset of augmented samples that maximizes KL-divergence between the teacher and student models. This step aims to extract the most efficient samples to ensure our augmented data covers regions in the input space with maximum loss value. We evaluated our technique on several text classification tasks and demonstrated that Minimax-kNN consistently outperforms strong baselines. Our results show that Minimax-kNN requires fewer augmented examples and less computation to achieve superior performance over the state-of-the-art kNN-based augmentation techniques.
Robust Embeddings Via Distributions
Apr 17, 2021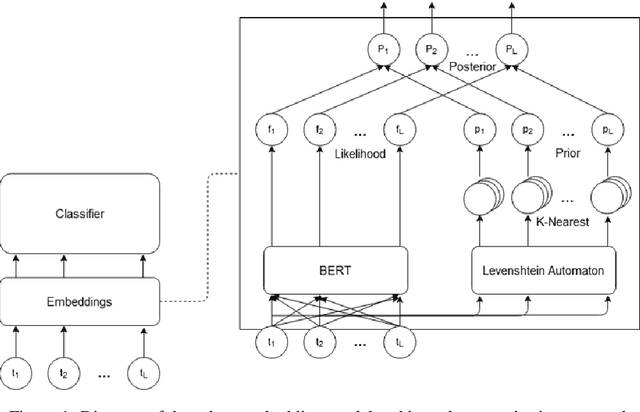
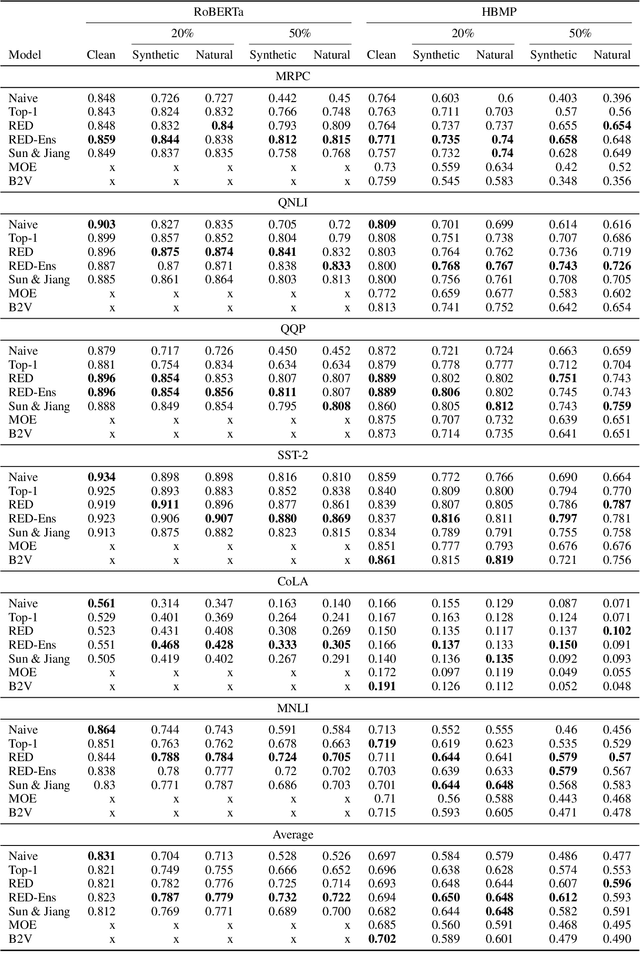
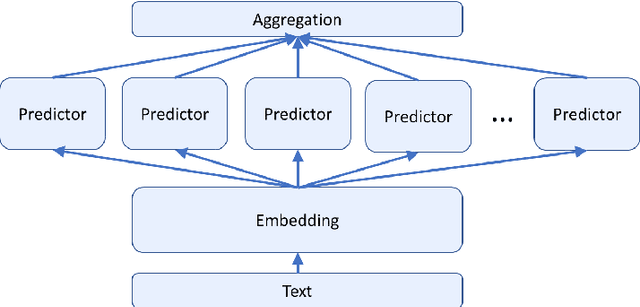

Despite recent monumental advances in the field, many Natural Language Processing (NLP) models still struggle to perform adequately on noisy domains. We propose a novel probabilistic embedding-level method to improve the robustness of NLP models. Our method, Robust Embeddings via Distributions (RED), incorporates information from both noisy tokens and surrounding context to obtain distributions over embedding vectors that can express uncertainty in semantic space more fully than any deterministic method. We evaluate our method on a number of downstream tasks using existing state-of-the-art models in the presence of both natural and synthetic noise, and demonstrate a clear improvement over other embedding approaches to robustness from the literature.
Revisiting Robust Neural Machine Translation: A Transformer Case Study
Dec 31, 2020


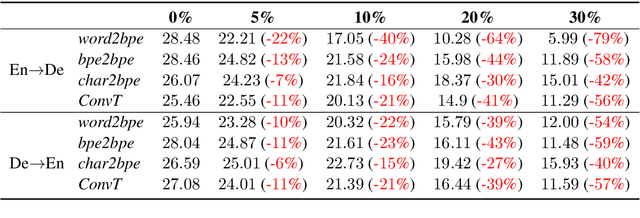
Transformers (Vaswani et al., 2017) have brought a remarkable improvement in the performance of neural machine translation (NMT) systems, but they could be surprisingly vulnerable to noise. Accordingly, we tried to investigate how noise breaks Transformers and if there exist solutions to deal with such issues. There is a large body of work in the NMT literature on analyzing the behaviour of conventional models for the problem of noise but it seems Transformers are understudied in this context. Therefore, we introduce a novel data-driven technique to incorporate noise during training. This idea is comparable to the well-known fine-tuning strategy. Moreover, we propose two new extensions to the original Transformer, that modify the neural architecture as well as the training process to handle noise. We evaluated our techniques to translate the English--German pair in both directions. Experimental results show that our models have a higher tolerance to noise. More specifically, they perform with no deterioration where up to 10% of entire test words are infected by noise.
ALP-KD: Attention-Based Layer Projection for Knowledge Distillation
Dec 27, 2020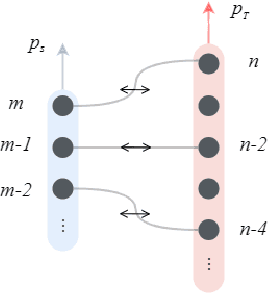
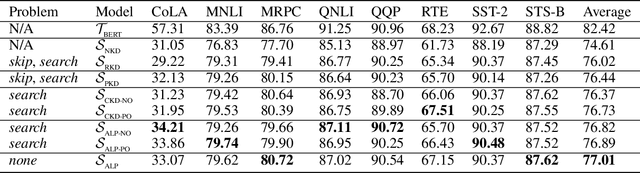
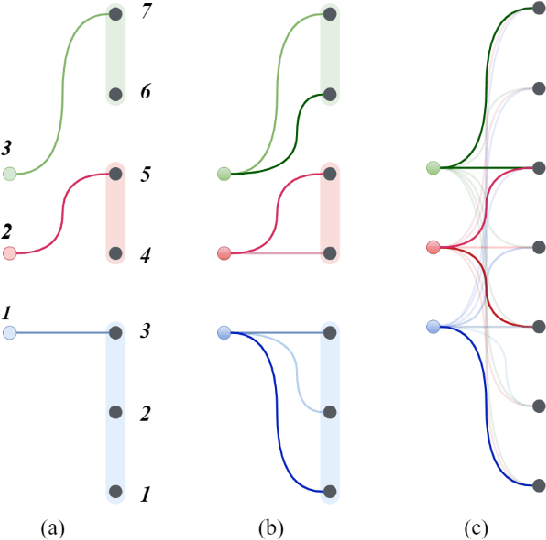
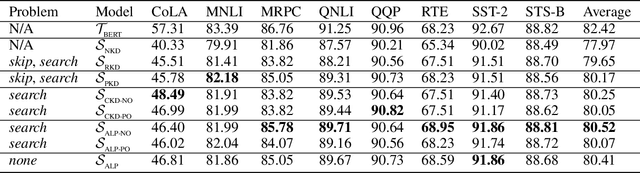
Knowledge distillation is considered as a training and compression strategy in which two neural networks, namely a teacher and a student, are coupled together during training. The teacher network is supposed to be a trustworthy predictor and the student tries to mimic its predictions. Usually, a student with a lighter architecture is selected so we can achieve compression and yet deliver high-quality results. In such a setting, distillation only happens for final predictions whereas the student could also benefit from teacher's supervision for internal components. Motivated by this, we studied the problem of distillation for intermediate layers. Since there might not be a one-to-one alignment between student and teacher layers, existing techniques skip some teacher layers and only distill from a subset of them. This shortcoming directly impacts quality, so we instead propose a combinatorial technique which relies on attention. Our model fuses teacher-side information and takes each layer's significance into consideration, then performs distillation between combined teacher layers and those of the student. Using our technique, we distilled a 12-layer BERT (Devlin et al. 2019) into 6-, 4-, and 2-layer counterparts and evaluated them on GLUE tasks (Wang et al. 2018). Experimental results show that our combinatorial approach is able to outperform other existing techniques.
Why Skip If You Can Combine: A Simple Knowledge Distillation Technique for Intermediate Layers
Oct 06, 2020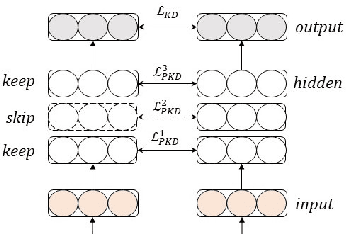
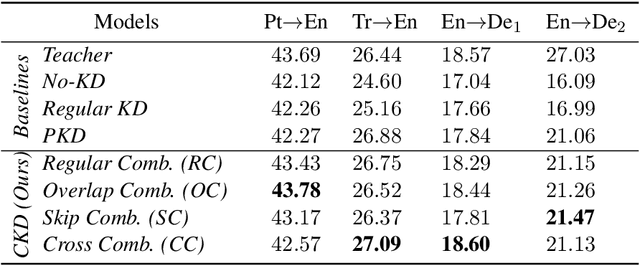
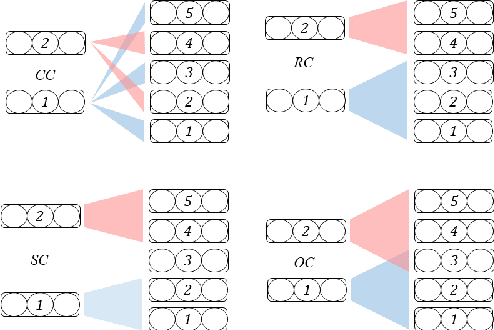
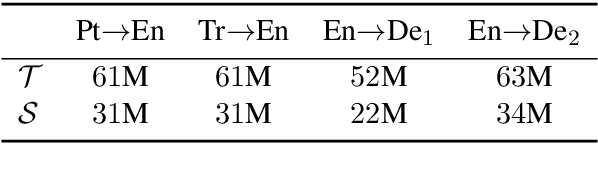
With the growth of computing power neural machine translation (NMT) models also grow accordingly and become better. However, they also become harder to deploy on edge devices due to memory constraints. To cope with this problem, a common practice is to distill knowledge from a large and accurately-trained teacher network (T) into a compact student network (S). Although knowledge distillation (KD) is useful in most cases, our study shows that existing KD techniques might not be suitable enough for deep NMT engines, so we propose a novel alternative. In our model, besides matching T and S predictions we have a combinatorial mechanism to inject layer-level supervision from T to S. In this paper, we target low-resource settings and evaluate our translation engines for Portuguese--English, Turkish--English, and English--German directions. Students trained using our technique have 50% fewer parameters and can still deliver comparable results to those of 12-layer teachers.