 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOGER: A Robust Offline-Guided Exploration Reward for Hybrid Reinforcement Learning
Apr 20, 2026Recent advancements in Reinforcement Learning with Verifiable Rewards (RLVR) have significantly improved Large Language Model (LLM) reasoning, yet models often struggle to explore novel trajectories beyond their initial latent space. While offline teacher guidance and entropy-driven strategies have been proposed to address this, they often lack deep integration or are constrained by the model's inherent capacity. In this paper, we propose OGER, a novel framework that unifies offline teacher guidance and online reinforcement learning through a specialized reward modeling lens. OGER employs multi-teacher collaborative training and constructs an auxiliary exploration reward that leverages both offline trajectories and the model's own entropy to incentivize autonomous exploration. Extensive experiments across mathematical and general reasoning benchmarks demonstrate that OGER significantly outperforms competitive baselines, achieving substantial gains in mathematical reasoning while maintaining robust generalization to out-of-domain tasks. We provide a comprehensive analysis of training dynamics and conduct detailed ablation studies to validate the effectiveness of our entropy-aware reward modulation. Our code is available at https://github.com/ecoli-hit/OGER.git.
A Survey on Zero Pronoun Translation
May 17, 2023



Zero pronouns (ZPs) are frequently omitted in pro-drop languages (e.g. Chinese, Hungarian, and Hindi), but should be recalled in non-pro-drop languages (e.g. English). This phenomenon has been studied extensively in machine translation (MT), as it poses a significant challenge for MT systems due to the difficulty in determining the correct antecedent for the pronoun. This survey paper highlights the major works that have been undertaken in zero pronoun translation (ZPT) after the neural revolution, so that researchers can recognise the current state and future directions of this field. We provide an organisation of the literature based on evolution, dataset, method and evaluation. In addition, we compare and analyze competing models and evaluation metrics on different benchmarks. We uncover a number of insightful findings such as: 1) ZPT is in line with the development trend of large language model; 2) data limitation causes learning bias in languages and domains; 3) performance improvements are often reported on single benchmarks, but advanced methods are still far from real-world use; 4) general-purpose metrics are not reliable on nuances and complexities of ZPT, emphasizing the necessity of targeted metrics; 5) apart from commonly-cited errors, ZPs will cause risks of gender bias.
Document Graph for Neural Machine Translation
Dec 08, 2020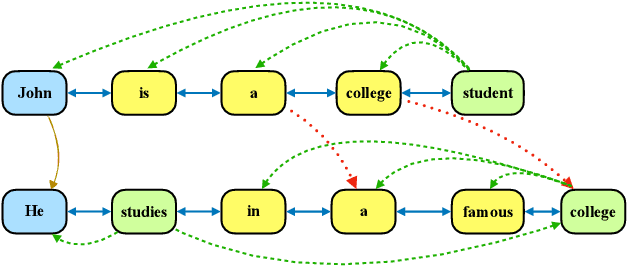
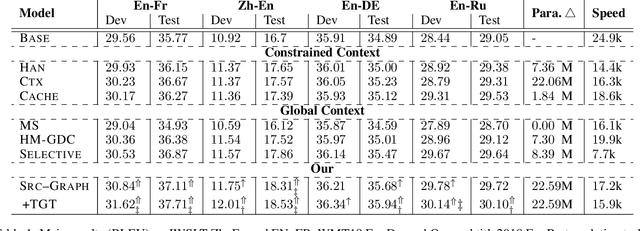
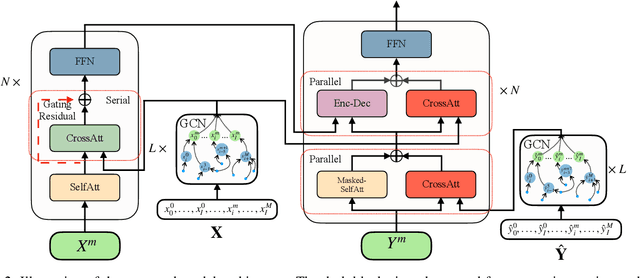
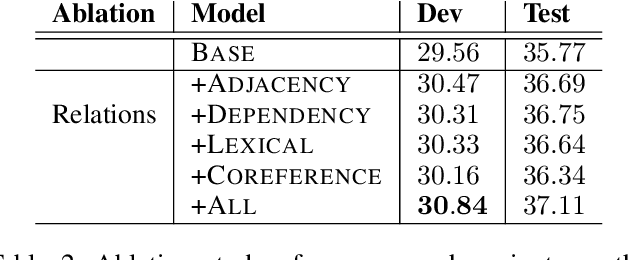
Previous works have shown that contextual information can improve the performance of neural machine translation (NMT). However, most existing document-level NMT methods failed to leverage contexts beyond a few set of previous sentences. How to make use of the whole document as global contexts is still a challenge. To address this issue, we hypothesize that a document can be represented as a graph that connects relevant contexts regardless of their distances. We employ several types of relations, including adjacency, syntactic dependency, lexical consistency, and coreference, to construct the document graph. Then, we incorporate both source and target graphs into the conventional Transformer architecture with graph convolutional networks. Experiments on various NMT benchmarks, including IWSLT English-French, Chinese-English, WMT English-German and Opensubtitle English-Russian, demonstrate that using document graphs can significantly improve the translation quality.