 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGN0: Toward a Unified Paradigm for Generation, Evaluation, and Policy Learning in Visual-Language Navigation
Jun 02, 2026Embodied navigation connects intelligent agents with the physical world and is fundamental for general robotic intelligence. Limited availability and quality of navigation data have constrained Vision-and-Language Navigation (VLN) systems' generalization and long-horizon capabilities. To address this, we curate diverse 3D scenes and develop an automated pipeline for large-scale navigation data, resulting in the GN-Matrix dataset. Building on a 3D Gaussian Splatting (3DGS) engine, we introduce a high-fidelity simulation platform supporting interactive roaming and collision-aware navigation. We further propose GN-Bench, the first BEV-based benchmark incorporating dynamic 3DGS avatars for human-robot interaction evaluation. To leverage the simulator, we develop an RL-driven navigation foundation model, Break and Establish (BAE). After supervised learning, DAgger exposes the model to rollout-induced states, breaking narrow expert-centric distributions and enabling downstream RL exploration. This unified VLN paradigm integrates map-based and map-free tasks, including instruction following, human following, and goal navigation. GN-BAE formalizes high-fidelity 3DGS-rendered Bird's Eye View representations as compact memory, unlocking latent spatial reasoning in VLMs. Extensive evaluations on GN-Bench and VLN-CE show that GN0 outperforms state-of-the-art VLN methods. Overall, GN-Matrix offers a unified framework spanning data, simulation, and learning, advancing embodied navigation in research and industrial applications.
Swift-SVD: Theoretical Optimality Meets Practical Efficiency in Low-Rank LLM Compression
Apr 02, 2026The deployment of Large Language Models is constrained by the memory and bandwidth demands of static weights and dynamic Key-Value cache. SVD-based compression provides a hardware-friendly solution to reduce these costs. However, existing methods suffer from two key limitations: some are suboptimal in reconstruction error, while others are theoretically optimal but practically inefficient. In this paper, we propose Swift-SVD, an activation-aware, closed-form compression framework that simultaneously guarantees theoretical optimum, practical efficiency and numerical stability. Swift-SVD incrementally aggregates covariance of output activations given a batch of inputs and performs a single eigenvalue decomposition after aggregation, enabling training-free, fast, and optimal layer-wise low-rank approximation. We employ effective rank to analyze local layer-wise compressibility and design a dynamic rank allocation strategy that jointly accounts for local reconstruction loss and end-to-end layer importance. Extensive experiments across six LLMs and eight datasets demonstrate that Swift-SVD outperforms state-of-the-art baselines, achieving optimal compression accuracy while delivering 3-70X speedups in end-to-end compression time. Our code will be released upon acceptance.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
TeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
Feb 07, 2026Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.
KV-CoRE: Benchmarking Data-Dependent Low-Rank Compressibility of KV-Caches in LLMs
Feb 05, 2026Large language models rely on kv-caches to avoid redundant computation during autoregressive decoding, but as context length grows, reading and writing the cache can quickly saturate GPU memory bandwidth. Recent work has explored KV-cache compression, yet most approaches neglect the data-dependent nature of kv-caches and their variation across layers. We introduce KV-CoRE KV-cache Compressibility by Rank Evaluation), an SVD-based method for quantifying the data-dependent low-rank compressibility of kv-caches. KV-CoRE computes the optimal low-rank approximation under the Frobenius norm and, being gradient-free and incremental, enables efficient dataset-level, layer-wise evaluation. Using this method, we analyze multiple models and datasets spanning five English domains and sixteen languages, uncovering systematic patterns that link compressibility to model architecture, training data, and language coverage. As part of this analysis, we employ the Normalized Effective Rank as a metric of compressibility and show that it correlates strongly with performance degradation under compression. Our study establishes a principled evaluation framework and the first large-scale benchmark of kv-cache compressibility in LLMs, offering insights for dynamic, data-aware compression and data-centric model development.
VeRPO: Verifiable Dense Reward Policy Optimization for Code Generation
Jan 07, 2026Effective reward design is a central challenge in Reinforcement Learning (RL) for code generation. Mainstream pass/fail outcome rewards enforce functional correctness via executing unit tests, but the resulting sparsity limits potential performance gains. While recent work has explored external Reward Models (RM) to generate richer, continuous rewards, the learned RMs suffer from reward misalignment and prohibitive computational cost. In this paper, we introduce \textbf{VeRPO} (\textbf{V}erifiable D\textbf{e}nse \textbf{R}eward \textbf{P}olicy \textbf{O}ptimization), a novel RL framework for code generation that synthesizes \textit{robust and dense rewards fully grounded in verifiable execution feedback}. The core idea of VeRPO is constructing dense rewards from weighted partial success: by dynamically estimating the difficulty weight of each unit test based on the execution statistics during training, a dense reward is derived from the sum of weights of the passed unit tests. To solidify the consistency between partial success and end-to-end functional correctness, VeRPO further integrates the dense signal with global execution outcomes, establishing a robust and dense reward paradigm relying solely on verifiable execution feedback. Extensive experiments across diverse benchmarks and settings demonstrate that VeRPO consistently outperforms outcome-driven and RM-based baselines, achieving up to +8.83\% gain in pass@1 with negligible time cost (< 0.02\%) and zero GPU memory overhead.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Efficient Unified Caching for Accelerating Heterogeneous AI Workloads
Jun 14, 2025Modern AI clusters, which host diverse workloads like data pre-processing, training and inference, often store the large-volume data in cloud storage and employ caching frameworks to facilitate remote data access. To avoid code-intrusion complexity and minimize cache space wastage, it is desirable to maintain a unified cache shared by all the workloads. However, existing cache management strategies, designed for specific workloads, struggle to handle the heterogeneous AI workloads in a cluster -- which usually exhibit heterogeneous access patterns and item storage granularities. In this paper, we propose IGTCache, a unified, high-efficacy cache for modern AI clusters. IGTCache leverages a hierarchical access abstraction, AccessStreamTree, to organize the recent data accesses in a tree structure, facilitating access pattern detection at various granularities. Using this abstraction, IGTCache applies hypothesis testing to categorize data access patterns as sequential, random, or skewed. Based on these detected access patterns and granularities, IGTCache tailors optimal cache management strategies including prefetching, eviction, and space allocation accordingly. Experimental results show that IGTCache increases the cache hit ratio by 55.6% over state-of-the-art caching frameworks, reducing the overall job completion time by 52.2%.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Fast Distributed Deep Learning via Worker-adaptive Batch Sizing
Jun 07, 2018
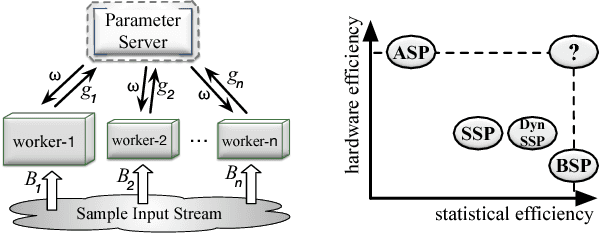
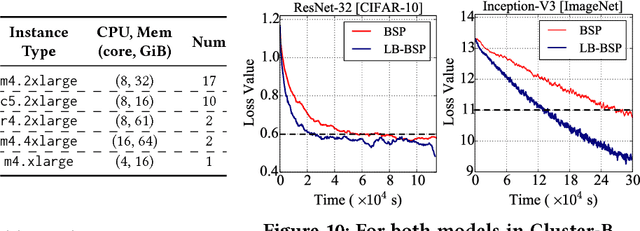
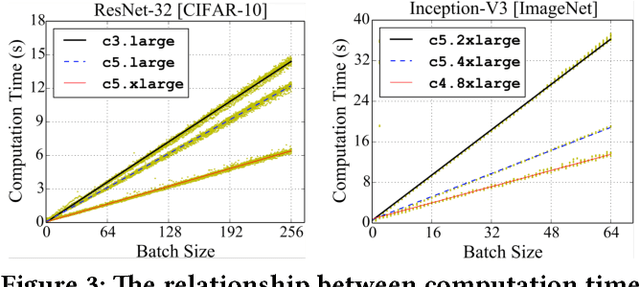
Deep neural network models are usually trained in cluster environments, where the model parameters are iteratively refined by multiple worker machines in parallel. One key challenge in this regard is the presence of stragglers, which significantly degrades the learning performance. In this paper, we propose to eliminate stragglers by adapting each worker's training load to its processing capability; that is, slower workers receive a smaller batch of data to process. Following this idea, we develop a new synchronization scheme called LB-BSP (Load-balanced BSP). It works by coordinately setting the batch size of each worker so that they can finish batch processing at around the same time. A prerequisite for deciding the workers' batch sizes is to know their processing speeds before each iteration starts. For the best prediction accuracy, we adopt NARX, an extended recurrent neural network that accounts for both the historical speeds and the driving factors such as CPU and memory in prediction. We have implemented LB-BSP for both TensorFlow and MXNet. EC2 experiments against popular benchmarks show that LB-BSP can effectively accelerate the training of deep models, with up to 2x speedup.