 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
Feb 07, 2026Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.
Dual-Arm Hierarchical Planning for Laboratory Automation: Vibratory Sieve Shaker Operations
Sep 18, 2025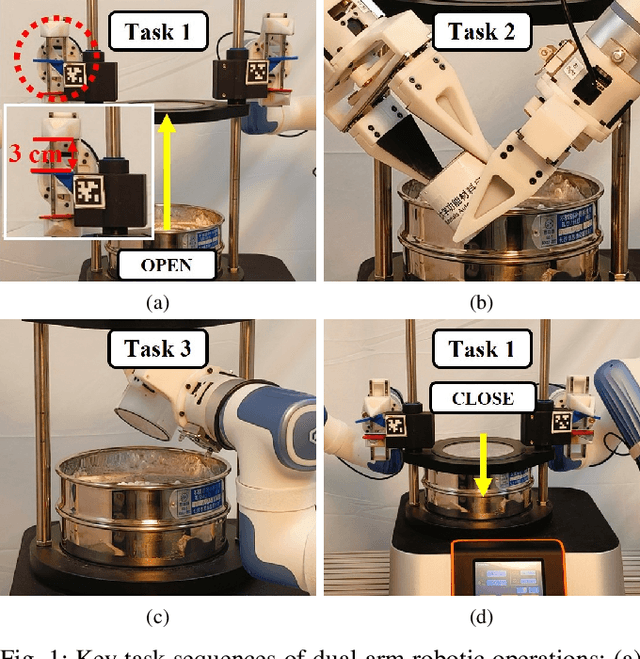
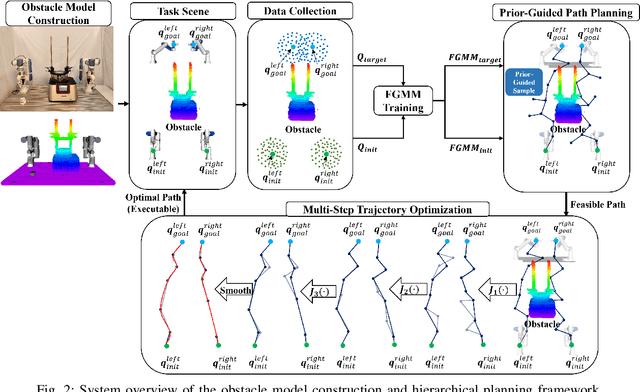
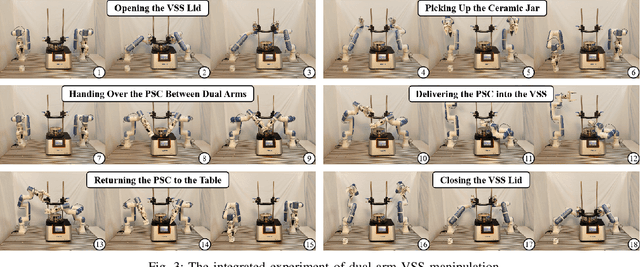
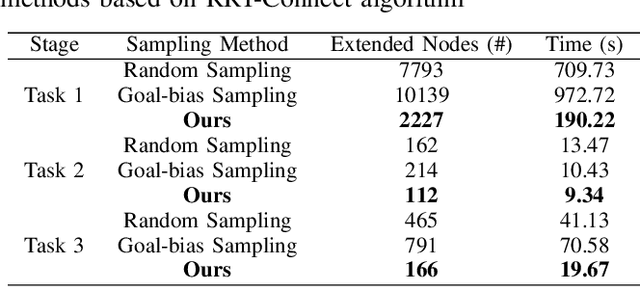
This paper addresses the challenges of automating vibratory sieve shaker operations in a materials laboratory, focusing on three critical tasks: 1) dual-arm lid manipulation in 3 cm clearance spaces, 2) bimanual handover in overlapping workspaces, and 3) obstructed powder sample container delivery with orientation constraints. These tasks present significant challenges, including inefficient sampling in narrow passages, the need for smooth trajectories to prevent spillage, and suboptimal paths generated by conventional methods. To overcome these challenges, we propose a hierarchical planning framework combining Prior-Guided Path Planning and Multi-Step Trajectory Optimization. The former uses a finite Gaussian mixture model to improve sampling efficiency in narrow passages, while the latter refines paths by shortening, simplifying, imposing joint constraints, and B-spline smoothing. Experimental results demonstrate the framework's effectiveness: planning time is reduced by up to 80.4%, and waypoints are decreased by 89.4%. Furthermore, the system completes the full vibratory sieve shaker operation workflow in a physical experiment, validating its practical applicability for complex laboratory automation.
FREAK: Frequency-modulated High-fidelity and Real-time Audio-driven Talking Portrait Synthesis
Mar 06, 2025Achieving high-fidelity lip-speech synchronization in audio-driven talking portrait synthesis remains challenging. While multi-stage pipelines or diffusion models yield high-quality results, they suffer from high computational costs. Some approaches perform well on specific individuals with low resources, yet still exhibit mismatched lip movements. The aforementioned methods are modeled in the pixel domain. We observed that there are noticeable discrepancies in the frequency domain between the synthesized talking videos and natural videos. Currently, no research on talking portrait synthesis has considered this aspect. To address this, we propose a FREquency-modulated, high-fidelity, and real-time Audio-driven talKing portrait synthesis framework, named FREAK, which models talking portraits from the frequency domain perspective, enhancing the fidelity and naturalness of the synthesized portraits. FREAK introduces two novel frequency-based modules: 1) the Visual Encoding Frequency Modulator (VEFM) to couple multi-scale visual features in the frequency domain, better preserving visual frequency information and reducing the gap in the frequency spectrum between synthesized and natural frames. and 2) the Audio Visual Frequency Modulator (AVFM) to help the model learn the talking pattern in the frequency domain and improve audio-visual synchronization. Additionally, we optimize the model in both pixel domain and frequency domain jointly. Furthermore, FREAK supports seamless switching between one-shot and video dubbing settings, offering enhanced flexibility. Due to its superior performance, it can simultaneously support high-resolution video results and real-time inference. Extensive experiments demonstrate that our method synthesizes high-fidelity talking portraits with detailed facial textures and precise lip synchronization in real-time, outperforming state-of-the-art methods.
MatPilot: an LLM-enabled AI Materials Scientist under the Framework of Human-Machine Collaboration
Nov 10, 2024The rapid evolution of artificial intelligence, particularly large language models, presents unprecedented opportunities for materials science research. We proposed and developed an AI materials scientist named MatPilot, which has shown encouraging abilities in the discovery of new materials. The core strength of MatPilot is its natural language interactive human-machine collaboration, which augments the research capabilities of human scientist teams through a multi-agent system. MatPilot integrates unique cognitive abilities, extensive accumulated experience, and ongoing curiosity of human-beings with the AI agents' capabilities of advanced abstraction, complex knowledge storage and high-dimensional information processing. It could generate scientific hypotheses and experimental schemes, and employ predictive models and optimization algorithms to drive an automated experimental platform for experiments. It turns out that our system demonstrates capabilities for efficient validation, continuous learning, and iterative optimization.