 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Frequency-Aware Network for Laparoscopic Image Desmoking
Dec 19, 2023



Laparoscopic surgery offers minimally invasive procedures with better patient outcomes, but smoke presence challenges visibility and safety. Existing learning-based methods demand large datasets and high computational resources. We propose the Progressive Frequency-Aware Network (PFAN), a lightweight GAN framework for laparoscopic image desmoking, combining the strengths of CNN and Transformer for progressive information extraction in the frequency domain. PFAN features CNN-based Multi-scale Bottleneck-Inverting (MBI) Blocks for capturing local high-frequency information and Locally-Enhanced Axial Attention Transformers (LAT) for efficiently handling global low-frequency information. PFAN efficiently desmokes laparoscopic images even with limited training data. Our method outperforms state-of-the-art approaches in PSNR, SSIM, CIEDE2000, and visual quality on the Cholec80 dataset and retains only 629K parameters. Our code and models are made publicly available at: https://github.com/jlzcode/PFAN.
Shifting More Attention to Breast Lesion Segmentation in Ultrasound Videos
Oct 03, 2023Breast lesion segmentation in ultrasound (US) videos is essential for diagnosing and treating axillary lymph node metastasis. However, the lack of a well-established and large-scale ultrasound video dataset with high-quality annotations has posed a persistent challenge for the research community. To overcome this issue, we meticulously curated a US video breast lesion segmentation dataset comprising 572 videos and 34,300 annotated frames, covering a wide range of realistic clinical scenarios. Furthermore, we propose a novel frequency and localization feature aggregation network (FLA-Net) that learns temporal features from the frequency domain and predicts additional lesion location positions to assist with breast lesion segmentation. We also devise a localization-based contrastive loss to reduce the lesion location distance between neighboring video frames within the same video and enlarge the location distances between frames from different ultrasound videos. Our experiments on our annotated dataset and two public video polyp segmentation datasets demonstrate that our proposed FLA-Net achieves state-of-the-art performance in breast lesion segmentation in US videos and video polyp segmentation while significantly reducing time and space complexity. Our model and dataset are available at https://github.com/jhl-Det/FLA-Net.
Distribution-Aware Calibration for Object Detection with Noisy Bounding Boxes
Aug 23, 2023Large-scale well-annotated datasets are of great importance for training an effective object detector. However, obtaining accurate bounding box annotations is laborious and demanding. Unfortunately, the resultant noisy bounding boxes could cause corrupt supervision signals and thus diminish detection performance. Motivated by the observation that the real ground-truth is usually situated in the aggregation region of the proposals assigned to a noisy ground-truth, we propose DIStribution-aware CalibratiOn (DISCO) to model the spatial distribution of proposals for calibrating supervision signals. In DISCO, spatial distribution modeling is performed to statistically extract the potential locations of objects. Based on the modeled distribution, three distribution-aware techniques, i.e., distribution-aware proposal augmentation (DA-Aug), distribution-aware box refinement (DA-Ref), and distribution-aware confidence estimation (DA-Est), are developed to improve classification, localization, and interpretability, respectively. Extensive experiments on large-scale noisy image datasets (i.e., Pascal VOC and MS-COCO) demonstrate that DISCO can achieve state-of-the-art detection performance, especially at high noise levels.
Semi-Supervised Semantic Segmentation With Region Relevance
Apr 23, 2023Semi-supervised semantic segmentation aims to learn from a small amount of labeled data and plenty of unlabeled ones for the segmentation task. The most common approach is to generate pseudo-labels for unlabeled images to augment the training data. However, the noisy pseudo-labels will lead to cumulative classification errors and aggravate the local inconsistency in prediction. This paper proposes a Region Relevance Network (RRN) to alleviate the problem mentioned above. Specifically, we first introduce a local pseudo-label filtering module that leverages discriminator networks to assess the accuracy of the pseudo-label at the region level. A local selection loss is proposed to mitigate the negative impact of wrong pseudo-labels in consistency regularization training. In addition, we propose a dynamic region-loss correction module, which takes the merit of network diversity to further rate the reliability of pseudo-labels and correct the convergence direction of the segmentation network with a dynamic region loss. Extensive experiments are conducted on PASCAL VOC 2012 and Cityscapes datasets with varying amounts of labeled data, demonstrating that our proposed approach achieves state-of-the-art performance compared to current counterparts.
Learning Agreement from Multi-source Annotations for Medical Image Segmentation
Apr 02, 2023



In medical image analysis, it is typical to merge multiple independent annotations as ground truth to mitigate the bias caused by individual annotation preference. However, arbitrating the final annotation is not always effective because new biases might be produced during the process, especially when there are significant variations among annotations. This paper proposes a novel Uncertainty-guided Multi-source Annotation Network (UMA-Net) to learn medical image segmentation directly from multiple annotations. UMA-Net consists of a UNet with two quality-specific predictors, an Annotation Uncertainty Estimation Module (AUEM) and a Quality Assessment Module (QAM). Specifically, AUEM estimates pixel-wise uncertainty maps of each annotation and encourages them to reach an agreement on reliable pixels/voxels. The uncertainty maps then guide the UNet to learn from the reliable pixels/voxels by weighting the segmentation loss. QAM grades the uncertainty maps into high-quality or low-quality groups based on assessment scores. The UNet is further implemented to contain a high-quality learning head (H-head) and a low-quality learning head (L-head). H-head purely learns with high-quality uncertainty maps to avoid error accumulation and keeps strong prediction ability, while L-head leverages the low-quality uncertainty maps to assist the backbone to learn maximum representation knowledge. UNet with H-head will be reserved during the inference stage, and the rest of the modules can be removed freely for computational efficiency. We conduct extensive experiments on an unsupervised 3D segmentation task and a supervised 2D segmentation task, respectively. The results show that our proposed UMA-Net outperforms state-of-the-art approaches, demonstrating its generality and effectiveness.
Masked Image Training for Generalizable Deep Image Denoising
Mar 23, 2023



When capturing and storing images, devices inevitably introduce noise. Reducing this noise is a critical task called image denoising. Deep learning has become the de facto method for image denoising, especially with the emergence of Transformer-based models that have achieved notable state-of-the-art results on various image tasks. However, deep learning-based methods often suffer from a lack of generalization ability. For example, deep models trained on Gaussian noise may perform poorly when tested on other noise distributions. To address this issue, we present a novel approach to enhance the generalization performance of denoising networks, known as masked training. Our method involves masking random pixels of the input image and reconstructing the missing information during training. We also mask out the features in the self-attention layers to avoid the impact of training-testing inconsistency. Our approach exhibits better generalization ability than other deep learning models and is directly applicable to real-world scenarios. Additionally, our interpretability analysis demonstrates the superiority of our method.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023



Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
RepMode: Learning to Re-parameterize Diverse Experts for Subcellular Structure Prediction
Dec 20, 2022



In subcellular biological research, fluorescence staining is a key technique to reveal the locations and morphology of subcellular structures. However, fluorescence staining is slow, expensive, and harmful to cells. In this paper, we treat it as a deep learning task termed subcellular structure prediction (SSP), aiming to predict the 3D fluorescent images of multiple subcellular structures from a 3D transmitted-light image. Unfortunately, due to the limitations of current biotechnology, each image is partially labeled in SSP. Besides, naturally, the subcellular structures vary considerably in size, which causes the multi-scale issue in SSP. However, traditional solutions can not address SSP well since they organize network parameters inefficiently and inflexibly. To overcome these challenges, we propose Re-parameterizing Mixture-of-Diverse-Experts (RepMode), a network that dynamically organizes its parameters with task-aware priors to handle specified single-label prediction tasks of SSP. In RepMode, the Mixture-of-Diverse-Experts (MoDE) block is designed to learn the generalized parameters for all tasks, and gating re-parameterization (GatRep) is performed to generate the specialized parameters for each task, by which RepMode can maintain a compact practical topology exactly like a plain network, and meanwhile achieves a powerful theoretical topology. Comprehensive experiments show that RepMode outperforms existing methods on ten of twelve prediction tasks of SSP and achieves state-of-the-art overall performance.
Channel-Aware Ordered Successive Relaying with Finite-Blocklength Coding
Oct 26, 2022



Successive relaying can improve the transmission rate by allowing the source and relays to transmit messages simultaneously, but it may cause severe inter-relay interference (IRI). IRI cancellation schemes have been proposed to mitigate IRI. However, interference cancellation methods have a high risk of error propagation, resulting in a severe transmission rate loss in finite blocklength regimes. Thus, jointly decoding for successive relaying with finite-blocklength coding (FBC) remains a challenge. In this paper, we present an optimized channel-aware ordered successive relaying protocol with finite-blocklength coding (CAO-SIR-FBC), which can recover the rate loss by carefully adapting the relay transmission order and rate. We analyze the average throughput of the CAO-SIR-FBC method, based on which a closed-form expression in a high signal-to-noise regime (SNR) is presented. Average throughput analysis and simulations show that CAO-SIR-FBC outperforms conventional two-timeslot half-duplex relaying in terms of spectral efficiency.
Intra-Modal Constraint Loss For Image-Text Retrieval
Jul 13, 2022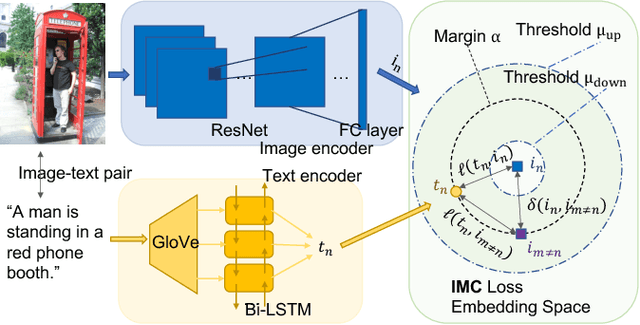
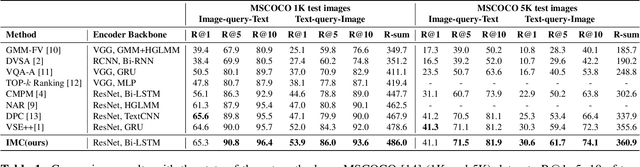
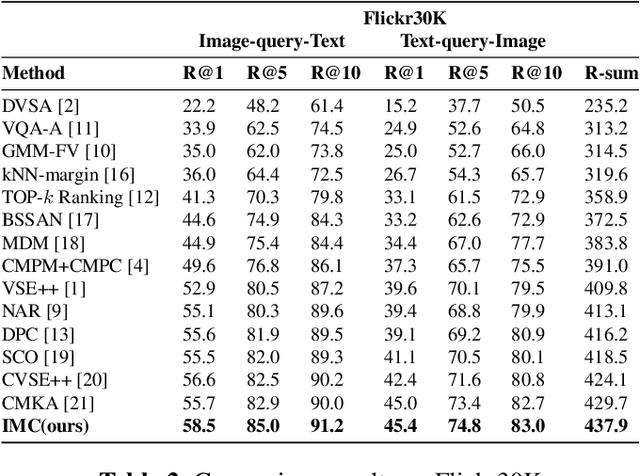
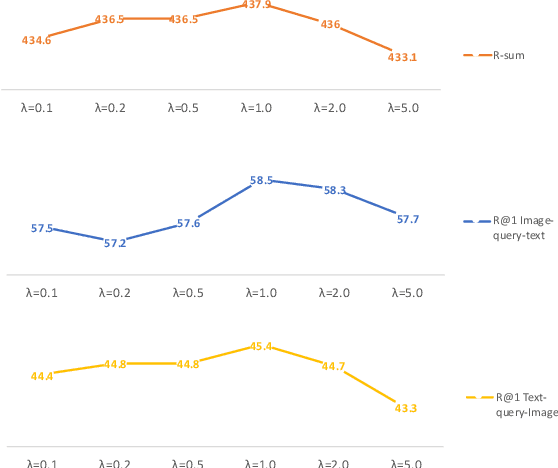
Cross-modal retrieval has drawn much attention in both computer vision and natural language processing domains. With the development of convolutional and recurrent neural networks, the bottleneck of retrieval across image-text modalities is no longer the extraction of image and text features but an efficient loss function learning in embedding space. Many loss functions try to closer pairwise features from heterogeneous modalities. This paper proposes a method for learning joint embedding of images and texts using an intra-modal constraint loss function to reduce the violation of negative pairs from the same homogeneous modality. Experimental results show that our approach outperforms state-of-the-art bi-directional image-text retrieval methods on Flickr30K and Microsoft COCO datasets. Our code is publicly available: https://github.com/CanonChen/IMC.