 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUVOD: A Novel Multi-view Video Object Segmentation Dataset and A Benchmark for 3D Segmentation
Jul 10, 2025The application of methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3D GS) have steadily gained popularity in the field of 3D object segmentation in static scenes. These approaches demonstrate efficacy in a range of 3D scene understanding and editing tasks. Nevertheless, the 4D object segmentation of dynamic scenes remains an underexplored field due to the absence of a sufficiently extensive and accurately labelled multi-view video dataset. In this paper, we present MUVOD, a new multi-view video dataset for training and evaluating object segmentation in reconstructed real-world scenarios. The 17 selected scenes, describing various indoor or outdoor activities, are collected from different sources of datasets originating from various types of camera rigs. Each scene contains a minimum of 9 views and a maximum of 46 views. We provide 7830 RGB images (30 frames per video) with their corresponding segmentation mask in 4D motion, meaning that any object of interest in the scene could be tracked across temporal frames of a given view or across different views belonging to the same camera rig. This dataset, which contains 459 instances of 73 categories, is intended as a basic benchmark for the evaluation of multi-view video segmentation methods. We also present an evaluation metric and a baseline segmentation approach to encourage and evaluate progress in this evolving field. Additionally, we propose a new benchmark for 3D object segmentation task with a subset of annotated multi-view images selected from our MUVOD dataset. This subset contains 50 objects of different conditions in different scenarios, providing a more comprehensive analysis of state-of-the-art 3D object segmentation methods. Our proposed MUVOD dataset is available at https://volumetric-repository.labs.b-com.com/#/muvod.
Intra-Modal Constraint Loss For Image-Text Retrieval
Jul 13, 2022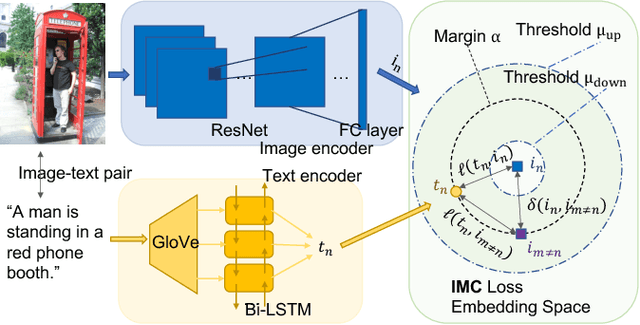
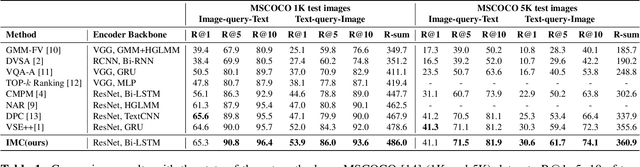
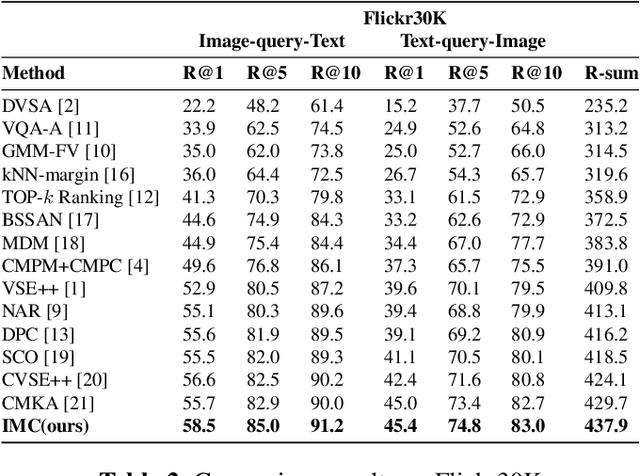
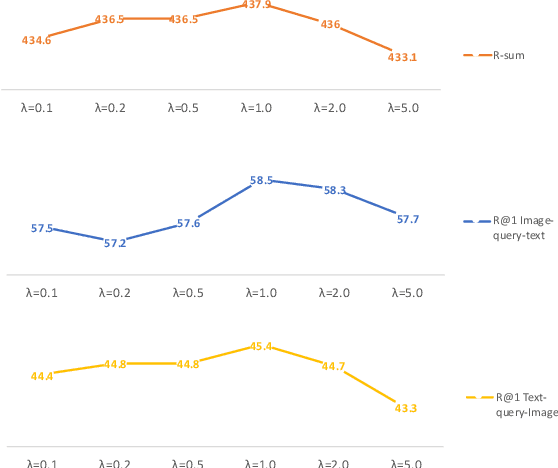
Cross-modal retrieval has drawn much attention in both computer vision and natural language processing domains. With the development of convolutional and recurrent neural networks, the bottleneck of retrieval across image-text modalities is no longer the extraction of image and text features but an efficient loss function learning in embedding space. Many loss functions try to closer pairwise features from heterogeneous modalities. This paper proposes a method for learning joint embedding of images and texts using an intra-modal constraint loss function to reduce the violation of negative pairs from the same homogeneous modality. Experimental results show that our approach outperforms state-of-the-art bi-directional image-text retrieval methods on Flickr30K and Microsoft COCO datasets. Our code is publicly available: https://github.com/CanonChen/IMC.
Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms
Feb 16, 2022
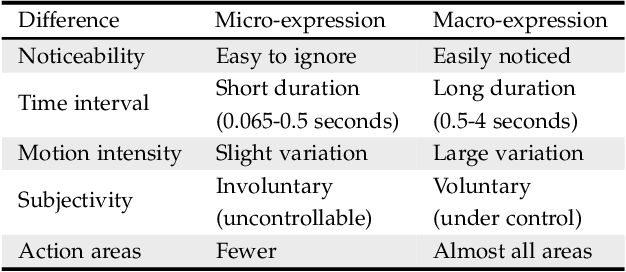
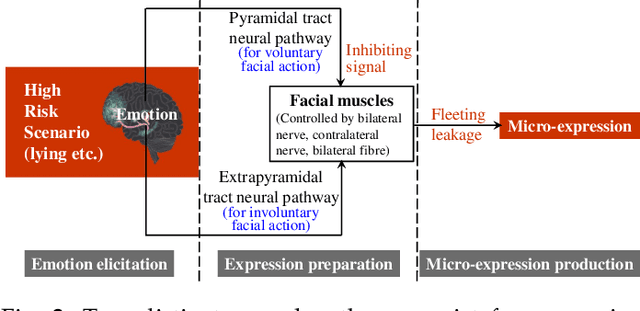
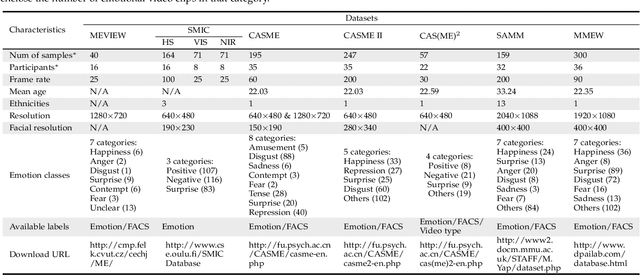
Unlike the conventional facial expressions, micro-expressions are involuntary and transient facial expressions capable of revealing the genuine emotions that people attempt to hide. Therefore, they can provide important information in a broad range of applications such as lie detection, criminal detection, etc. Since micro-expressions are transient and of low intensity, however, their detection and recognition is difficult and relies heavily on expert experiences. Due to its intrinsic particularity and complexity, video-based micro-expression analysis is attractive but challenging, and has recently become an active area of research. Although there have been numerous developments in this area, thus far there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences between macro- and micro-expressions, then use these differences to guide our research survey of video-based micro-expression analysis in a cascaded structure, encompassing the neuropsychological basis, datasets, features, spotting algorithms, recognition algorithms, applications and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are addressed and discussed. Furthermore, after considering the limitations of existing micro-expression datasets, we present and release a new dataset - called micro-and-macro expression warehouse (MMEW) - containing more video samples and more labeled emotion types. We then perform a unified comparison of representative methods on CAS(ME)2 for spotting, and on MMEW and SAMM for recognition, respectively. Finally, some potential future research directions are explored and outlined.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021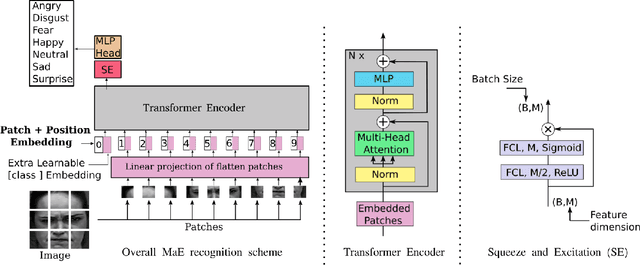
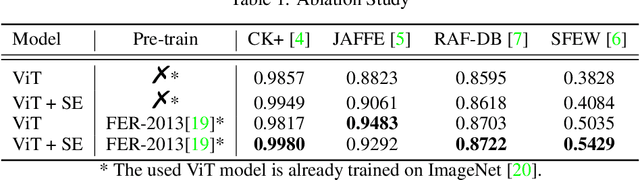
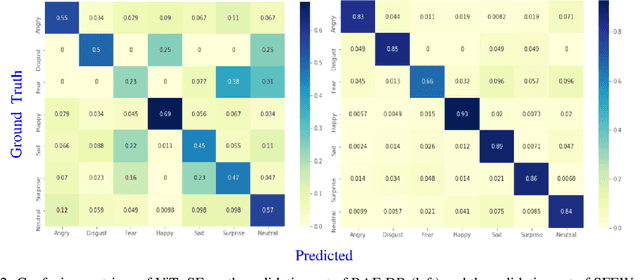
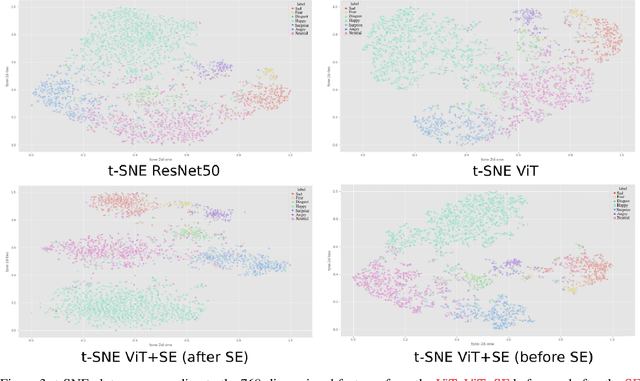
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
Sparse Matrix-based Random Projection for Classification
Oct 12, 2014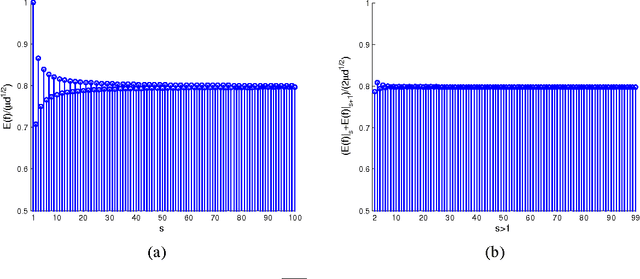
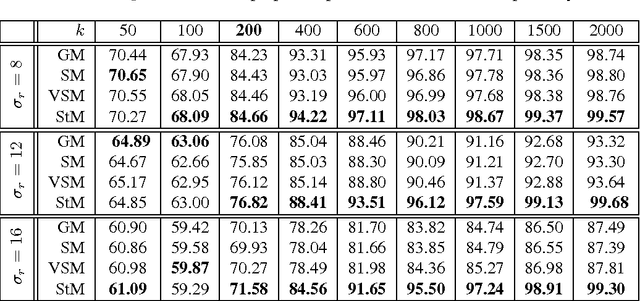
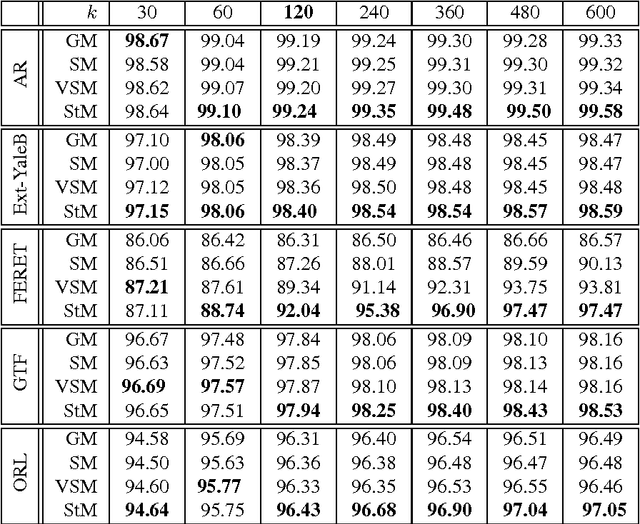
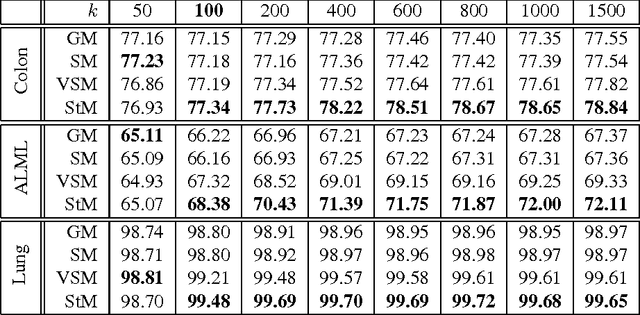
As a typical dimensionality reduction technique, random projection can be simply implemented with linear projection, while maintaining the pairwise distances of high-dimensional data with high probability. Considering this technique is mainly exploited for the task of classification, this paper is developed to study the construction of random matrix from the viewpoint of feature selection, rather than of traditional distance preservation. This yields a somewhat surprising theoretical result, that is, the sparse random matrix with exactly one nonzero element per column, can present better feature selection performance than other more dense matrices, if the projection dimension is sufficiently large (namely, not much smaller than the number of feature elements); otherwise, it will perform comparably to others. For random projection, this theoretical result implies considerable improvement on both complexity and performance, which is widely confirmed with the classification experiments on both synthetic data and real data.