 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
Apr 15, 2024Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the feature along with the occlusion-aware loss functions to better perceive the occluded area. Extensive experiments both in simulated and real-world occlusions, demonstrate that our method achieves comparable or even superior performance compared to the state-of-the-art method. And we improving training and inference speeds by 250x and 800x, respectively. Our code will be available for research purposes.
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Mar 18, 2024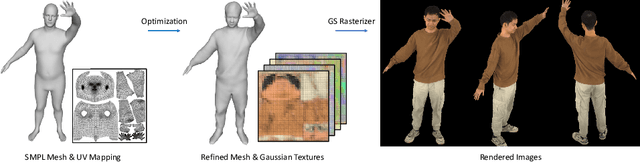

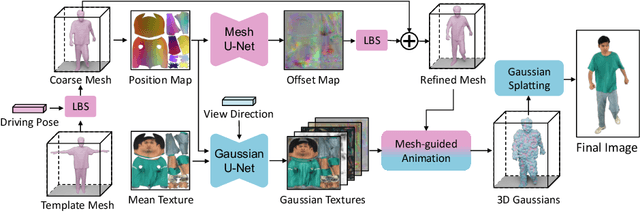

Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
Localization matters too: How localization error affects UAV flight
Mar 07, 2024



The maximum safe flight speed of a Unmanned Aerial Vehicle (UAV) is an important indicator for measuring its efficiency in completing various tasks. This indicator is influenced by numerous parameters such as UAV localization error, perception range, and system latency. However, in terms of localization errors, although there have been many studies dedicated to improving the localization capability of UAVs, there is a lack of quantitative research on their impact on speed. In this work, we model the relationship between various parameters of the UAV and its maximum flight speed. We consider a scenario similar to navigating through dense forests, where the UAV needs to quickly avoid obstacles directly ahead and swiftly reorient after avoidance. Based on this scenario, we studied how parameters such as localization error affect the maximum safe speed during UAV flight, as well as the coupling relationships between these parameters. Furthermore, we validated our model in a simulation environment, and the results showed that the predicted maximum safe speed had an error of less than 20% compared to the test speed. In high-density situations, localization error has a significant impact on the UAV's maximum safe flight speed. This model can help designers utilize more suitable software and hardware to construct a UAV system.
DiffVein: A Unified Diffusion Network for Finger Vein Segmentation and Authentication
Feb 03, 2024Finger vein authentication, recognized for its high security and specificity, has become a focal point in biometric research. Traditional methods predominantly concentrate on vein feature extraction for discriminative modeling, with a limited exploration of generative approaches. Suffering from verification failure, existing methods often fail to obtain authentic vein patterns by segmentation. To fill this gap, we introduce DiffVein, a unified diffusion model-based framework which simultaneously addresses vein segmentation and authentication tasks. DiffVein is composed of two dedicated branches: one for segmentation and the other for denoising. For better feature interaction between these two branches, we introduce two specialized modules to improve their collective performance. The first, a mask condition module, incorporates the semantic information of vein patterns from the segmentation branch into the denoising process. Additionally, we also propose a Semantic Difference Transformer (SD-Former), which employs Fourier-space self-attention and cross-attention modules to extract category embedding before feeding it to the segmentation task. In this way, our framework allows for a dynamic interplay between diffusion and segmentation embeddings, thus vein segmentation and authentication tasks can inform and enhance each other in the joint training. To further optimize our model, we introduce a Fourier-space Structural Similarity (FourierSIM) loss function, which is tailored to improve the denoising network's learning efficacy. Extensive experiments on the USM and THU-MVFV3V datasets substantiates DiffVein's superior performance, setting new benchmarks in both vein segmentation and authentication tasks.
UV-SAM: Adapting Segment Anything Model for Urban Village Identification
Feb 01, 2024



Urban villages, defined as informal residential areas in or around urban centers, are characterized by inadequate infrastructures and poor living conditions, closely related to the Sustainable Development Goals (SDGs) on poverty, adequate housing, and sustainable cities. Traditionally, governments heavily depend on field survey methods to monitor the urban villages, which however are time-consuming, labor-intensive, and possibly delayed. Thanks to widely available and timely updated satellite images, recent studies develop computer vision techniques to detect urban villages efficiently. However, existing studies either focus on simple urban village image classification or fail to provide accurate boundary information. To accurately identify urban village boundaries from satellite images, we harness the power of the vision foundation model and adapt the Segment Anything Model (SAM) to urban village segmentation, named UV-SAM. Specifically, UV-SAM first leverages a small-sized semantic segmentation model to produce mixed prompts for urban villages, including mask, bounding box, and image representations, which are then fed into SAM for fine-grained boundary identification. Extensive experimental results on two datasets in China demonstrate that UV-SAM outperforms existing baselines, and identification results over multiple years show that both the number and area of urban villages are decreasing over time, providing deeper insights into the development trends of urban villages and sheds light on the vision foundation models for sustainable cities. The dataset and codes of this study are available at https://github.com/tsinghua-fib-lab/UV-SAM.
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
Jan 09, 2024



AI agents powered by Large Language Models (LLMs) have made significant advances, enabling them to assist humans in diverse complex tasks and leading to a revolution in human-AI coordination. LLM-powered agents typically require invoking LLM APIs and employing artificially designed complex prompts, which results in high inference latency. While this paradigm works well in scenarios with minimal interactive demands, such as code generation, it is unsuitable for highly interactive and real-time applications, such as gaming. Traditional gaming AI often employs small models or reactive policies, enabling fast inference but offering limited task completion and interaction abilities. In this work, we consider Overcooked as our testbed where players could communicate with natural language and cooperate to serve orders. We propose a Hierarchical Language Agent (HLA) for human-AI coordination that provides both strong reasoning abilities while keeping real-time execution. In particular, HLA adopts a hierarchical framework and comprises three modules: a proficient LLM, referred to as Slow Mind, for intention reasoning and language interaction, a lightweight LLM, referred to as Fast Mind, for generating macro actions, and a reactive policy, referred to as Executor, for transforming macro actions into atomic actions. Human studies show that HLA outperforms other baseline agents, including slow-mind-only agents and fast-mind-only agents, with stronger cooperation abilities, faster responses, and more consistent language communications.
DSR-Diff: Depth Map Super-Resolution with Diffusion Model
Nov 16, 2023



Color-guided depth map super-resolution (CDSR) improve the spatial resolution of a low-quality depth map with the corresponding high-quality color map, benefiting various applications such as 3D reconstruction, virtual reality, and augmented reality. While conventional CDSR methods typically rely on convolutional neural networks or transformers, diffusion models (DMs) have demonstrated notable effectiveness in high-level vision tasks. In this work, we present a novel CDSR paradigm that utilizes a diffusion model within the latent space to generate guidance for depth map super-resolution. The proposed method comprises a guidance generation network (GGN), a depth map super-resolution network (DSRN), and a guidance recovery network (GRN). The GGN is specifically designed to generate the guidance while managing its compactness. Additionally, we integrate a simple but effective feature fusion module and a transformer-style feature extraction module into the DSRN, enabling it to leverage guided priors in the extraction, fusion, and reconstruction of multi-model images. Taking into account both accuracy and efficiency, our proposed method has shown superior performance in extensive experiments when compared to state-of-the-art methods. Our codes will be made available at https://github.com/shiyuan7/DSR-Diff.
Large Language Model-Empowered Agents for Simulating Macroeconomic Activities
Oct 16, 2023

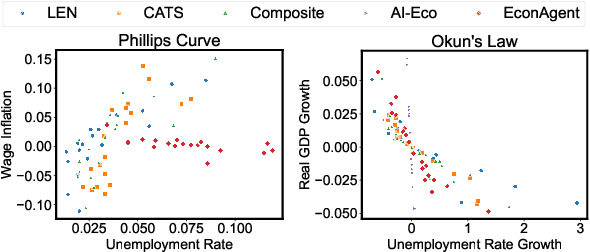
The advent of the Web has brought about a paradigm shift in traditional economics, particularly in the digital economy era, enabling the precise recording and analysis of individual economic behavior. This has led to a growing emphasis on data-driven modeling in macroeconomics. In macroeconomic research, Agent-based modeling (ABM) emerged as an alternative, evolving through rule-based agents, machine learning-enhanced decision-making, and, more recently, advanced AI agents. However, the existing works are suffering from three main challenges when endowing agents with human-like decision-making, including agent heterogeneity, the influence of macroeconomic trends, and multifaceted economic factors. Large language models (LLMs) have recently gained prominence in offering autonomous human-like characteristics. Therefore, leveraging LLMs in macroeconomic simulation presents an opportunity to overcome traditional limitations. In this work, we take an early step in introducing a novel approach that leverages LLMs in macroeconomic simulation. We design prompt-engineering-driven LLM agents to exhibit human-like decision-making and adaptability in the economic environment, with the abilities of perception, reflection, and decision-making to address the abovementioned challenges. Simulation experiments on macroeconomic activities show that LLM-empowered agents can make realistic work and consumption decisions and emerge more reasonable macroeconomic phenomena than existing rule-based or AI agents. Our work demonstrates the promising potential to simulate macroeconomics based on LLM and its human-like characteristics.
Elucidating the solution space of extended reverse-time SDE for diffusion models
Sep 26, 2023



Diffusion models (DMs) demonstrate potent image generation capabilities in various generative modeling tasks. Nevertheless, their primary limitation lies in slow sampling speed, requiring hundreds or thousands of sequential function evaluations through large neural networks to generate high-quality images. Sampling from DMs can be seen alternatively as solving corresponding stochastic differential equations (SDEs) or ordinary differential equations (ODEs). In this work, we formulate the sampling process as an extended reverse-time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and arbitrarily high-order approximate solutions for VP SDE and VE SDE, respectively. Based on the solution space of the ER SDE, we yield mathematical insights elucidating the superior performance of ODE solvers over SDE solvers in terms of fast sampling. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Finally, we devise fast and training-free samplers, ER-SDE-Solvers, achieving state-of-the-art performance across all stochastic samplers. Experimental results demonstrate achieving 3.45 FID in 20 function evaluations and 2.24 FID in 50 function evaluations on the ImageNet $64\times64$ dataset.
CLIP-based Synergistic Knowledge Transfer for Text-based Person Retrieval
Sep 18, 2023



Text-based Person Retrieval aims to retrieve the target person images given a textual query. The primary challenge lies in bridging the substantial gap between vision and language modalities, especially when dealing with limited large-scale datasets. In this paper, we introduce a CLIP-based Synergistic Knowledge Transfer(CSKT) approach for TBPR. Specifically, to explore the CLIP's knowledge on input side, we first propose a Bidirectional Prompts Transferring (BPT) module constructed by text-to-image and image-to-text bidirectional prompts and coupling projections. Secondly, Dual Adapters Transferring (DAT) is designed to transfer knowledge on output side of Multi-Head Self-Attention (MHSA) in vision and language. This synergistic two-way collaborative mechanism promotes the early-stage feature fusion and efficiently exploits the existing knowledge of CLIP. CSKT outperforms the state-of-the-art approaches across three benchmark datasets when the training parameters merely account for 7.4% of the entire model, demonstrating its remarkable efficiency, effectiveness and generalization.